hadoop入门
第一章
1.1 大数据特点(4V)
大量、高速(对数据的处理)、多样性、低价值密度
1.2大数据的应用场景
物流仓储:大数据分析助力精细化运营,节约成本。
零售:通过大数据分析消费者的消费习惯,为用户购买商品提供方便,从而提升商品销量。
旅游:结合大数据能力与旅游行业需求,建立旅游产业的智慧管理,智慧服务,智慧营销。
商品广告推荐:给用户推荐可能喜欢的商品。
保险:海量数据挖掘及风险预测,帮助保险行业精准营销
金融:多维度体现用户特征,帮助金融机构推荐一些优质客户
人工智能:
1.3大数据部门业务流程
1:产品人员提需求(统计总用户数、日活跃用户数、回流用户数等)
2:数据部门搭建数据平台、分析数据指标
3:数据可视化(报表展示、屏幕展示)
1.4大数据部门组织结构(重点)
graph LR
A[大数据部门组织结构]
A --> B(平台组:1:hadoop,Hbase等框架平台的搭建 2:集群的性能监控 3:集群性能调优)
A --> C(数据仓库组:1:ETL工程师-数据清洗 2:Hive工程师-数据分析、数据仓库建模)
A --> D(数据挖掘组:1:算法工程师 2:推荐系统工程师 3:用户画像工程师)
A --> E(数据开发组:JavaEE工程师)
第二章
2.1Hadoop的优势
1:高可靠性:底层维护多个数据副本,
2:高扩展性:方便扩展计算节点
3:高效性:在MapReduce的思想下,Hadoop是并行工作的,处理速度快
4:高容错性:能够自动将失败的任务重新分配
2.2Hadoop组成(面试重点)
Hadoop1.x与Hadoop2.x的区别
回答:在Hadoop1.x时代,Mapreduce同时处理业务逻辑的计算和资源调度,耦合性较大,在Hadoop2.x时代,增加了Yarn,由Yarn负责资源的调度,Mapreduce只负责运算
2.3大数据技术生态体系
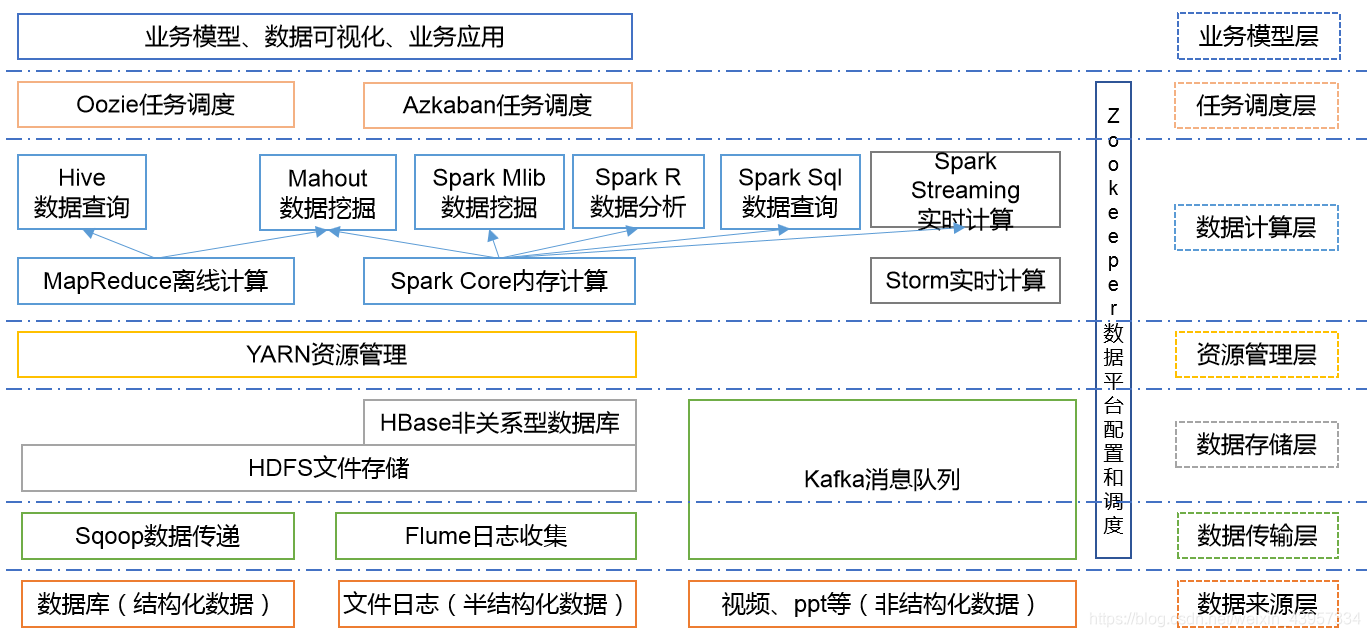
Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
Storm:Storm用于“连续计算”,对数据流做连续查询,在计算时就将结果以流的形式输出给用户
Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
第3章 Hadoop运行环境搭建(开发重点)
3.1虚拟机环境准备
1>克隆虚拟机
2>修改克隆虚拟机的静态IP
3>修改主机名
4>关闭防火墙
5>创建用户
6>配置用户具有root权限
3.2安装JDK
配置JDK环境变量
(1)先获取JDK路径
[atguigu@hadoop101 jdk1.8.0_144]$ pwd
/opt/module/jdk1.8.0_144
(2)打开/etc/profile文件,在profile文件末尾添加JDK路径
[atguigu@hadoop101 software]$ sudo vi /etc/profile
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
(3)保存后退出
(4)让修改后的文件生效
[atguigu@hadoop101 jdk1.8.0_144]$ source /etc/profile
3.2安装Hadoop
(1)将Hadoop添加到环境变量
…
3.3伪分布式运行模式
启动HDFS并运行MapReduce程序
1. 分析
(1)配置集群
(2)启动、测试集群增、删、查
(3)执行WordCount案例
2需要的配置文件:
(a)配置:hadoop-env.sh
(b)配置:core-site.xml
(c)配置:hdfs-site.xml
3启动集群
(a)格式化NameNode(第一次启动时格式化,以后就不要总格式化)
(b)启动NameNode
(c)启动DataNode
(d)查看是否启动成功>jps
(e)查看产生的Log日志(在企业中遇到Bug时,经常根据日志提示信息去分析问题、解决Bug。)
思考:为什么不能一直格式化NameNode,格式化NameNode,要注意什么?
格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。所以,格式NameNode时,一定要先删除data数据和log日志,然后再格式化NameNode。
(注意,将运行结果输出到output文件,output文件不能提前已存在)
启动YARN并运行MapReduce程序
1. 分析
(1)配置集群在YARN上运行MR
(2)启动、测试集群增、删、查
(3)在YARN上执行WordCount案例
2. 需要的配置文件:
(a)配置yarn-env.sh
(b)配置yarn-site.xml
(c)配置mapred-env.sh
(d)配置mapred-site.xml
3启动集群
(a)启动前必须保证NameNode和DataNode已经启动
(b)启动ResourceManager
(c)启动NodeManager
3.4完全分布式运行模式(开发重点)
1)准备3台客户机(关闭防火墙、静态ip、主机名称)
2)安装JDK
3)配置环境变量
4)安装Hadoop
5)配置环境变量
6)配置集群
7)单点启动
8)配置ssh免密登录(hadoop 的进程之间通信使用ssh 方式,每次都要输入密码。为了实现自动化操作,需要配置SSH 的免密码登录方式)
9)群起并测试集群
编写集群分发脚本xsync
1. scp(secure copy)安全拷贝
(1)scp定义:
scp可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)
(2)基本语法
scp -r
fname
host:
fname
命令 递归 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
2. rsync 远程同步工具
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
(1)基本语法
rsync -rvl
fname
host:
fname
命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
3. xsync集群分发脚本
(1)需求:循环复制文件到所有节点的相同目录下
(2)需求分析:
(a)rsync命令原始拷贝:
rsync -rvl /opt/module root@hadoop103:/opt/
(b)修改脚本 xsync 具有执行权限
[atguigu@hadoop102 bin]$ chmod 777 xsync
(c)调用脚本分发:xsync 文件名称
[atguigu@hadoop102 bin]$ xsync /home/atguigu/bin
集群配置
1. 集群部署规划
| hadoop102 | hadoop103 | hadoop104 | |
|---|---|---|---|
| HDFS | NameNode、DataNode | DataNode | SecondaryNameNode、DataNode |
| YARN | NodeManager | ResourceManager、NodeManager | NodeManager |
2. 配置集群
(1)核心配置文件
(2)HDFS配置文件
(3)YARN配置文件
(4)MapReduce配置文件
3.在集群上分发配置好的Hadoop配置文件
SSH无密登录配置
群起集群
1.配置slaves(服役节点)
/opt/module/hadoop-2.7.2/etc/hadoop/slaves
[atguigu@hadoop102 hadoop]$ vi slaves
在该文件中增加如下内容:
hadoop102
hadoop103
hadoop104
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
2.启动集群
(1)如果集群是第一次启动,需要格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
(2)启动HDFS
(3)启动YARN
- 注意:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 YARN,应该在ResouceManager所在的机器上启动YARN。
(4)Web端查看SecondaryNameNode
- 浏览器中输入:http://hadoop104:50090/status.html
3. 集群基本测试
(1)上传文件到集群
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs dfs -mkdir -p /user/atguigu/input
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs dfs -put wcinput/wc.input
/user/atguigu/input
(2)下载
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hadoop fs -get
/user/atguigu/input/hadoop 2.7.2.tar.gz ./
集群启动/停止方式总结
各个模块分开启动/停止(配置ssh是前提)常用
(1)整体启动/停止HDFS
start-dfs.sh / stop-dfs.sh
(2)整体启动/停止YARN
start-yarn.sh / stop-yarn.sh
第4章 Hadoop编译源码(面试重点)
预留问题:为啥要编译源码呢?
4.1前期准备工作
- CentOS联网
配置CentOS能连接外网。Linux虚拟机ping www.baidu.com 是畅通的
注意:采用root角色编译,减少文件夹权限出现问题
- jar包准备(hadoop源码、JDK8、maven、ant 、protobuf)
(1)hadoop-2.7.2-src.tar.gz
(2)jdk-8u144-linux-x64.tar.gz
(3)apache-ant-1.9.9-bin.tar.gz(build工具,打包用的)
(4)apache-maven-3.0.5-bin.tar.gz
(5)protobuf-2.5.0.tar.gz(序列化的框架)
4.2 jar包安装
(注意:所有操作必须在root用户下完成)
略,待补充
4.3 编译源码
第5章 常见错误及解决方案
略。待补充