什么是联合索引?
MySQL可以使用多个字段同时建立一个索引,叫做联合索引:如下:
CREATE INDEX INDEX_NAME ON TABLE_NAME(a,b,c)这个联合索引实际上效果等同于创建了索引a,索引(a,b),索引(a,b,c)这三个索引。因此联合索引更节约空间。
如果是创建完表之后添加索引,那么可以:
ALTER TABLE `table_name` ADD INDEX index_name ( `a`, `b`, `c` )也可以在创建表的时候这样:
CREATE TABLE T{
a INT,
b INT,
PRIMARY KEY (a),
KEY idx_a_b (a,b)
}ENGINE=INNODB
联合索引的本质
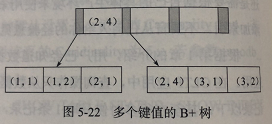
联合索引本质上来说也是一个B+树,但是不同的是,以前的B+树的键值数量是1(即一个键值+一个页指针),但是联合索引的键值数量是大于等于2。如果根据上面创建表的语句,可以得到下图的B+树,也就是说,数据按照a,b的顺序来进行排序的,即先按照a排,再按照b排:
联合索引的作用
作用1、在如下这种查询中,我们可以提前创建一个联合索引,提高查询效率:
select * FROM TABLE WHERE a=** and b=**,我们就可以使用(a,b)联合索引来进行查询。
对于单个列a也可以使用,但是只对于b 的查询不可以,因为之前说的,我们是先对a排序,再对b排序,单独看b 的话,都是乱的,比如上面的1,2,1,4,1,2。这个其实就是我们经常说的“最左原则”。本质就是因为B+树里面的排序是先排a,再排b。
作用2、第二个好处是,联合索引它内部已经对第二个键值进行了排序处理(就像上面说的,首先对a排序,然后对b排序),很多情况下我们要查询某个用户的购物情况,然后按照时间排序,然后取出前3次的记录,这个时候使用联合索引就可以节约一次“排序操作”(filesort),因为在叶子节点上都已经排好序了。创建了联合索引(a,b),就可以这样直接使用联合索引查询:
SELECT ,,FROM TABLE WHERE a=** ORDER BY b;
如果对于联合索引(a,b,c)来说,我们也可以这样使用:
SELECT ,,FROM TABLE WHERE a=** ORDER BY b;
SELECT ,,FROM TABLE WHERE a=**AND b=*** ORDER BY c;
比如我们在表上创建了两个索引KEY(userid) KEY(userid,buy_date),这两个索引都包含了userid(不是主键),执行
SELECT * FROM TABLE WHERE userid=2;我们可以看到执行计划为:

也即是说有两个索引可用,但是优化器选择了索引userid,因为这个索引的叶子节点只包含一个键值,一页可以存放的记录更多。
但是 如果执行:
SELECT * FROM TABLE WHERE userid=1 ORDER BY buy_date limit 10;执行计划如下:

可以发现,这次优化器使用了联合索引,因为在联合索引里面,已经按照buy_date排序了,因此无需进行一次额外的排序操作。
最左原则
MySQL使用索引时需要索引有序,假设现在建立了"name,age,school"的联合索引,那么索引的排序为: 先按照name排序,如果name相同,则按照age排序,如果age的值也相等,则按照school进行排序。
当进行查询时,此时索引仅仅按照name严格有序,因此必须首先使用name字段进行等值查询,之后对于匹配到的列而言,其按照age字段严格有序,此时可以使用age字段用做索引查找,,,以此类推.因此在建立联合索引的时候应该注意索引列的顺序,一般情况下,将查询需求频繁或者字段选择性高的列放在前面.此外可以根据特例的查询或者表结构进行单独的调整。
此外,MySQL会一直向右匹配直到遇到范围查询。如有索引 (a,b,c,d),查询条件 a=1 and b=2 and c>3 and d=4,则会在每个节点依次命中a、b、c,无法命中d。