Kudu
现存系统针对结构化数据存储与查询的一些痛点问题,结构化数据的存储,通常包含如下两种方式:
- 静态数据通常以Parquet/Carbon/Avro形式直接存放在HDFS中,吞吐能力大,适合离线分析,随机读写能力差,难以支持单条记录级别的更新。
- 可变数据的存储通常选择面向列族的HBase或者Cassandra,高效随机读写,吞吐能力小,不适合离线分析场景。
Kudu的设计是结合了Hbase的高效随机读写和HDFS高吞吐能力一种折中处理,既能支持OLTP型实时读写能力又能支持OLAP型分析。另外一个初衷Kudu作为一个新的分布式存储系统期望有效提升CPU的使用率,而低CPU使用率恰是HBase/Cassandra等系统的最大问题。

Kudu架构
Kudu采用了Master-Slave主从架构,一个table表会按照主键进行hash/或者range(分区)划分出多个小的tablet(相当于Hbase里的Region),每个小的tablet会对应多个副本(其中1个Leader tablet用于读写,其他的副本为Follower tablet用于只读),这个小的tablet会分到各个Tablet Server 中,这些tablet相关信息存储在Master Server中(1个Leader多个Follower)。
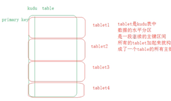
Master Server
1用来存放一些表的Schema信息,且负责处理建表等请求,管理元数据(元数据存储在只有一个tablet的Catalog table中),即tablet与表的基本信息。
2. 跟踪管理集群中的所有的Tablet Server,并且在Tablet Server异常之后协调数据的重部署。
3. 存放Tablet到Tablet Server的部署信息。

其中Catalog Table元数据表,用来存储table(schema、locations、states)与tablet(现有的tablet列表,每个tablet及其副本所处Tablet Server,tablet当前状态以及开始和结束键)的信息。
Tablet Server
存储tablet和为tablet向client提供服务。对于给定的tablet,一个Tablet Server充当leader,其他Tablet Server充当该tablet的follower副本。只有leader服务写请求,leader与follower为每个服务提供读请求。
Tablet与HBase中的Region大致相似,但存在如下一些明显的区别点:
分区策略不一样
Tablet包含两种分区策略,一种是基于Hash Partition方式,在这种分区方式下用户数据可较均匀的分布在各个Tablet中,但原来的数据排序特点已被打乱。另外一种是基于Range Partition(分区)方式,数据将按照用户数据指定的有序的分区键的组合String的顺序进行分区。而HBase中仅仅提供了一种按用户数据RowKey的Range Partition方式。
多副本机制不一样
一个Tablet可以被部署到了多个Tablet Server中,由自己系统管理,不依赖HDFS。在HBase最初的架构中,一个Region只能被部署在一个RegionServer中,它的数据多副本交由HDFS来保障。
数据文件存储结构
具体结构如下
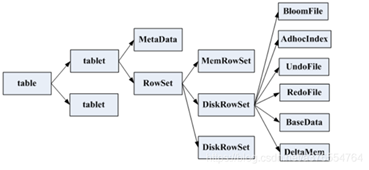
具体如下

数据的读写更操作
不管数据的读写,还是更新操作,其大致都需要先查找我们要的数据的主键所对应的位置,比如下面的写操作
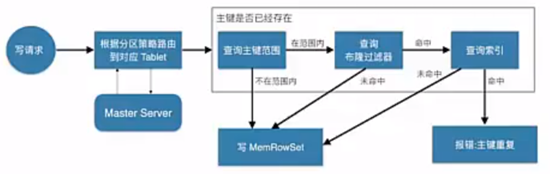
写流程
Client首先连接Master,获取元数据信息。然后连接Tablet Server,查找MemRowSet与DeltMemStore中是否存在相同primary key,如果存在,则报错;如果不存在,则将待插入的数据写入WAL日志,然后将数据写入MemRowSet。
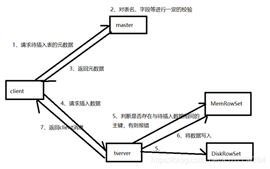
1、client向Master请求预写表的元数据信息
2、Master会进行一定的校验,表是否存在,字段是否存在等
3、如果Master校验通过,则返回表的分区、tablet与其对应的Tablet Server给client;如果校验失败则报错给client。
4、client根据Master返回的元数据信息,将请求发送给tablet对应的Tablet Server.
5、Tablet Server首先会查询内存中MemRowSet与DeltMemStore中是否存在与待插入数据主键相同的数据,如果存在则报错。
6、Tablet Server会讲写请求预写到WAL日志,用来server宕机后的恢复操作
7、将数据写入内存中的MemRowSet中,一旦MemRowSet的大小达到1G或120s后,MemRowSet会flush成一个或DiskRowSet,用来将数据持久化
8、返回client数据处理完毕
更新流程
Client首先向Master请求元数据,然后根据元数据提供的tablet信息,连接Tablet Server,根据数据所处位置的不同,有不同的操作:在内存MemRowSet中的数据,会将更新信息写入数据所在行的mutation链表中;在磁盘中的数据,会将更新信息写入DeltMemStore中。
1、client向Master请求预更新表的元数据,首先Master会校验表是否存在,字段是否存在,如果校验通过则会返回给client表的分区、tablet、tablet所在Tablet Server信息
2、client向Tablet Server发起更新请求
3、将更新操作预写如WAL日志,用来在server宕机后的数据恢复
4、根据Tablet Server中待更新的数据所处位置的不同,有不同的处理方式:
如果数据在内存中,则从MemRowSet中找到数据所处的行,然后在改行的mutation链表中写入更新信息,在MemRowSet flush的时候,将更新合并到baseData中
如果数据在DiskRowSet中,则将更新信息写入DeltMemStore中,DeltMemStore达到一定大小后会flush成DeltFile。
5、更新完毕后返回消息给client。
读流程
客户端将要读取的数据信息发送给Master,Master对其进行一定的校验,比如表是否存在,字段是否存在。Master返回元数据信息给client,然后client与Tablet Server建立连接,通过metaData找到数据所在的RowSet,首先加载内存里面的数据(MemRowSet与DeltMemStore),然后加载磁盘里面的数据,最后返回最终数据给client.

1、客户端Master请求查询表指定数据
2、Master对请求进行校验,校验表是否存在,schema中是否存在指定查询的字段,主键是否存在
3、Master通过查询Catalog Table返回表,将tablet对应的Tablet Server信息、Tablet Server状态等元数据信息返回给client
4、client与Tablet Server建立连接,通过metaData找到primary key对应的RowSet。
5、首先加载RowSet内存中MemRowSet与DeltMemStore中的数据
6、然后加载磁盘中的数据,也就是DiskRowSet中的BaseData与DeltFile中的数据
7、返回数据给Client
8、继续4-7步骤,直到拿到所有数据返回给client
参考