目录
索引使用(下)
覆盖索引与回表查询
覆盖索引是指查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到 。
我们一起先看下面的这组SQL的执行过程,对覆盖索引与回表查询进行更深入的了解。
表结构以及索引示意图:

id是主键,是一个聚集索引。 name字段建立了普通索引,是一个二级索引(辅助索引)。
执行SQL :
select * from tb_user where id = 2;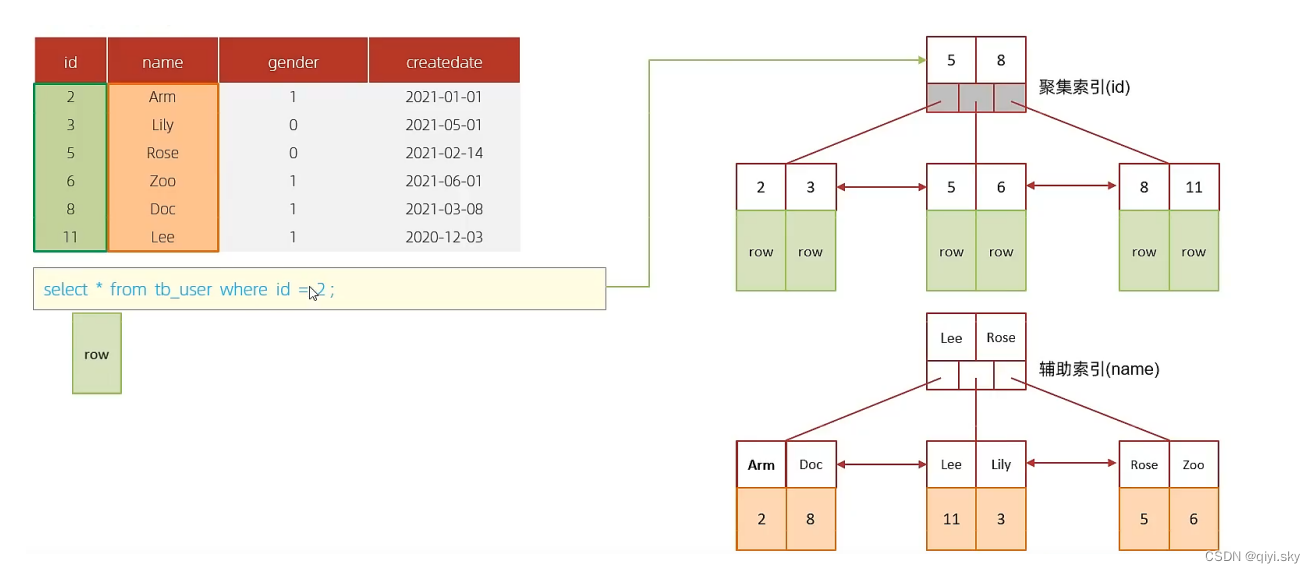 根据id查询,直接走聚集索引查询,一次索引扫描,匹配到id为2,因为聚集索引中叶子节点下面放的是行数据,所以可以得到我们想要的数据,直接返回数据,性能高。
根据id查询,直接走聚集索引查询,一次索引扫描,匹配到id为2,因为聚集索引中叶子节点下面放的是行数据,所以可以得到我们想要的数据,直接返回数据,性能高。
再来看,
执行SQL:
selet id,name from tb_user where name = 'Arm';
虽然是根据name字段查询,查询二级索引,但是由于查询返回在字段为 id,name,在name的二级索引中,这两个值都是可以直接获取到的,这个就实现了覆盖索引,所以不需要回表查询,性能高。
最后看,
执行SQL:
selet id,name,gender from tb_user where name = 'Arm';
由于在name的二级索引中,不包含gender,所以,需要两次索引扫描,也就是需要回表查询,性能相对较差一点。
我们可以看MySQL的执行计划,有些SQL语句的执行计划前面所有的指标都是一样的,看不出来差异。但是,我们要关注其后面的Extra:
| Extra | 含义 |
|---|---|
| Using where; Using Index | 查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查询数据 |
| Using index condition | 查找使用了索引,但是需要回表查询数据 |
所以在执行计划中,如果Extra为‘Using index condition’,那么就可能需要对其做一些修改优化了。
思考题
一张表, 有四个字段(id, username, password, status), 由于数据量大, 需要对
以下SQL语句进行优化, 该如何进行才是最优方案:select id,username,password from tb_user where username = 'itcast';
答案:针对于 username, password建立联合索引,
sql为: create index idx_user_name_pass on tb_user(username,password);
这样可以避免上述的SQL语句,在查询的过程中,出现回表查询。
前缀索引
当字段类型为字符串(varchar,text,longtext等)时,有时候需要索引很长的字符串,这会让
索引变得很大,查询时,浪费大量的磁盘IO, 影响查询效率。
此时可以只将字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率。
语法
create index idx_xxxx on table_name( column(n) );示例
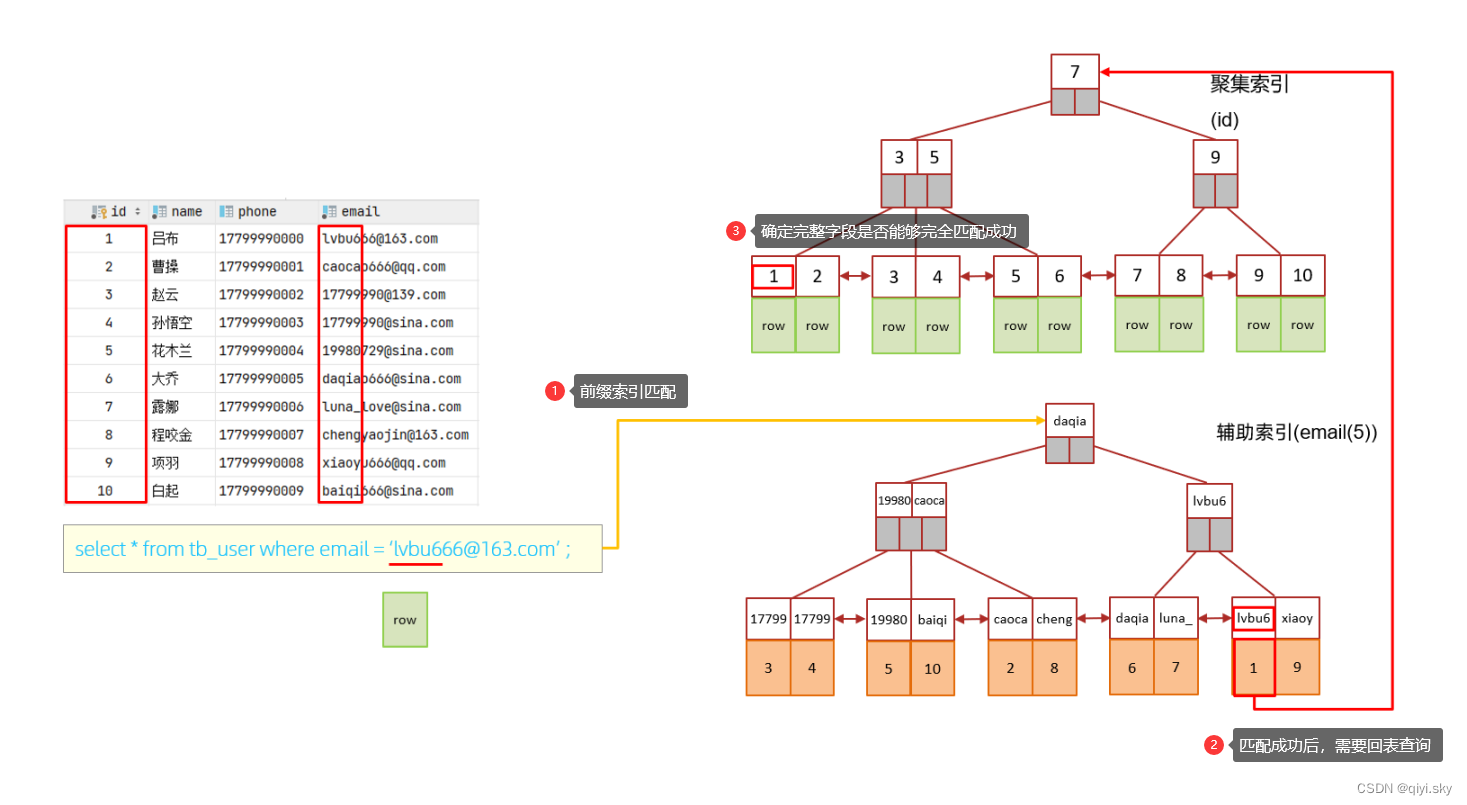
为tb_user表的email字段,建立长度为5的前缀索引。
create index idx_email_5 on tb_user ( email(5) );
前缀长度
可以根据索引的选择性来决定,而选择性是指不重复的索引值(基数)和数据表的记录总数的比值,索引选择性越高则查询效率越高, 唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
select count(distinct email) / count(*) from tb_user ;
select count(distinct substring(email,1,5)) / count(*) from tb_user ;前缀索引的查询流程
单列索引与联合索引
单列索引:即一个索引只包含单个列。
联合索引:即一个索引包含了多个列。
执行计划中,如果两个字段 phone、name上都是单列索引的,但是最终MySQL只会选择一个索引,也就是说,只能走一个字段的索引,此时是会回表查询的。
在业务场景中,如果存在多个查询条件,考虑针对于查询字段建立索引时,建议建立联合索引,
而非单列索引。
索引设计原则
- 针对于数据量较大,且查询比较频繁的表建立索引。
- 针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引。
- 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高。
- 如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引。
- 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率。
- 要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。
- 如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询。
索引总结
1.索引概述
索引是高效获取数据的数据结构。
2.索引结构
B+Tree
Hash
3.索引分类
主键索引、唯一索引、常规索引、全文索引、聚集索引、二级索引。
4.索引语法
create [unique] index xxx on xxx(xxx);
show index from xxxx;
drop index xxx on xxxx;
5.SQL性能分析
执行频次、慢查询日志、profile、explain。
6.索引使用
联合索引、索引失效、SQL提示、覆盖索引、前缀索引、单列/联合索引。
7.索引设计原则
表、字段、索引。
END
学习自:黑马程序员——MySQL数据库课程