Kafka
Kafka是一个分布式流平台,它具以下关键功能:
- 消息传递系统:发布和订阅记录流,类似于消息队列或企业消息传递系统。
- 存储系统:以容错的持久方式存储记录流。
- 流处理:处理发生的记录流。
Kafka通常用于两大类应用程序:
- 建立实时流数据管道,以可靠地在系统或应用程序之间获取数据。
- 构建实时流应用程序以转换或响应数据流。
Kafka的特性:
- Kafka在一个或多个可以跨越多个数据中心的服务器上作为集群运行。
- Kafka集群将记录流存储在称为topic的类别中。
- 每个记录由一个键,一个值和一个时间戳组成。
主题和日志
对于每个主题,Kafka群集都会维护一个分区日志,如下所示:
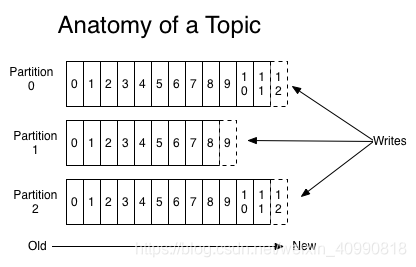
每个分区(Partition)都是有序的(所以每一个Partition内部都是有序的),不变的记录序列,这些记录连续地附加到结构化的提交日志中。分区中的每个记录均分配有一个称为偏移的顺序ID号,该ID 唯一地标识分区中的每个记录。
每个消费者保留的唯一元数据是该消费者在日志中的偏移量或位置。此偏移量由使用者控制:通常,使用者在读取记录时会线性地推进其偏移量,但实际上,由于位置是由使用者控制的,因此它可以按喜欢的任何顺序使用记录。例如,使用者可以重置到较旧的偏移量以重新处理过去的数据,或者跳到最近的记录并从“现在”开始使用。(类似于游标指针的方式顺序处理数据,并且该指标可以任意移动)
Kafka的安装及使用
单节点模式

tar -xvf kafka_2.12-2.5.0.tgz
cd kafka-2.5.0-src
kafka的目录结构:
- /bin 操作kafka的可执行脚本
- /config 配置文件所在目录
- /libs 依赖库目录
- /logs日志数据目录,目录kafka把server端日志分为5种类型,分为:server,request,state,log-cleaner,controller
b.配置zookeeper(若无zookeeper需要先安装zookeeper)
#启动zook
bin/zookeeper-server-start.sh config/zookeeper.properties
netstat -lnp |grep 2181
tcp 0 0 0.0.0.0:2181 0.0.0.0:* LISTEN 28751/java
c.启动kafka
kafka默认端口号是9092 -daemon:采用后台启动的方式
bin/kafka-server-start.sh -daemon config/server.properties
server.properties中的核心配置:
- broker.id: 属性是集群中每个节点的唯一且永久的名称
- log.dir:日志文件路径
- zookeeper.connect:zookeeper地址

d.建立主题
#创建主题
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test
#查看主题
bin/kafka-topics.sh --list --bootstrap-server localhost:9092
e.建立消息的生产者
bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic test
This is a message
This is another message
f.创建消息的消费者(消费者会异步地去接收消息)
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning

集群模式
a.修改server.properties来创建启动新的节点
cp config/server.properties config/server-1.properties
cp config/server.properties config/server-2.properties
修改配置信息如下:
config/server-1.properties:
broker.id=1
listeners=PLAINTEXT://:9093
log.dirs=/tmp/kafka-logs-1
config/server-2.properties:
broker.id=2
listeners=PLAINTEXT://:9094
log.dirs=/tmp/kafka-logs-2
b.启动新节点
bin/kafka-server-start.sh -daemon config/server-1.properties
bin/kafka-server-start.sh -daemon config/server-2.properties
c.创建集群中的新主题
partitions: 主题分区数。分区越多,提升消息处理的吞吐量越高,但是占用I/O越多,所以不能过多。
replication-factor: 用来设置主题的副本数。每个主题可以有多个副本,副本位于集群中不同的broker上,所以说副本的数量不能超过broker的数量,否则创建主题时会失败。
#创建主题
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 3 --partitions 1 --topic my-replicated-topic
#查看主题
bin/kafka-topics.sh --describe --bootstrap-server localhost:9092 --topic my-replicated-topic
 输出结果:
输出结果:
- Leader:是负责给定分区的所有读取和写入的节点。每个节点将成为分区的随机选择部分的领导者。
- Replicas:是为该分区复制日志的节点列表,无论它们是引导者还是当前处于活动状态。
- Isr:是“同步”副本的集合。这是副本列表的子集,当前仍处于活动状态并追随领导者。
一个broker是由ZooKeeper管理的单个Kafka节点。一组brokers组成了Kafka集群。
将不同的分区分配在一个集群中的broker上,一般会分散在不同的broker上(所以同一个broker不会存在同一份partitions副本),当只有一个broker时,所有的分区就只分配到该Broker上。
d.消息的生成者与消费者
> bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic my-replicated-topic
...
my test message 1
my test message 2
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic my-replicated-topic
...
my test message 1
my test message 2