1. 安装前说明
提供已编译后的cdh版本的spark
链接: https://pan.baidu.com/s/1zhgBfp6bzKupnJU1EOzlxQ
提取码: n4fm
博主的虚拟机的三个节点为 hadoop01,hadoop02,hadoop03
安装spark的目录为 /export/install/
上传解压包的路径为 /export/soft/spark-2.2.0-bin-2.6.0-cdh5.14.0.tgz
2. 配置spark
1. 上传解压
cd /export/soft
tar -zxvf spark-2.2.0-bin-2.6.0-cdh5.14.0.tgz -C ../install
2. 配置环境变量
// 1. 在 /etc/profile.d 目录下创建一个spark.sh 文件用来配置环境变量
cd /etc/profile.d
vim spark.sh
//2. 在 spark.sh 文件中添加如下内容(路径改为自己的)
//也可以直接在/etc/profile文件中添加(不建议):
export SPARK_HOME=/export/install/spark-2.2.0-bin-2.6.0-cdh5.14.0
export PATH=$PATH:$SPARK_HOME/bin
// 保存退出然后分配到其它节点
scp spark.sh hadoop02:$PWD
scp spark.sh hadoop03:$PWD
//刷新环境变量(每个节点都要执行)
source /etc/profile
注意: 配置完之后 hadoop/sbin 的目录和 spark/sbin 可能会有命令冲突
冲突的命令:
start-all.sh
stop-all.sh
解决方案(建议用第二种):
1.把其中一个框架的 sbin 从环境变量中去掉;
2.改名 hadoop/sbin/start-all.sh 改为: start-all-hadoop.sh
3.修改spark 的 配置
1. 修改 spark-env.sh 文件
//进入spark 配置目录
cd $SPARK_HOME/conf
//拷贝 spark-env.sh.template 文件
cp spark-env.sh.template spark-env.sh
//打开 spark-env.sh 文件
vim spark-env.sh
2. 在spark-env.sh文件中添加如下内容
#配置java环境变量
export JAVA_HOME=${JAVA_HOME}
#指定spark Master的IP
export SPARK_MASTER_HOST=hadoop01
#指定spark Master的端口
export SPARK_MASTER_PORT=7077
3. 修改slaves 文件
//拷贝 spark-env.sh.template 文件
cp slaves.template slaves
//删除 localhost
localhost
4. 在slaves 文件中添加要工作的节点(IP地址)
hadoop01
hadoop02
hadoop03
5. 分发到其它节点(hadoop01执行)
cd /export/install
scp -r spark-2.2.0-bin-2.6.0-cdh5.14.0 hadoop02:$PWD
scp -r spark-2.2.0-bin-2.6.0-cdh5.14.0 hadoop03:$PWD
启动 和 关闭 spark 集群
cd $SPARK_HOME/sbin
//启动
./start-all.sh
//关闭
./stop-all.sh
查看web界面
//浏览器访问如下路径:
http://hadoop01:8080
//或者
http://192.168.100.100:8080
4. 测试
1. 创建words 文件(博主实在opt目录下创建的)
//创建
cd /opt
vim words.txt
//上传到hadoop集群
hadoop fs -put /aaa/exercise01/
//添加以下内容
hello me you her
hello you her
hello her
hello
2. 集群模式启动spark-shell
$SPARK_HOME/bin/spark-shell --master spark://hadoop01:7077
3. 运行程序
运行的结果会生成到 /opt/output目录
sc.textFile("hdfs://hadoop01:8020/aaa/exercise01/words.txt").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).saveAsTextFile("hdfs://hadoop01:8020/aaa/exercise01/output")
查看结果 1
hadoop fs -ll /aaa/exercise01/output

查看运行结果 2
hadoop fs -cat /aaa/exercise01/output/part-00000
hadoop fs -cat /aaa/exercise01/output/part-00001

3.配置Spark HA (必须有一个zookeeper集群)
没有zk集群可以参考如下
zookeeper 的安装及 启动和关闭脚本
1.停止spark 集群
$SPARK_HOME/sbin/stop-all.sh
2.修改改配置
1.修改spark-env.sh文件
//进入 spark 配置文件目录
cd $SPARK_HOME/conf
//打开 spark-env.sh文件
vim spark-env.sh
//注释掉 Master配置
# export SPARK_MASTER_HOST=hadoop01
//添加SPARK_DAEMON_JAVA_OPTS,内容如下:
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop01:2181,hadoop02:2181,hadoop03:2181 -Dspark.deploy.zookeeper.dir=/spark"
//保存退出
:wq
2.参数说明
spark.deploy.recoveryMode:恢复模式
spark.deploy.zookeeper.url:ZooKeeper的Server地址
spark.deploy.zookeeper.dir:保存集群元数据信息的文件、目录。包括Worker、Driver、Application信息。
3.分发到其它节点
scp spark-env.sh hadoop02:$PWD
scp spark-env.sh hadoop03:$PWD
3. 测试
1. 启动zk集群博主直接用的脚本(自己修改)
zkstart-all.sh
没有的话可以使用 zkServer.sh start 命令启动
没有脚本可以配置参考链接:
https://blog.csdn.net/hongchenshijie/category_9453806.html
2. 启动spark 集群
// 启动spark (节点一运行)
$SPARK_HOME/sbin/start-all.sh
//在节点二单独只启动个master
$SPARK_HOME/sbin/start-master.sh
3.注意
- 在普通模式下启动spark集群
只需要在主节点上执行
start-all.sh就可以了
- 在高可用模式下启动spark集群
先需要在任意一台主节点上执行
start-all.sh
然后在另外一台主节点上单独执行start-master.sh
4.查看hadoop01和hadoop02
进入web,界面查看状态可以观察到有一台状态为StandBy
http://hadoop01:8080/
http://hadoop02:8080/
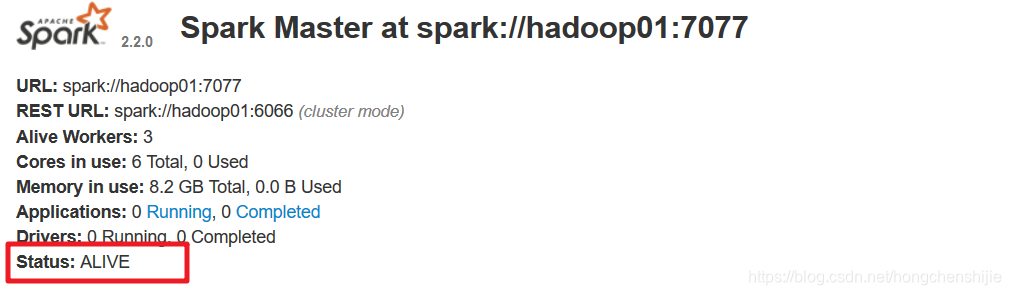

5.先使用jps查看 master 进程 id
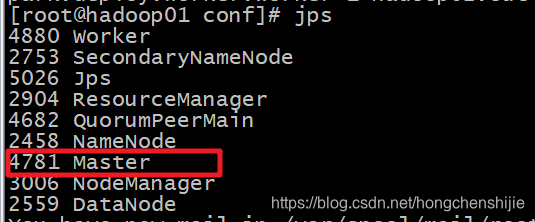
6. 使用kill -9 杀死master进程
kill -9 4781
7. 然后重新启动节点一的master
$SPARK_HOME/sbin/start-master.sh
8. 刷新后再次查看web界面
可以看到节点一的状态编程 standBy 了,节点二的状态变成了alive,这就说明配置成功了

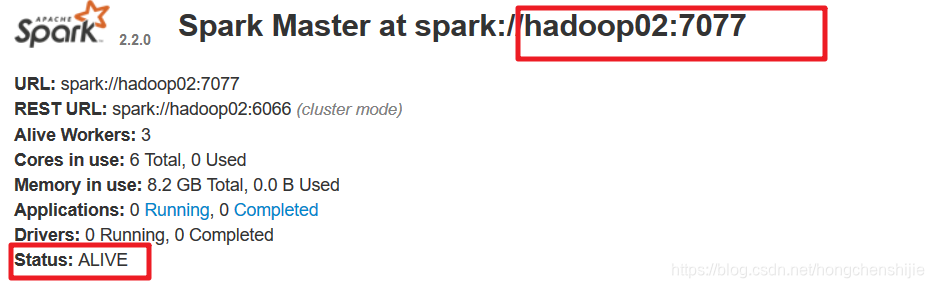
9. 测试向集群提交任务
//1.集群模式启动spark-shell
$SPARK_HOME/bin/spark-shell --master spark://hadoop01:7077,hadoop02:7077
//2. 提交任务
sc.textFile("hdfs://hadoop01:8020/aaa/exercise01/words.txt").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).saveAsTextFile("hdfs://hadoop01:8020/aaa/exercise01/output2")
10.参看结果
hadoop fs -ls /aaa/exercise01/output2/
hadoop fs -cat /aaa/exercise01/output/part-00000
hadoop fs -cat /aaa/exercise01/output/part-00001


4. on yarn模式
官方文档
http://spark.apache.org/docs/latest/running-on-yarn.html
1.安装启动Hadoop(需要使用HDFS和YARN,已经ok)
2.安装单机版Spark(已经ok)
注意:不需要集群,因为把Spark程序提交给YARN运行本质上是把字节码给YARN集群上的JVM运行,但是得有一个东西帮我去把任务提交上个YARN,所以需要一个单机版的Spark,里面的有spark-shell命令,spark-submit命令
3.修改配置
在spark-env.sh ,添加HADOOP_CONF_DIR配置,指明了hadoop的配置文件的位置
//打开配置文件
cd $SPARK_HOME/conf
vim spark-env.sh
//添加如下配置
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
//分发到其它节点(可以不分发)
scp spark-env.sh hadoop02:$PWD
scp spark-env.sh hadoop03:$PWD
修改完成之后如下

4. 提交任务到yarn
先进入 http://hadoop01:8088 yarn页面
提交一下命令
$SPARK_HOME/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 2 \
--queue default \
$SPARK_HOME/examples/jars/spark-examples_2.11-2.2.0.jar \
10
刷新后看到任务就说明配置成功了
