urllib库
前言
在爬虫的实际操作的过程中,我们想要获取网页内容,这个时候我们只需要两行代码即可。这个功能就是第三方库的实现…
在Python2中我们的库有urllib2和urllib两个库,但是在Python3的版本里面,我们将这个库直接合并为了urllib了,这个也是我们在平时安装它的时候,为什么安装不起的原因了。
使用urllib库
request:它是最基本的 HTTP 请求模块,可以用来模拟发送请求 。
error:异常处理模块,如果出现请求错误 , 我们可以捕获这些异常,然后进行重试或其他操作以保证程序不会意外终止 。
parse:一个工具模块,提供了许多 URL 处理方法,比如拆分、解析 、 合并等 。
发送请求
我们以百度为例,首先获取它的网页信息。再次首先要安装这个库,我之前的文章有介绍详细的安装方法。
urlopen方法
import urllib.request
from urllib import request
response = urllib.request.urlopen("https://www.baidu.com",timeout=2) #超时操作,避免其他网站封杀电脑IP
print(response.read().decode("utf-8")) #请求网页数据源代码,decode(“utf-8”)
这里的timeout的作用是超时作用,其目的就是我在2秒之内没有获取到该网页就会报错,一般如果爬取较大的网站的时候我们可以设置一些参数,来解决我们的困难操作。看看下面的输出
 我们只用了两行代码就完成了网页源代码的输出,至于.read()就是一个调用方法,.decode(“utf-8”)就是一个编码的转换,很强大的一个功能。在request里面还有很多这样的属性方法,例如下面的…
我们只用了两行代码就完成了网页源代码的输出,至于.read()就是一个调用方法,.decode(“utf-8”)就是一个编码的转换,很强大的一个功能。在request里面还有很多这样的属性方法,例如下面的…
import urllib.request
from urllib import request
response = urllib.request.urlopen("https://www.baidu.com",timeout=2) #超时操作,避免其他网站封杀电脑IP
print(response.read().decode("utf-8")) #请求网页数据源代码,decode(“utf-8”)
print(type(response)) #输出响应类型
print(response.status) #返回状态码 200为正常!
print(response.getheaders()) #获取响应的头信息
print(response.getheader("Server")) #获取服务器搭建类型
我这里就不打印了
Request方法
我们知道urlopen方法可以请求网页,并获得一些东西,但是这并不足以解决我们的实际问题。比如我们需要加入一些headers 信息
class urllib. request. Request (ur1, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
from urllib import request,parse
url = "http://httpbin.org/post "
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
}
dict={
"name":"wangxiaownag"
}
data=bytes(parse.urlencode(dict),encoding="utf-8")
req = request.Request(url=url, headers=headers,data=data,method="POST") #解决系统识别的爬虫,伪装为浏览器进行
response = request.urlopen(req) #再次请求网页
print(response.read().decode("utf-8"))
'''
data参数,必须要传入bytes(字节流)类型,如果是字典类型,我们先用urllib.parse里面的urlencode()编码
例如:dict={"键":"值"};data=bytes(parse.urlencode(dict),encoding="utf-8")
method参数,表示请求使用方法,一般有GET,POST,PUT
'''

高级用法

opener这个其实和urlopen差不多,如出一辙,但是它属于高级用法,用于需要验证的网站来获取,比如下面的一个实例获取验证后的源码
from urllib.request import HTTPPasswordMgrWithDefaultRealm, HTTPBasicAuthHandler, build_opener
from urllib.error import URLError
username = ' username'
password = 'password '
url = " http: //localhost:sooo/"
p = HTTPPasswordMgrWithDefaultRealm()
p.add_password(None, url, username, password)
auth_handler = HTTPBasicAuthHandler(p)
opener = build_opener(auth_handler)
try:
result = opener.open(url)
html = result.read().decode(" utf 8")
print(html)
except URLError as e:
print(e.reason)
代理
from urllib.error import URLError
from urllib.request import ProxyHandler, build_opener
proxy_handler = ProxyHandler({
"http": " http://127.o.o .1:9743 ",
"https": " https://127.0 .0.1:9743 "
})
opener = build_opener(proxy_handler)
try:
response = opener.open("’ https://www.baidu.com'")
print(response.read().decode(" utf-8"))
except URLError as e:
print(e.reason)
本地搭建了一个代理,它运行在 9743 端口上 。使用了 ProxyHandler ,其参数是一个字典,键名是协议类型(比如 HTTP 或者 HTTPS 等),键值是代理链接,可以添加多个代理。
http://www.kxdaili.com/dailiip.html
http://www.89ip.cn/
https://ip.jiangxianli.com/

cookies
import http.cookiejar, urllib.request
cookie = http. cookiejar. CookieJar()
handler = urllib .request.HTTPCookieProcessor (cookie)
opener = urllib.request.build_opener(handler )
response = opener. open(' http://www.baidu.com')
for item in cookie:
print(item.name+'='+item.value)
处理异常
from urllib import request,error
try:
response=request.urlopen("https:www.cuiqingcai.com/index.htm") #乱写的一个网址
except error.URLError as e:
print(e.reason) #返回错误值
处理异常我们异常有HTTPError这个里面的属性有.reasom .code .headers这些属性,在实际操作中我们发现只有学会善用异常处理,这样才能使得代码优化,高效率运行,减少bug的出现!!!!
解析链接
之前我们讲了如何去用urllib来获取网页的源码,下一步我们的计划就是去解析网页了。
对于一个网址,我们有标准的链接解释
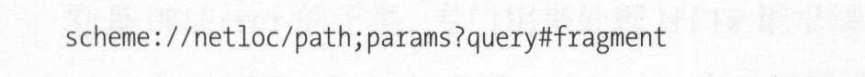
urlparse()
它的功能就是可以识别一个网址的元素,进行分段,就比如上面的那张图片
from urllib.parse import urlparse,urlencode,quote
result=urlparse("https://www.baidu.com",scheme="https",allow_fragments=False)
print(type(result),result) #返回网址的类型对象

urlunparse()
对URL实现构造
from urllib.parse import urlparse,urlencode,quote
result=urlparse("https://www.baidu.com",scheme="https",allow_fragments=False)
print(type(result),result) #返回网址的类型对象
''' urlunpaser()
urlsplit()不会单独解析params这一部分,只返回5个结果
urlunsplit()
urljoin()完成链接合并
urlencode()在构造GET请求时候 序列化
parse_qs()反序列化
parse_qsl()将参数转换为元组
quote()将内容转换为URL编码格式,避免URL里面带有的中文,导致乱码问题
'''
params={"name":"wangxiaowang",
"age":100
}
base_url="htts://www.baidu.com?"
keys="王小王"
url=base_url+urlencode(params)+quote("keys")
print(url)

robotas协议
用来判断哪些页面是可以抓取,哪些是不可以的[详情点击了解!]
https://blog.csdn.net/yyywyr/article/details/7931546
好了本期文章介绍了urllib这个库的使用,下期文章我们再会!