多任务对抗学习[1]
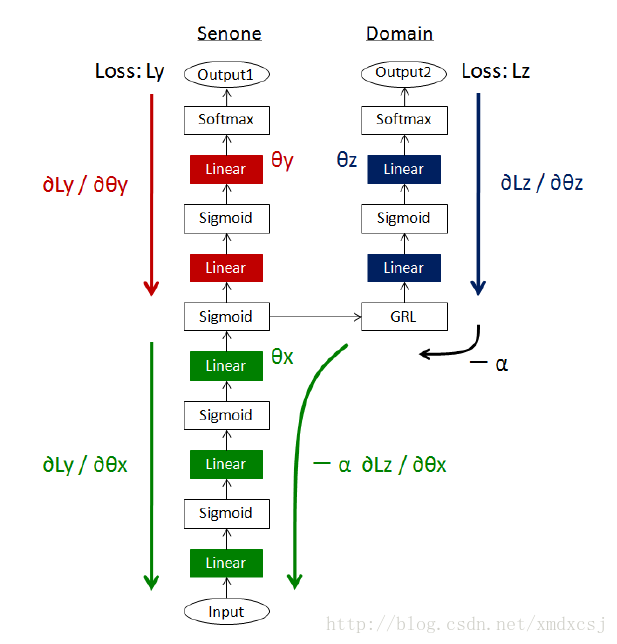
为了获得对噪音的鲁棒性,引入多任务学习,分为三个网络:
- 输入网络(绿色),用作特征提取器
- senone输出网络(红色),用作senone分类
- domain输出网络(蓝色),domain这里指噪音的类型,总共17种噪声
为了增加对噪音的鲁棒性,增加了GRL层(gradient reversal layer),网络在反向传播的时候,对于domain网络过来的梯度取了
[2]和[1]的思想类似。
SEGAN[3]
主要用来做语音增强(比如降噪)等。
结合conditional GAN和LSGAN,使用
一些参数的含义如下:
训练流程如下:
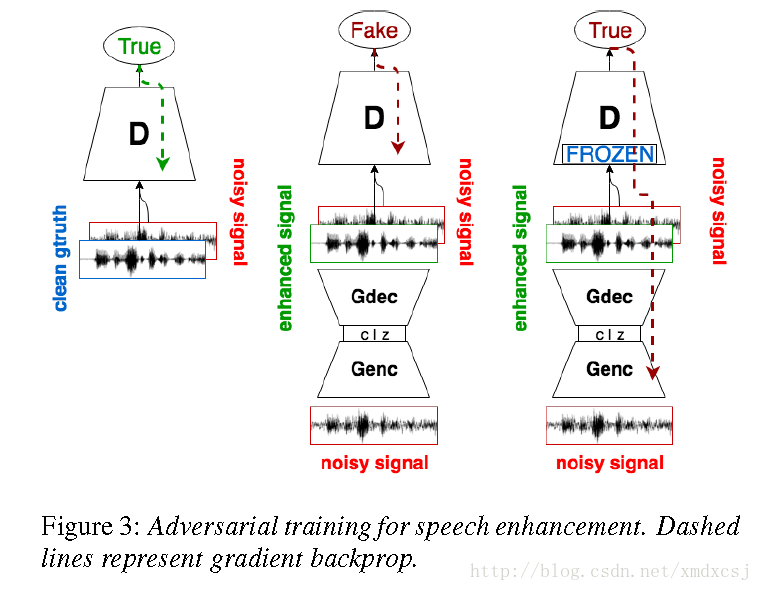
训练的时候需要clean speech和noisy speech的pair,以保证在去除噪声的同时保留原始语音的信息。
参考文献
[1].Adversarial Multi-task Learning of Deep Neural Networks for Robust Speech Recognition
[2].Invariant Representations for Noisy Speech Recognition
[3].SEGAN: Speech Enhancement Generative Adversarial Network