MVCC即多版本并发控制。MVCC是一种并发控制的方法,一般在数据库管理系统中,实现对数据库的并发访问,在编程语言中实现事务内存。MVCC的实现主要是为了提高数据库并发性能,用更好的方式去处理读-写冲突,做到即使有读写冲突时,也能做到不加锁,非阻塞并发读。
一、MySQL
InnoDB是一个多版本的存储引擎:它保存有关已更改行的旧版本的信息以支持事务性功能,如并发和回滚。这些信息存储在表空间中的数据结构称为回滚段。InnoDB使用回滚段中的信息来执行事务回滚所需的回滚操作。它还使用这些信息来构建行的早期版本,以便进行一致的读取。
InnoDB实现MVCC的源码文件是read0read.cc。
InnoDb存储引擎中,每行数据包含了一些隐藏字段 DATA_TRX_ID,DATA_ROLL_PTR,DB_ROW_ID,DELETE BIT
DATA_TRX_ID :一个6byte的标识,记录了数据的创建和删除时间,这个时间指的是对数据进行操作的事务的id
DATA_ROLL_PTR:大小是7byte,指向当前数据的undo log记录,回滚数据就是通过这个指针
DB_ROW_ID: 大小是6byte,该值随新行插入单调增加。当由innodb自动产生聚集索引时聚集索引(即没有主键时,因为MYSQL默认聚簇表,会自动生成一个ROWID)包括这个DB_ROW_ID的值,不然的话聚集索引中不包括这个值。
DELETE BIT位用于标识该记录是否被删除,这里的不是真正的删除数据,而是标志出来的删除。真正意义的删除是在mysql进行数据的purge,清理历史版本数据的时候。
INSERT:创建一条新数据,DB_TRX_ID中的创建时间为当前事务id,DB_ROLL_PT为NULL
DELETE:将当前行的DB_TRX_ID中的删除时间设置为当前事务id,DELETE BIT设置为1
UPDATE:复制了一行,新行的DB_TRX_ID中的创建时间为当前事务id,删除时间为空,DB_ROLL_PT指向了上一个版本的记录,事务提交后DB_ROLL_PT置为NULL
SELECT:不做修改,只读取相应数据。
MVCC结合隔离级别:
READ UNCOMMITTED ,不适用MVCC读,可以读到其他事务修改甚至未提交的
READ COMMITTED ,其他事务对数据库的修改,只要已经提交,其修改的结果就是可见的,与这两个事务开始的先后顺序无关,不完全适用于MVCC读
REPEATABLE READ,可重复读,完全适用MVCC,只能读取在它开始之前已经提交的事务对数据库的修改,在它开始以后,所有其他事务对数据库的修改对它来说均不可见
SERIALIZABLE ,完全不适合适用MVCC,这样所有的query都会加锁,再它之后的事务都要等待
MVCC只工作在REPEATABLE READ和READ COMMITED隔离级别下
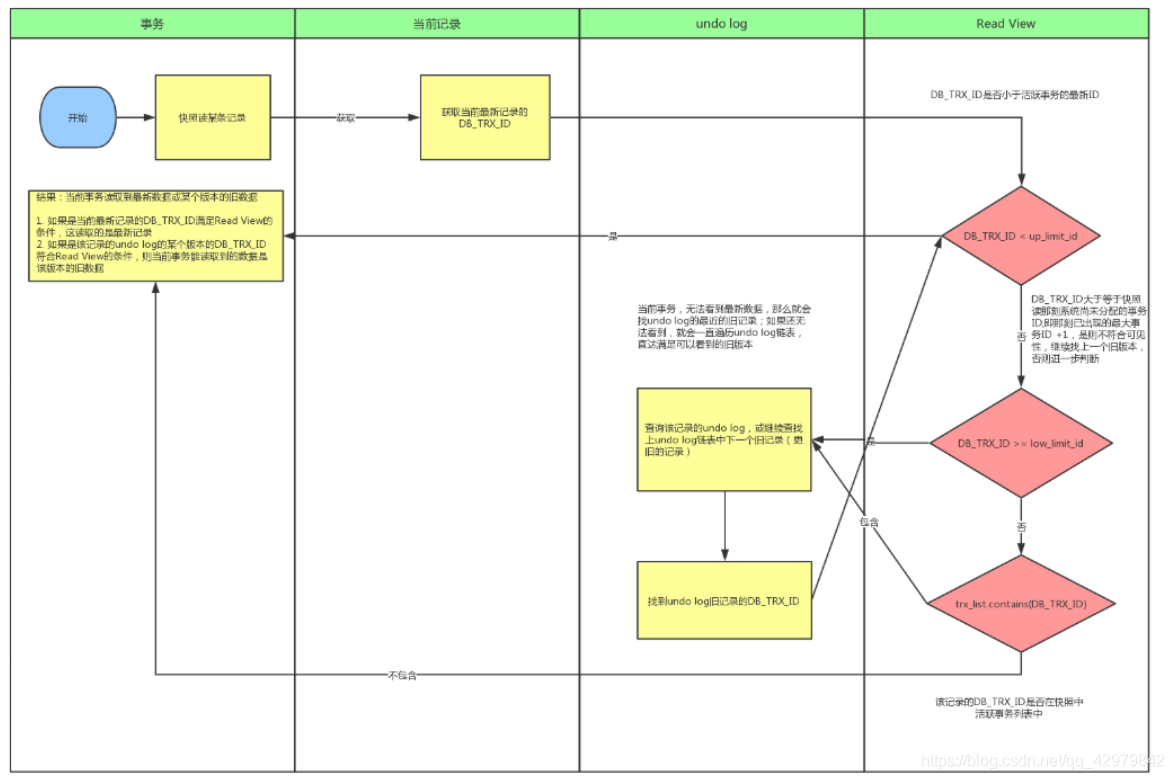
在innodb的RC或RR隔离级别下,快照读读不到事务未提交的数据。通过Read View实现。
Read View
Read View就是事务进行快照读操作的时候生产的读视图(Read View),在该事务执行的快照读的那一刻,会生成数据库系统当前的一个快照,记录并维护系统当前活跃事务的ID(当每个事务开启时,都会被分配一个ID, 这个ID是递增的,所以越新的事务ID值越大)
trx_list
一个数值列表,用来维护Read View生成时刻系统正活跃的事务ID
up_limit_id
记录trx_list列表中事务ID最小的ID
low_limit_id
ReadView生成时刻系统尚未分配的下一个事务ID,也就是目前已出现过的事务ID的最大值+1
首先比较DB_TRX_ID < up_limit_id, 如果小于,则当前事务能看到DB_TRX_ID 所在的记录,如果大于等于进入下一个判断
接下来判断 DB_TRX_ID 大于等于 low_limit_id , 如果大于等于则代表DB_TRX_ID 所在的记录在Read View生成后才出现的,那对当前事务肯定不可见,如果小于则进入下一个判断
判断DB_TRX_ID 是否在活跃事务之中,trx_list.contains(DB_TRX_ID),如果在,则代表Read View生成时刻,这个事务还在活跃,还没有Commit,修改的数据,当前事务也是看不见的;如果不在,则说明,这个事务在Read View生成之前就已经Commit了,修改的结果,当前事务是能看见的
在RC隔离级别下,是每个快照读都会生成并获取最新的Read View;
在RR隔离级别下,则是同一个事务中的第一个快照读才会创建Read View, 之后的快照读获取的都是同一个Read View
InnoDB多版本并发控制(MVCC)对二级索引的处理方式不同于对聚簇索引的处理方式。聚簇索引中的记录将就地更新,其隐藏列指向undo log记录,可以从中重建记录的早期版本。与聚簇索引记录不同,辅助索引记录不包含隐藏的系统列,也不会就地更新。
更新二级索引列时,将对旧的二级索引记录进行删除标记,插入新记录,并最终清除带有删除标记的记录。当二级索引记录被删除标记或二级索引页被较新的事务更新时,请InnoDB在聚集索引中查找数据库记录。在聚集索引中,DB_TRX_ID检查记录的记录,如果在启动读取事务后修改了记录,则从undo log中检索记录的正确版本。
如果二级索引记录被标记为删除或二级索引页被更新的事务更新, 则不使用覆盖索引。InnoDB没有从索引结构返回值,而是在聚集索引中查找记录。
如果启用了索引条件下推(ICP)优化,并且部分WHERE条件只能使用索引中的字段进行计算,那么MySQL服务器仍然会将WHERE条件的这一部分向下推送到存储引擎,在存储引擎中使用索引对其进行评估。如果找不到匹配的记录,将避免聚集索引查找。如果找到匹配的记录,即使在删除标记的记录中,InnoDB也会在聚集索引中查找该记录。
二、Oracle
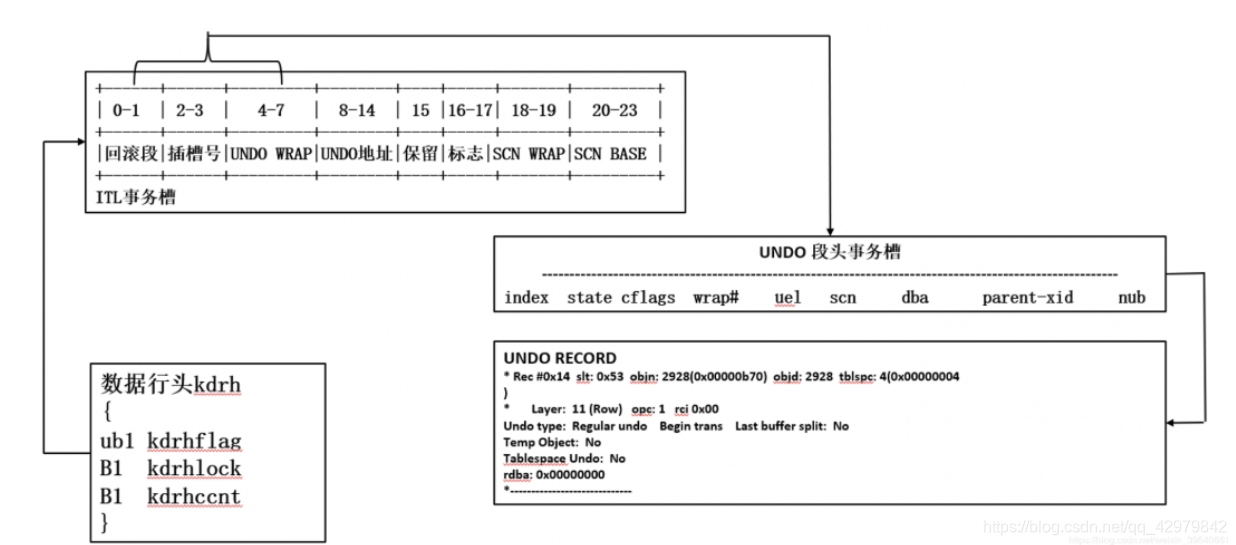
Oracle是在回滚段undo log中保存旧版本, 一个事务ID并不是一个顺序数字,而是由一系列数字组成,这些数字指向回滚段的头部事务槽。 回滚段能让新事务能重用存储,重用被已经提交或退出的旧事务使用过的事务槽,这种自动重用机制使得Oracle使用有限的回滚段可以管理大量的事务。
回滚段的头部块是用作一个事务表,这里保存着事务的状态,称为SCN, Oracle并不是存储页面中的每个记录的事务ID, 而是通过保存页面中每行记录的唯一事务ID的数组阵列节约空间使用,只保存记录的数组偏移量offset,和每个事务ID保存在一起的是一个指针,指向该页事务创建的最后undo记录,不仅表记录是这种方式存储,索引记录也是使用同样技术。
当一个Oracle事务启动时,它会标记一个当前事务状态SCN. 当读取一个表或一个索引页时,Oracle使用SCN数字来决定该页是否包含不应该让当前事务知晓的事务影响效果,Oracle通过寻找相联的回滚段头部来检查该事务的状态,但是为了节约时间,第一次是真正查询事务,查询完成它的状态会被记录在该页中以避免后来再次查询,如果该页被发现包含不可见事务的影响,Oracle通过undoing每个这样的事务影响来重新创建该页的旧版本。它扫描和每个事务有关的记录,将这些事务效果应用到该页,直至那些所有事务效果应用完成后被移除,以该方式创建的新页再用于访问其中的tuple。
Oracle中的记录头:
一个记录头部不会增长,总是有固定大小,对于非集群的表,记录头部是3个字节,一个字节被用于存储标识,一个字节用于显示记录是否被锁住(比如它被更新了但是没有确认提交committed),一个字节用于列计数。
三、SQL Server
在SQL Server数据库内部使用记录版本实现快照隔离和读取提交。当一个记录被修改或删除时,使用copy-on-write机制能够有效地启动版本,Row versioning–based事务能够有效地看到数据的从过去到现在的的前后一致的各种版本。
记录版本Row version保存在版本存储中,其驻留在主数据库之外的tempdb数据库中, 更特别地,当一张表或索引中一个记录被修改,新记录将携带上执行修改的事务的 ”sequence_number”. 记录的旧版本将被拷贝到版本存储中, 新记录包含一个指针指向版本存储中的这个旧记录,如果多个长运行 long-running事务存在,并且需要多个 ”版本versions”, 在版本存储中的记录也许包含指向该记录更早版本的指针。
SQL Server的版本存储清除:
SQL Server自动管理版本存储的大小,维持一个清除线程来确保版本存储中记录版本数量不至于太长,超过需要,对于在快照隔离下运行的查询,版本存储保留记录版本直到修改数据的事务完成,并且事务包含的任何需要修改数据的语句全部完成,对于在Read Committed 快照隔离下运行的SELECT语句 ,一个特别的记录版本就再也不需要了,一旦SELECT语句执行完成就被移除。
如果tempdb已经没有空闲空间, SQL Server会调用清除功能,增加文件的大小,当然前提是假设我们配置文件是自动增长的, 如果磁盘已经没有空间,文件不能自动增长, SQL Server会停止产生版本,如果这种情况发生,任何需要读取版本的快照查询因为空间限制将失败。
SQL Server中记录头
- 两字节记录元数据(记录类型)
- 两字节向前指向记录中的NULL 位图bitmap. 这是记录(固定长度列)实际大小的差值offset。
版本标记Versioning tag – 这是一个14-byte结构,包含时间戳加一个指向tempdb中版本存储的指针,这里时间戳是 trasaction_seq_number, 当需要支持一个版本操作时,加入版本信息到记录中时的时间。
四、PostgreSQL
在PostgreSQL中,当一行记录被更新时,该行数据的新版本(tuple)将被创建并插入表中,之前版本提供一个指针指向新版本,之前版本被标记为过期,但是还保留在数据库直到垃圾收集器回收掉。
为了支持多版本,每个tuple有以下附加数据记录:
- t_xmin:插入该元组的事务的txid;
- t_xmax:删除或更新该元组的事务的txid,如果尚未删除或更新该元组,则t_xmax设置为0;
- t_cid:命令ID(cid),这表示从0开始在当前事务中执行此命令之前已执行了多少个SQL命令;
- t_ctid:指向自身或新元组的元组标识符(tid),当该元组被更新时,该元组的t_ctid指向新的元组,否则,t_ctid指向自身。
事务状态是保存在 $Data/pg_clog的CLOG中. 这个表包含每个事务状态信息的两个字节,可能的状态有in-progress, committed, 或 aborted。 当一个事务结束后,PostgreSQL并不会将数据库记录的改变undo回滚的,它只是在CLOG标记事务为aborted . 一个PostgreSQL表可能包含许多这样aborted退出事务的数据。
一个称为Vacuum 清理流程会提供expired过期/aborted退出的记录版本的垃圾回收,Vacuum 清理器也会删除被垃圾回收的tuple相关的索引项。
一个tuple的xmin是有效且xmax无效时,它是可见的。 “Valid有效” 意味着 “或者是 committed 或代表当前事务”. 为了避免反复操作CLOG 表, PostgreSQL 在tuple中维持状态标识,以表示tuple是否是“known committed” 或 “known aborted”.
五、MongoDB
在MongoDB的WiredTiger引擎里面, 事务的一致性主要是通过timestamp,每一个timestamp对应一个相应的snapshot,对于每一个事务操作在事务开始的时候, 得到事务的timestamp, 在存储引擎里面会有一个snapshot与之对应。该snapshot记录了该事务在运行过程中的状态, 并且记录了事务还没有提交的事务的[min_snap_id, max_snap_id], 它是从创建snapshot的时候从global_snapshot里面copy出来的, 记录了在创建的时候, 还没有commit的事务列表。在min_snap_id之前的事务是已经提交的事务, 对应的数据是可以读的, 大于min_snap_id且小于等于max_snap_id是正在运行事务。
| ReadSource | 说明 |
|---|---|
| kUnset | 这是默认的行为, 没有指定timestamp |
| kNoTimestamp | 指定了没有timestamp的读取. |
| kMajorityCommitted | 从WiredTigerSnapshotManager::_committedSnapshot |
| kLastApplied | 从WiredTigerSnapshotManager::_localSnapshot读取 |
| kLastAppliedSnapshot | 从WiredTigerSnapshotManager::_localSnapshot读取 |
| kAllCommittedSnapshot | 从一个时间点, 在此之前的所有事务都已经提交了 |
| kProvided | 明确地指定了读取的timestamp, 调用了setTimestampReadSource |