本篇文章是对自己学习的一个总结,主要学习资料是JSP&Servlet学习笔记(第三版),林信良著,清华大学出版社出版。
这篇文章里提过,Servlet本质上是一个Java对象。http(超文本协议)请求一定是要经过HTTP服务器处理的,而超文本协议的内容基本都是文本字符串的形式(如下图)
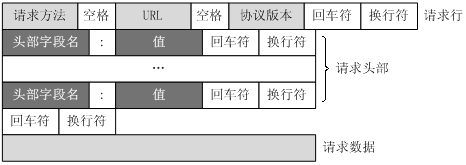
http协议的各种信息包含在这样的一个结构体当中。如果我们只是用JavaSE来处理http请求,这当然可以实现,但是也可以想象工作过程有多繁琐。同时http是无状态的协议,直接使用JavaSE处理http请求的话,我们还得负责对象的生命周期管理。
上面只是简单说了http直接用JavaSE处理的话又多麻烦,事实上繁琐的点不止是这些。
幸运的是,我们有容器技术。容器是运行在http服务器之上的。容器接收到http请求,然后替我们整理其中的信息并转换成一个个Java对象,这样我们就可以使用这些对象的getXXX()方法很快捷地获取到我们想要的信息。同时容器也帮我们管理着这些对象的生命周期。
综上所述,容器让我们开发web时能专注于处理信息而不是解析信息。

容器将http请求信息和响应信息转换成了Java对象,这两个对象分别是HttpServletRequest和HttpServletResponse。而负责处理请求的对象是HttpServlet。Java规定了这个对象的关系,关系如下图所示

从继承架构上看,HttpServlet继承Servlet。这样的设计是因为当初设计Servlet时,是希望Servlet不止是应用在Http之中,所以关于网络的的基本规范是定义在Servlet中,而关于Http的相关行为则是定义在HttpServlet。
同时Servlet和HttpServlet的依赖对象也是基于上面所述的原因设计成如今的继承架构。ServletRequest和ServletResponse定义了请求和响应的普遍行为,而HttpServletRequest和HttpServletResponse定义了Http相关的请求和响应。
下面说一下HttpServletRequest和HttpServletResponse。
HttpServletRequest
通过HttpServletRequest可以获取到很多信息,包括网页传到服务器的参数,网页本身配置信息(比如浏览器信息)。下面简单讲解一下获取这些数据的方法
-
获取请求参数
获取请求参数的方法可以看Orcale的文档,主要就是这几个方法。
getAttrbute等系列方法和getParameter等系列方法。两者的区别就是前者用于处理对象,而后者用于处理键值对。
-
获取请求标头
获取请求标头主要就是下面的这三个方法
getHeader(),getHeaders(),getHeaderNames()。三者的用法看API文档即可。
值得一说的是,getHeaderNames()这个方法,获取所有的Header Name。和请求参数中的getAttributeNames一样,这个方法返回类型的是Enumeration
 Enumeraiton类比较古老,该方法已经被Iterator取代。
Enumeraiton类比较古老,该方法已经被Iterator取代。
这里就简单介绍一下Enumeration的用法。
我们可以用Collections.list()来将Enumeration转换为ArrayList来使用,比如下面的代码。
Collecitons.list(request.getHeaderNames())
.foreach(name -> (
System.out.print(name + request.getHeader(name));另外,如果请求标头的值是int型或Date型,那么还可以用getIntHeader()和getDateHeader方法直接获取到int或Date的值。但如果标头值无法转换成对应类型的话,会抛出异常。
下面说说,处理标头时,常见的一些问题。
-
参数编码
在中文世界里,计算机总是会遇到编码问题。网页若使用UTR-8传中文,而容器却使用其他字符集接收中文,那就很可能出现乱码问题。总之,网页使用的字符集和容器使用的字符集不一致的话,就可能出现乱码问题。
http协议中,关于使用的字符集信息是存储在标头content-type之中,比如。当然,content-type标头作为MIME类型,它不止是指明了http中body的编码方法,也指明了当前网络资源属于什么型(text,html等)。这里我们只是先强调content-type中设置编码方式。![]()
HttpServletRequest中有获取到编码方式可以有下面三种方法
- getContentType():获取到的不止是编码方式,
- getHeader("content-type"):和getContentType一样。
- getCharacterEncoding():直接获取到编码方式。
因为content-type中包含的不止是编码方式的信息,所以如果我们只想要处理编码方式的话,最好还是直接使用getCharacterEncoding()方法最好。
文档中关于getCharacterEncoding()的描述如下所示

从描述中可以看出,如果网页没有在content-type中指明字符编码信息的话,getCharacterEncoding()会返回null(content-type没有指明的话,使用getContentType()也是会返回null)。下面是网页没有指明编码方式的情况下的实验结果。
