Python爬虫bs4模块的讲解
前言
这篇文章是小编通过自学和看过的一些相关书籍学到的知识点,也许讲到的知识点不够全面,希望读者能够谅解!同时,如果读者觉得我的这篇还行,记得在文章下面点一个小小的赞!如果还有一些知识点没有讲到,也欢迎读者在评论区留言。
1.了解bs4模块的三种的选择器
bs4模块在对于爬取得到的数据进行解析,有三种选择器,也就是下面的这三种,它们分别是CSS选择器、方法选择器、节点选择器。这里,小编先从CSS选择器讲起。
首先,先导入bs4模块
from bs4 import BeautifulSoup
2.CSS选择器
1.嵌套选择
如我要解析QQ音乐的歌词(这个歌词是直接爬取是爬不到的,我这只是拿这个举例,如果想爬取这个的读者可以看看我的这篇文章,解决Python爬虫爬不到数据),我选择了一段字符串如下:
str_1='''<div class="lyric__cont_box" id="lrc_content"><p>
</p><p>
</p><p>
</p><p>
</p><p>
</p><p>我的梦 (Dream It Possible) - 张靓颖 (Jane Zhang)
</p><p>词:王海涛/张靓颖
</p><p>曲:Andy Love
</p><p>编曲:崔迪
</p><p>一直地一直地往前走
</p><p>
</p><p>疯狂的世界
</p><p>
</p><p>迎着痛把眼中所有梦
</p><p>
</p><p>都交给时间
</p><p>
</p><p>想飞就用心地去飞
</p><p>谁不经历狼狈
</p><p>
</p><p>我想我会忽略失望的灰
</p><p>拥抱遗憾的美
</p><p>我的梦说别停留等待
</p><p>就让光芒折射泪湿的瞳孔
</p><p>映出心中最想拥有的彩虹
</p><p>带我奔向那片有你的天空
</p><p>因为你是我的梦
</p><p>
</p><p>我的梦
</p><p>
</p><p>执着地勇敢地不回头
</p><p>
</p><p>穿过了黑夜踏过了边界
</p><p>路过雨路过风往前冲
</p><p>
</p><p>总会有一天站在你身边
</p><p>泪就让它往下坠
</p><p>溅起伤口的美
</p><p>
</p><p>哦别以为失去的最宝贵
</p><p>才让今天浪费
</p><p>我的梦说别停留等待
</p><p>就让光芒折射泪湿的瞳孔
</p><p>映出心中最想拥有的彩虹
</p><p>带我奔向那片有你的天空
</p><p>因为你是我的梦
</p><p>
</p><p>我的梦
</p><p>
</p><p>我的梦
</p><p>
</p><p>我的梦
</p><p>
</p><p>世界会怎么变化
</p><p>都不是意外
</p><p>记得用心去回答
</p><p>命运的精彩
</p><p>世界会怎么变化
</p><p>都离不开爱
</p><p>记得成长的对话
</p><p>
</p><p>勇敢地说我不再等待
</p><p>就让光芒折射泪湿的瞳孔
</p><p>映出心中最想拥有的彩虹
</p><p>带我奔向那片有你的天空
</p><p>因为你是我的梦
</p><p>
</p><p>我的梦
</p><p>
</p><p>我的梦
</p><p>因为你是我的梦</p></div>'''
不用嵌套如下:
soup=BeautifulSoup(str_1,'lxml')
print(soup.select('div.lyric__cont_box>p'))
其中 **"."**代表的是 类选择器,当然,也可以用到 id选择器 ,将 “.lyric__cont_box” 改成 “#lrc_content” 即可,不懂的读者可以看看上面的那个字符串。另外, “>” 表示当前节点的下一个节点,也可以用英文的空格代替。

嵌套如下:
soup=BeautifulSoup(str_1,'lxml')
s_2=soup.select('div.lyric__cont_box')
for s_3 in s_2:
print(s_3.select('p'))
运行结果跟上面相同。这样看起来用嵌套相比较不用嵌套还麻烦一些,但是有个时候两者相比前者还是优于后者,这要看具体情况。所谓“具体情况,具体分析”吗?
2.获取文本
怎样才能得到里面的歌词呢?可以用到 .get_text() 或者 .string ,两者均可。
soup=BeautifulSoup(str_1,'lxml')
s_2=soup.select('div.lyric__cont_box>p')
for s_3 in s_2:
if s_3.get_text()=='\n':
continue
print(s_3.get_text())
#print(s_3.string)
运行结果:
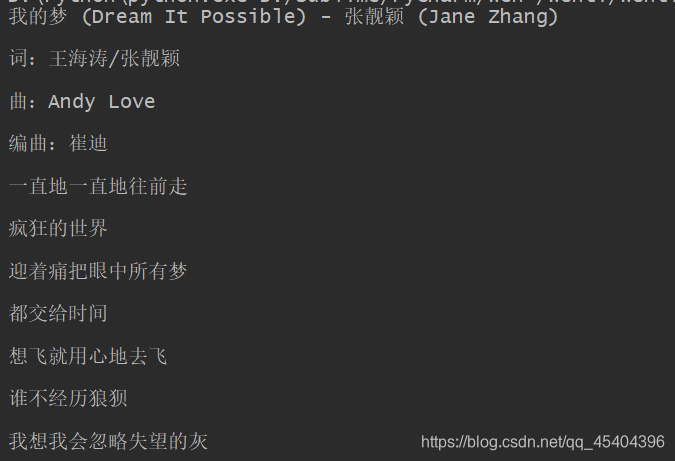
3.获取属性
str_1='''
<ul>
<li class="li_1" title="三国演义">罗贯中</li>
<li class="li_2" title="西游记" >施耐庵</li>
</ul>'''
如现在我想得到两个li标签里面的title属性名,也就是 三国演义和 西游记。
soup=BeautifulSoup(str_1,'lxml')
s_2=soup.select('ul>li')
print(s_2)

这样只能得到一个列表,并且没有得到理想的结果。
过去,常常有这样写的,当然,我曾经也是这样,哈哈,如下
soup=BeautifulSoup(str_1,'lxml')
s_2=soup.select('ul>li')
print(s_2['title'])
结果这当然是报错啊,要知道此时的s_2是一个列表,并不是一个 <class ‘bs4.element.Tag’> ,所以这里要应用到一个循环。
soup=BeautifulSoup(str_1,'lxml')
s_2=soup.select('ul>li')
for s_3 in s_2:
print(s_3['title'])

4. 标签里面没有class也没有id
有一些标签里面既没有class属性,也没有id属性 ,并且这样的标签量比较大,该怎样选取呢?
str_1='''
<ul>
<li data="三国演义">罗贯中</li>
<li data="西游记" >施耐庵</li>
</ul>'''
这样就行了
soup=BeautifulSoup(str_1,'lxml')
s_2=soup.select('ul>li[data="三国演义"]')
print(s_2[0].string)
运行结果为 : 罗贯中
3.方法选择器
方法有 find_all() 、find() 、find_parents()、find_parent、find_next_sibling()、find_next_siblings()、find_previous_sibling、find_previous_siblings()、find_all_next()、find_next()、find_all_prevois()和find_previous()
下面逐一介绍上述方法的功能
find_all() :查询所有符合要求的元素,调用格式如下:
find_all(name,attrs,recursive,text,kwargs)
name参数,即查询所有符合节点名的元素
attrs参数 ,即查找所有符合属性名的元素
text参数 ,即查询所有符合文本数据的元素
举例:
str_1='<ul><li class="li_1" data="三国演义" >罗贯中</li><a href="http://baidu.com/"></a><li class="li_2" data="西游记" >施耐庵</li></ul>'
soup=BeautifulSoup(str_1,'lxml')
print(soup.find_all(name='li'))
# [<li class="li_1" data="三国演义">罗贯中</li>, <li class="li_2" data="西游记">施耐庵</li>]
print(soup.find_all(attrs={'data':'三国演义'}))
#[<li class="li_1" data="三国演义">罗贯中</li>]
print(soup.find_all(text='施耐庵'))
# ['施耐庵']
基本返回的数据类型为列表
find() 方法
返回的是第一个符合要求的元素,类型依旧是Tag类型
str_1='<ul><li class="li_1" data="三国演义" >罗贯中</li><a href="http://baidu.com/"></a><li class="li_2" data="西游记" >施耐庵</li></ul>'
soup=BeautifulSoup(str_1,'lxml')
print(soup.find(name='li'))
print(type(soup.find(name='li')))
# <li class="li_1" data="三国演义">罗贯中</li>
# <class 'bs4.element.Tag'>
print(soup.find(attrs={'data':'三国演义'}))
print(type(soup.find(attrs={'data':'三国演义'})))
# <li class="li_1" data="三国演义">罗贯中</li>
# <class 'bs4.element.Tag'>
print(soup.find(text='施耐庵'))
print(type(soup.find(text='施耐庵')))
# 施耐庵
# <class 'bs4.element.NavigableString'>
find_parents()和find_parent() :前者返回所有的祖先节点,后者返回直接父节点。
find_next_sibling()、find_next_siblings():前者返回后面的第一个兄弟节点,后者返回后面所有兄弟节点。
find_previous_sibling、find_previous_siblings() : 前者返回前面第一个兄弟节点,后者返回前面所有兄弟节点。
find_all_next()、find_next() :前者返回节点之后所有符合条件的节点,后者返回符合条件的第一个节点。
find_all_prevois()和find_previous() :前者返回节点之前符合要求的所有节点,后者返回符合要求的第一个节点。
注意:这里没有举例了,抱歉!
4.节点选择器
1.选择元素
基本就是通过 “.”+“节点名称”,得到的就是节点内的所有内容。
如下:
str_1='''
<ul>
<li class="li_1" data="三国演义">罗贯中</li>
<li class="li_2" data="西游记" >施耐庵</li>
</ul>'''
soup=BeautifulSoup(str_1,'lxml')
print(soup.li)
这里只打印第一个li节点
当有多个节点时,只会选择第一节点,如上,有两个li节点,但最终只输出第一个节点。
2.提取信息
(1)获取文本信息
如果刚才想得到罗贯中这个信息,可以用到 .string, 上面已经讲了的。
(2)获取属性
如果想得到三国演义的这个信息,可以直接 attrs[“属性名”] 即可。
如:
print(soup.li.attrs)
print(soup.li.attrs['data'])
print(soup.li.attrs['class'])

当然,也可以直接 “[‘属性名’]” 即可,如:
print(soup.li['data'])
print(soup.li['class'])

可以发现,返回的结果类型不同,一个是字符串,一个列表。为什么会出现这样的结果呢?原来是一个节点可能有多个class,而data是唯一的。所以,在提取信息时要注意返回的数据类型。
(3)获取名称
如果想得到一个节点的名称,可以用到 .name ,如下:
print(soup.li.name)
 3.嵌套选择
3.嵌套选择
依旧拿上面的那个举例, soup.ul 的类型是 <class ‘bs4.element.Tag’> ,那么是不是可以继续操作呢?(当然在下面还有子节点的情况下),结果是肯定的。
print(soup.ul.li)
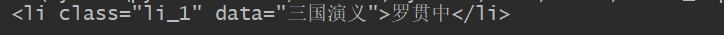
只不过和上面的那个一样,依旧只能得到子节点的第一个。
4. 关联选择
上面讲的那些只能得到一个节点下面的第一个子节点,那么要怎样得到一个节点下面的所有的子节点呢?
(1)子节点和子孙节点
1.讲到子节点,必须用到的是 .children
str_1='''
<ul>
<li class="li_1" data="三国演义" >罗贯中</li>
<li class="li_2" data="西游记" >施耐庵</li>
<ul>
<a></a>
<h1>四大名著</h1>
</ul>
</ul>'''
soup=BeautifulSoup(str_1,'lxml')
print(soup.ul.children)
for i in soup.ul.children:
print(i)
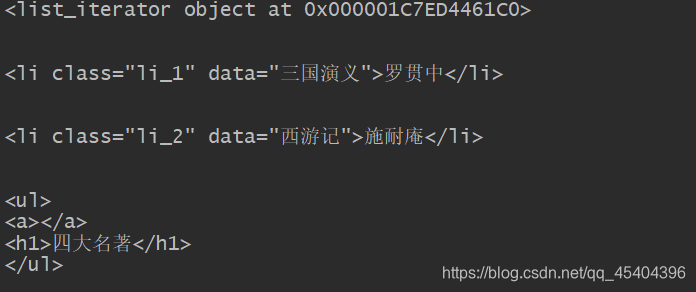
通过 .children 返回的是一个 <list_iterator object at 0x000001C7ED4461C0> 的对象,要想得到想要的数据或者信息,可以用到循环。
2.子孙节点
用到的是 .descendants
把上面的代码改动一下,得到ul节点下面的子孙节点。
运行结果如下:
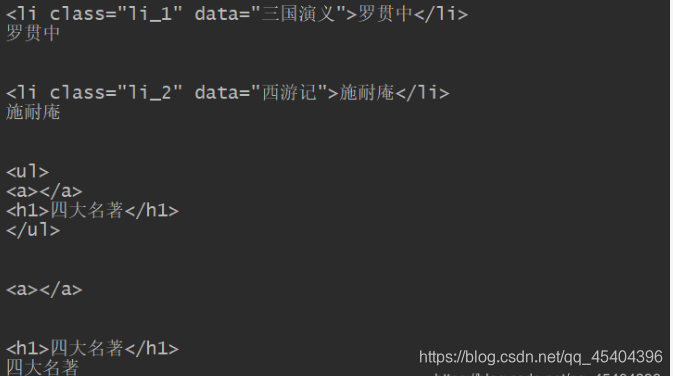
可以发现,此时的输出结果比上一个结果多了两个内容。
(2)父节点和祖先节点
1.父节点 .parent
如果想得到一个节点的上一个节点,可以用到parent属性 。
str_1='''
<ul>
<li class="li_1" data="三国演义" >罗贯中</li>
<li class="li_2" data="西游记" >施耐庵</li>
<ul>
<a></a>
<h1>四大名著</h1>
</ul>
</ul>'''
soup=BeautifulSoup(str_1,'lxml')
print(soup.a.parent)
2. 祖先节点 .parents
如果想得到一个节点所有祖先节点,可以用到 .parents 属性
str_1='''
<ul>
<li class="li_1" data="三国演义" >罗贯中</li>
<li class="li_2" data="西游记" >施耐庵</li>
<ul>
<a></a>
<h1>四大名著</h1>
</ul>
</ul>'''
soup=BeautifulSoup(str_1,'lxml')
print(soup.a.parents)
for i,j in enumerate(soup.a.parents):
print(i,j)
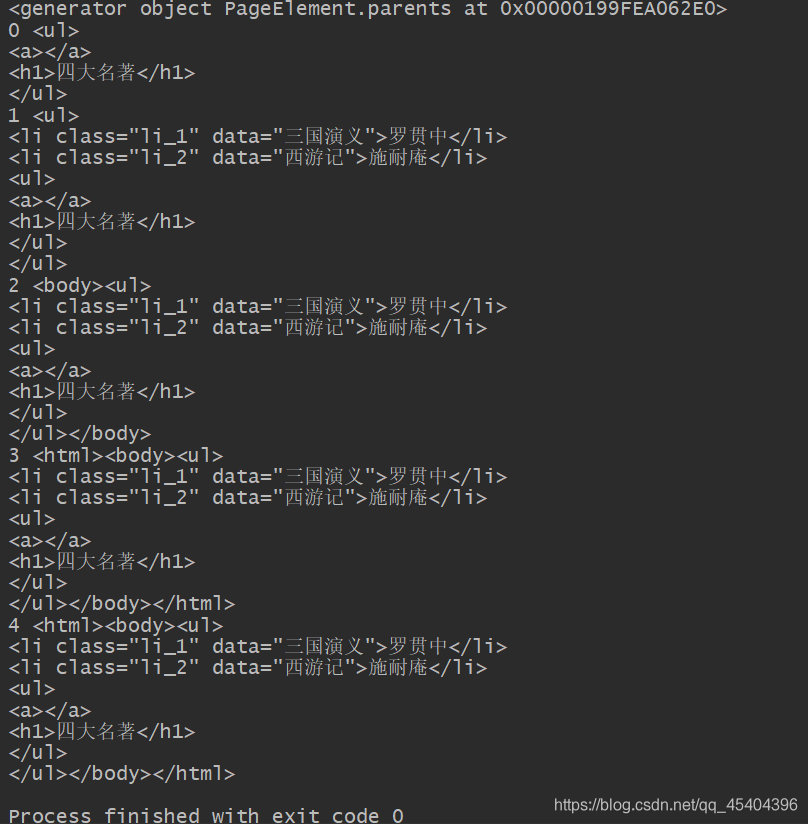
原本我只想得到 a节点的所有祖先节点,没想到我省略的其他的3个节点也输出来了。
(3)兄弟节点
上面讲的是都是不是同一级节点的获取,那么怎样得到同一级节点呢?
主要有两种. .next_sibling 和 .previous_sibling ,它们分别是得到节点的下一个兄弟节点和 节点的上一个节点。
而 .next_siblings 和 .previous_siblings s,它们分别是后面兄弟节点和前面兄弟节点的生成器。
举例:
str_1='<ul><li class="li_1" data="三国演义" >罗贯中</li><a href="http://baidu.com/"></a><li class="li_2" data="西游记" >施耐庵</li></ul>'
soup=BeautifulSoup(str_1,'lxml')
print(soup.a.next_sibling)
#<li class="li_2" data="西游记">施耐庵</li>
print(soup.a.previous_sibling)
#<li class="li_1" data="三国演义">罗贯中</li>
str_1='''
<ul>
<li class="li_1" data="三国演义" >罗贯中</li>
<li class="li_2" data="西游记" >施耐庵</li>
<ul>
<a></a>
<h1>四大名著</h1>
</ul>
</ul>'''
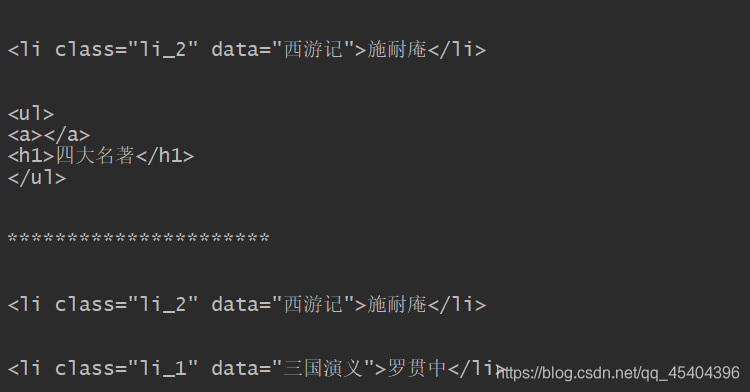
## 第一个 li 的所有兄弟节点
soup=BeautifulSoup(str_1,'lxml')
for i in soup.li.next_siblings:
print(i)
print('**********************')
## 里面 ul节点的所有兄弟节点
a=soup.a.parent
for i in a.previous_siblings:
print(i)
5.总结
就小编自己来说吧!我觉得三种选择器里面就CSS选择器最容易了,毕竟我这个最熟悉了,而其他两种选择器我很少用。不过,不知道是不是这个原因,感觉方法选择器和节点选择器总是有一些匹配不到,尽管代码没有错误,所以,小编觉得,读者最好用CSS选择器,这种选择器好像匹配在大部分情况下都可行的。最后,如果读者觉得我的这篇文章写的还不错,点一个赞呗!