目录
5.5.3 将Hive表中数据进行统计汇总,并导入新的Hive表
第1章 概要介绍
在前几篇文章中,已经顺利将本章离线计算所需要的各种框架部署配置完成(详见笔者之前的文章),接下来本篇文章,开始实现一个业务简单,高可用部署的离线计算。
首先,给自己定了一个简单的需求:实现一个COVID-19(新冠疫情)各地区确诊数量的统计。
其次,明确这次统计的目标:模拟生成每个城市确诊数量的日志,然后将日志采集并上传到大数据集群上、再进行数据统计分析、最后将分析的结果导出到关系型数据库中。
然后,再做一个简单的概要设计:
- 通过一个简单的web项目生成日志在应用服务器上,web项目docker打包部署,日志映射到本机;
- 通过Flume将日志采集到HDFS上,Flume部署多台机器,采用负载均衡和故障转移模式;由于采集的日志信息并不是我们想要的格式(生产环境中可能五花八门),所以这里我们写一个Flume的拦截器,来对日志信息进行过滤,过滤后的数据再上传到HDFS;
- 预先创建好Azkaban调度计划,并创建3个作业,在每天的固定时段进行执行,作业具体情况如下:
- 通过Azkaban调度任务执行Hive命令,将HDFS上的数据设置Hive分区,以达到将数据导入Hive表的目的;
- 通过Azkaban调度任务执行Hive命令,将数据进行统计汇总,并将统计结果写入到新的Hive表中;
- 通过Azkaban调度任务执行Sqoop命令,将Hive上的数据导出到关系型数据库中。
数据经过一系列的处理,最终将分析结果最终导出到了我们熟悉的关系型数据库中,就可以直接供业务系统使用了。
第2章 集群规划
2.1 各机器安装部署概况
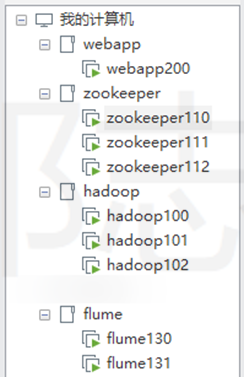
webapp200:docker(运行web应用)、web应用、flume(采集日志)、mysql(笔者电脑资源有限,hive元数据、azkaban元数据、最终的分析结果都用这个mysql)
flume130、flume131:flume(上传日志数据到HDFS)
zookeeper110、zookeeper111、zookeeper112:zookeeper(namenode、resourcemanager高可用)
hadoop100:hadoop、hive(metastore、client)、sqoop、azkaban(exec-server)
hadoop101:hadoop、hive(metastore、client)、sqoop、azkaban(exec-server)
hadoop102:hadoop、hive(client)(这里的hive没有用到)、sqoop、azkaban(web-server)
说明:笔者所有的机器都配置了host文件,主机名与机器命名一致。
2.2 各机器上组件部署及进程运行情况
Flume集群,Agent三个重要组件的type部署情况(其中WebApp200为应用产生日志服务器)
|
|
Webapp200 |
Flume130 |
Flume131 |
| sources |
TAILDIR |
avro |
avro |
| channels |
file |
file |
file |
| sinks |
avro |
hdfs |
hdfs |
Zookeeper集群
|
|
Zookeeper110 |
Zookeeper111 |
Zookeeper112 |
| QuorumPeerMain |
√ |
√ |
√ |
Hadoop集群,各组件运行位置
|
|
Hadoop100 |
Hadoop101 |
Hadoop102 |
| NameNode |
√ |
√ |
|
| DataNode |
√ |
√ |
√ |
| DFSZKFailoverController |
√ |
√ |
|
| JournalNode |
√ |
√ |
√ |
| ResourceManager |
|
√ |
√ |
| NodeManager |
√ |
√ |
√ |
| Hive metastore/Client |
√ |
√ |
|
| Sqoop |
√ |
√ |
|
| Azkaban exec-server |
√ |
√ |
|
| Azkaban web-server |
|
|
√ |
MySQL,一共建立了3各数据库(笔者这里mysql装在webapp200这台机器上)
|
|
Webapp200 |
| Hive元数据 |
√ |
| Azkaban元数据 |
√ |
| 离线计算结果 |
√ |
第3章 流程设计

通过这个流程图,可以简单的看到数据整体流向,和各框架组件、进程运行的位置。生产环境中不一定是将各个框架部署到不同的机器,有些环境同一台机器可能运行着多种框架;根据自己的业务情况,数据量,搭建不同的环境、部署不同的机器数量;当然也要考虑成本,不要盲目的添加服务器,有写情况可以考虑先在现有机器上安装部署,后续再进行迁移。也不要盲目的照搬他人的架构部署体系,每个人每家公司所做的产品、服务的对象、面向的群体都不一定相同。要做适合自己产品的部署才是重点。
大数据系统相对于其他系统,需要的资源会多一些,数据量是实实在在的摆在眼前,很多时候不一定能够及时的扩充到想要达到的资源条件(特别是中小企业),这是个普遍的现象,作为公司的一员,不要盲目的抱怨公司没有给予资源上支持,先考虑一下自己有没有创造出有效成果。技术永远不是单纯的技术,技术要服务于社会,创造出成绩才有它所存在的意义,也才能发挥技术真正的价值。
笔者这里非生产环境,资源不是特别充足,mysql统一部署在一台机上,这里mysql任然存在单点故障问题,生产环境可以用多台机器做主备模式的部署。另外补充一点:生产环境建议在Flume环节添加kafka来增加吞吐量。
第4章 准备工作
安装部署好所有框架,并启动,详见我的前几篇文章(包含本文用到的所有框架的完整安装部署)。
4.1 建立Hive表
建立hive表t_infectcount,用于存放新冠病毒各地区感染明细数据。
CREATE EXTERNAL TABLE IF NOT EXISTS t_infectcount(
infectdate date,
infectcountry string,
infectarea string
)
partitioned by (partdate string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
LOCATION '/user/hive/warehouse/covid19count.db/t_infectcount';建立hive表t_ infectstatistics,用于存放新冠病毒各地区确诊数量汇总后的数据。
CREATE TABLE IF NOT EXISTS t_infectstatistics(
id int,
country string,
area string,
count int
)
partitioned by (cty string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n';4.2 建立MySQL表
建立Mysql表t_infectstatistics,用于存放最终统计的结果。
CREATE TABLE IF NOT EXISTS t_infectstatistics (
id int AUTO_INCREMENT NOT NULL,
country varchar(100) DEFAULT '',
area varchar(100) DEFAULT '',
count int DEFAULT '0',
PRIMARY KEY (id)
);第5章 具体步骤
5.1 生成应用日志

做了一个简单的web应用,输入文本,直接生成日志信息:被一笔日志代表一个新冠病毒确诊数量。开启日志服务后,将不断的在webapp200机器上产生应用日志。
5.2 Flume采集日志
将运行在docker中的webapp产生的日志信息挂载到宿主机上。供flume采集(webapp200上的flume)。详见我之前的文章:大数据实操篇 No.4-Flume集群搭建,这里不细述。
5.3 Flume拦截器过滤日志
上传hdfs之前,在flume130和flume131上实现一个自定义拦截器,以过滤并整理日志信息数据。
新建一个Maven项目,在pom.xml添加flume依赖
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
</dependency>建立class继承Interceptor接口,实现intercept方法即可,代码如下:
package com.lotemall.interceptor;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
public class LogFormatInterceptor implements Interceptor {
public void initialize() {
}
public Event intercept(Event event) {
/**
* 实现自己对event的逻辑处理,最终返回event(本方法内容仅供参考)。
*/
if (event == null) return null;
Map<String, String> headers = event.getHeaders();
String body = new String(event.getBody());
if (body.indexOf("content:{") <= 0) return null;
String date = body.substring(0, 10);
String country = body.substring(body.indexOf("country") + 10, body.indexOf("area") - 3);
String area = body.substring(body.indexOf("area") + 7, body.length() - 2);
event.setBody(String.format("%s,%s,%s", date, country, area).getBytes());
return event;
}
public List<Event> intercept(List<Event> list) {
List<Event> lst = new ArrayList<Event>();
Iterator<Event> it = list.iterator();
while (it.hasNext()) {
Event event = it.next();
Event eventSingle = intercept(event);
if (eventSingle != null) {
lst.add(eventSingle);
}
}
return lst;
}
public void close() {
}
public static class Builder implements Interceptor.Builder{
public Interceptor build() {
return new LogFormatInterceptor();
}
public void configure(Context context) {
}
}
}打包成jar包放置flume的lib目录下,并修改Agent配置文件,添加拦截器内容:
#Interceptor
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.lotemall.interceptor.LogFormatInterceptor$Builder
5.4 Flume上传数据到HDFS
Flume配置好后,当webapp200上的日志发生变化时,Flume将自动采集上传数据到HDFS上。(Flume的部署配置详见我之前的文章:大数据实操篇 No.4-Flume集群搭建)
5.5 Azkaban调度计划
Azkaban集群部署详见我之前的文章:大数据实操篇 No.7-Azkaban HA高可用集群部署,这里不再细述。
5.5.1 Azkaban调度任务一共执行3个job
hdfs2hive:将HDFS上的新冠病毒确诊数据导入到HIVE表;
hive2hive:将HIVE表里的新冠病毒确诊数据进行汇总统计,并导入到新的HIVE表;
hive2mysql:将HIVE表里的统计数据,导出到MySQL中。

5.5.2 将HDFS数据导入Hive表
Hive的部署请参照我之前的文章:大数据实操篇 No.5-Hive 高可用方式集群部署,这里不再细述。
通过Azkaban调度任务执行Hive分区命令将数据导入Hive表
hdfs2hive.job作业文件:
type=command
command=sh hdfs2hive.shhdfs2hive.sh文件:
#!/bin/bash
# 执行hive命令,添加表分区,以导入hdfs文件到hive分区
# 每小时30分执行
cur_datetime=$(date +%Y%m%d%H)
hive -e "use covid19count;alter table t_infectcount add if not exists partition (partdate = '${cur_datetime}');"
5.5.3 将Hive表中数据进行统计汇总,并导入新的Hive表
通过Azkaban调度任务执行Hive命令,统计原表t_infectcount中的数据结果,插入到新表t_ infectstatistics中
hive2hive.job文件:
type=command
command=sh hive2hive.sh
dependencies=hdfs2hivehive2hive.sh文件:
#!/bin/bash
# 计算:汇总统计各国家区域的数量
hive -f /opt/shell/covid19/statistics.hql >> /opt/shell/covid19/execresult/statistics.txtstatistics.hql文件:
-- 指定数据库
use covid19count;
-- 清空统计表
truncate table t_infectstatistics;
-- 插入最新统计数据
-- 开启动态分区,默认是false
set hive.exec.dynamic.partition=true;
-- 开启允许所有分区都是动态的,否则必须要有静态分区才能使用。
set hive.exec.dynamic.partition.mode=nonstrict;
-- 插入数据 指定列进行插入 partition默认select语句最末尾的列
insert into t_infectstatistics partition(cty) (id,country,area,count,cty)
select row_number() over (order by infectcountry,infectarea asc),infectcountry,infectarea,count(1),infectcountry
from t_infectcount
group by infectcountry,infectarea;5.5.4 将Hive表中的统计数据导出到MySQL
通过调用Sqoop,将数据导出到MySQL数据库的t_infectstatistics表中
hive2mysql.job文件:
type=command
command=sh hive2mysql.sh
dependencies=hive2hivehive2mysql.sh文件:
#!/bin/bash
# 执行sqoop命令 将数据从hive表里导入到mysql
sqoop --options-file /opt/shell/covid19/exportdata.opt >> /opt/shell/covid19/execresult/exportdata.txtexportdata.opt文件:
export
--connect
jdbc:mysql://webapp200:3306/offline
--username
root
--password
Db@123456
--table
t_infectstatistics
--columns
id,country,area,count
--num-mappers
1
--export-dir
/user/hive/warehouse/covid19count.db/t_infectstatistics/cty=china
--input-fields-terminated-by
","
--update-mode
allowinsert
--update-key
country,area第6章 实际执行数据情况
6.1 Hive中提前定义的2个表
准备工作中提前建立的2个Hive表,数据上传到HDFS后,会在以下这2个Hive表里进行存储:
- t_infectcount是数据上传到HDFS的路径,同时也是分区命令导入的Hive表。
- t_infectstatistics是Hive分析结果表,通过Hive命令统计分析后的结果存在这个表里,此表按小时进行分区。

6.2 Webapp200产生的日志
这是我在机器上产生的日志信息,可以看到日志信息很长,只有末尾一部分JSON是我需要采集的数据。

6.3 Flume传入到HDFS中数据
日志通过Flume采集后,上传到HDFS上,注意上传到HDFS上的数据是经过拦截器过滤后的数据,也就是只取了后面的json数据,然后处理成逗号间隔的csv格式的数据。

6.4 统计分析前的数据
这里Flume采集上传到HDFS上的数据

6.5 Azkaban中的作业
Azkaban中创建3个任务作业,对应“第1章 概要介绍”中描述的内容。
通过这3个作业,对上传到HDFS上的数据集进行分析处理。

6.6 统计后的Hive表分区
Azkaban作业执行完成后,也就是统计后的数据,会写入按城市分区的Hive表中,(笔者这里模拟的都是china的新冠病毒,所以这里暂时只创建了一个分区)

6.7 统计后的数据
这里是经过Hive统计分析后的HDFS上的数据

第7章 查看数据分析执行结果
7.1 Azkaban中设定的执行计划
设定好的执行计划,让作业定时执行。

7.2 Azkaban中正在执行的任务
运行中的执行计划。

7.3 Azkaban任务执行情况查看
计划运行完成后,在History中可以查看到执行计划执行成功(Success)

7.4 Yarn集群任务执行情况
同样我们可以到Yarn集群管理的界面查看任务执行情况,同样都顺利执行完成(SUCCESS)

7.5 最终将数据分析结果写入MySQL
Azkaban任务计划中的最后一步,就是采用Sqoop将数据导入到我们平常使用的关系型数据库MySQL中。这里可以查看到分析结果已经顺利的导入到MySQL中。

至此,已将COVID-19(新冠疫情)各地区确诊数量进行分析汇总,并将汇总结果写入到MySQL中,供其他应用和系统进行调用。