目录
集群环境准备:
centos7 VMworkstation15
1.先自己创建一台虚拟机,然后再克隆三台(将以克隆两台以上,另外我的电脑是16G的,每个虚拟机给的虚拟内存是20G,运行内存1G,不要安装可视化界面,足够我们平常瞎鼓捣了)
2.修改主机名称hostname,分别为
namenode:master datanode:slave1 slave2
vi /etc/hostname
注意:改完后不要在前面留空格或者行列,不然可能显示你改的无效,我在这里呗坑的很惨
将localhost改为master,然后reboot重启,另外两台分别改为slave1和slave2,修改后是这个样子。
敲击ESC,然后:wq保存退出,可能要重启才会生效
#查看
hostname
关闭防火墙
–装有iptables的情况下
service iptables stop
chkconfig iptables off
service iptables status
–未安装iptables情况下
systemctl stop firewalld.service
systemctl disable firewalld.service
Firewall-cmd --state
配置域名映射
vi /etc/hosts
注意,这里通过ip addr命令来查看,不要照抄
有的虚拟机如果没有配置静态IP,可能看不到自己的IP,也ping不同,那就运行以下:dhclient -r ,然后在dhclient
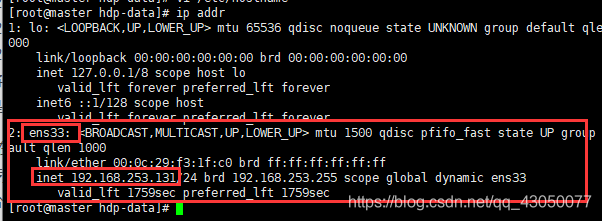
192.168.253.131 master
192.168.253.132 slave1
192.168.253.133 slave2
并将hosts文件拷贝到其他两台服务器上
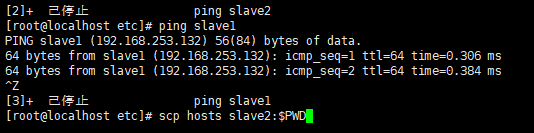
看是否可以ping通
例如:ping slave1
在每台linux服务器上安装jdk及hadoop
1.上传jdk安装包master,然后使用scp命令将jdk安装包发送到其他两台服务器
如果要master虚拟主机下的/opt的jdk传送到slave1虚拟机下,需要先切换到masert主机下的/opt目录下
#如果要master虚拟主机下的/opt的jdk传送到slave1虚拟机下,需要先切换到masert主机下的/opt目录下
# scp是命令
# jdk要传送的文件
#-r 强制符
#slave1:另一个虚拟机的名字
#后面的照抄,不要改动
scp jdk -r salve1:$PWD
对三台服务器上的jdk压缩包解压
tar -zxvf jdk-…
修改master的环境变量:/etc/profile
vi /etc/profile
export JAVA_HOME=/home/hadoop/jdk1.8.0_60/
export PATH=$PATH:$JAVA_HOME/bin
将修改后的profile文件scp到其他两台服务器,分别编译,执行java -version确认环境变量修改成功
- 安装HDFS
上传hadoop的安装包
解压hadoop安装包
配置HDFS的环境,也是子啊/etc/profile目录下
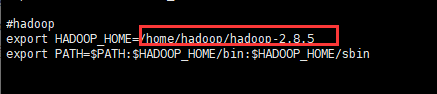
3.修改配置文件
注意:下面的这些配置文件的位置默认在: 解压目录/etc/hadoop下面
,例如我的
vi /home/hadoop/hadoop-2.8.5/etc/hadoop/hadoop-env.sh
1、修改hadoop-env.sh
export JAVA_HOME=/home/hadoop/jdk1.8.0_60/
2、修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hdptmp/</value>
</property>
</configuration>
**注意:**只用配置一次,因为正常来讲,一个集群只有一个namenode,其他的集群服务器不用配置

3、修改hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/hdp-data/name/</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/hdp-data/data/</value>
</property>
</configuration>
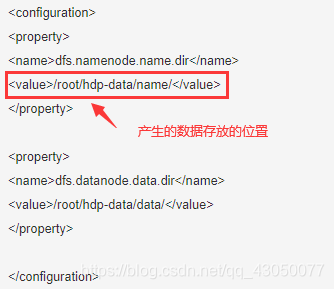
补充参数:
dfs.replication 默认值3 ## 副本数量,该参数其实用于客户端软件
dfs.blocksize 默认值134217728 ##块大小,该参数其实用于客户端软件
启动hdfs集群
1、先初始化namenode的元数据存储目录:格式化
注意:在bin目录下进行
./hadoop namenode -format
2、先启动namenode
进入hadoop安装目录,里面有一个sbin目录,里面有一个脚本可用于启动hadoop的进程
./hadoop-daemon.sh
启动namenode: hadoop-daemon.sh start namenode
如果报错,说命令不认识,则应该把hadoop是sbin目录配置到linux的系统环境变量PATH中
3、启动datanode
先将hadoop安装包从第一台配置好的机器上复制到另外2台机器
然后在后2台机器上配置好path环境变量
然后输入命令启动datanode
.hadoop-daemon.sh start datanode
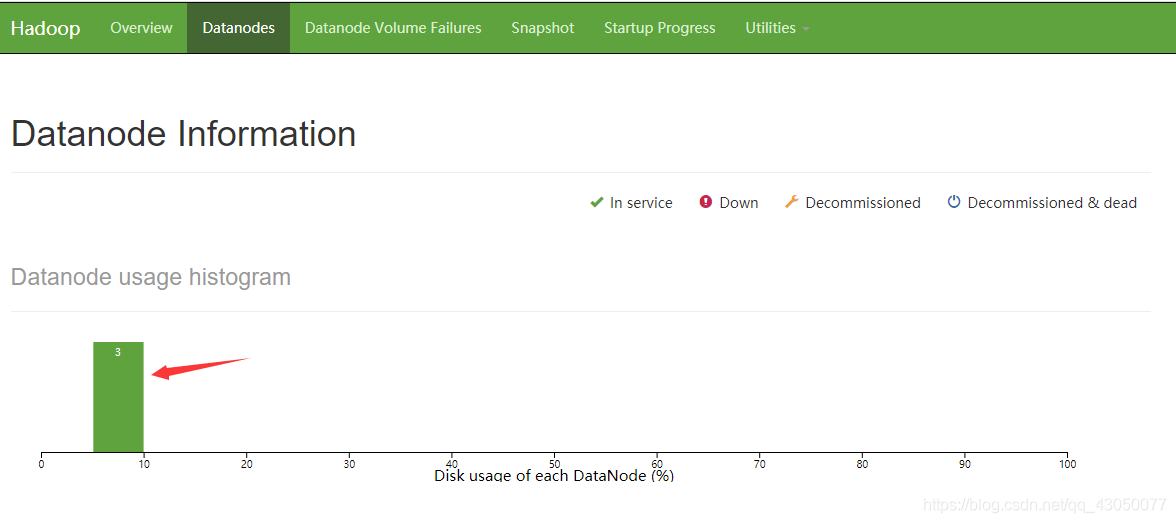
4、访问namenode的web页面
浏览器:http://【IP】:50070
可以看到2台datanode在线,即集群启动成功(因为我总共配置了4台,所以显示的是3datanode,还有一台是namenode)
批量自动启动集群
1、先配置master机器到所有机器的ssh免密登陆
ssh-keygen ## 生成密钥对
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2
ssh-copy-id slave3
检查: 从master上: ssh slave1 看是否要密码(注意:每一台上面都要进行配置)
2、修改slaves文件,将需要让脚本自动启动的datanode域名填入salves文件
cd /home/hadoop/hadoop-2.8.5/etc//hadoop/
vi slaves
将下面的内容复制进去
master
slave1
slave2
slave2
3、用hadoop安装目录中的sbin目录中的start-dfs.sh即可自动批启动集群
启动:start-dfs.sh
停止:stop-dfs.sh
HDFS命令行客户端常用操作命令
1.2.1. hdfs命令行客户端支持的所有命令:
[root@hdp20-04 ~]# hadoop fs
Usage: hadoop fs [generic options]
[-appendToFile … ]
[-cat [-ignoreCrc] …]
[-checksum …]
[-chgrp [-R] GROUP PATH…]
[-chmod [-R] <MODE[,MODE]… | OCTALMODE> PATH…]
[-chown [-R] [OWNER][:[GROUP]] PATH…]
[-copyFromLocal [-f] [-p] [-l] [-d] … ]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] … ]
[-count [-q] [-h] [-v] [-t []] [-u] [-x]
[-cp [-f] [-p | -p[topax]] [-d] … ]
[-createSnapshot []]
[-deleteSnapshot ]
[-df [-h] [
[-du [-s] [-h] [-x]
[-expunge]
[-find
[-get [-f] [-p] [-ignoreCrc] [-crc] … ]
[-getfacl [-R]
[-getfattr [-R] {-n name | -d} [-e en]
[-getmerge [-nl] [-skip-empty-file] ]
[-help [cmd …]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [
[-mkdir [-p]
[-moveFromLocal … ]
[-moveToLocal ]
[-mv … ]
[-put [-f] [-p] [-l] [-d] … ]
[-renameSnapshot ]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] …]
[-rmdir [–ignore-fail-on-non-empty]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>}
[-setfattr {-n name [-v value] | -x name}
[-setrep [-R] [-w]
[-stat [format]
[-tail [-f] ]
[-test -[defsz]
[-text [-ignoreCrc] …]
[-touchz
[-truncate [-w]
[-usage [cmd …]]
1.2.2. 需要掌握的常用命令:
1、上传文件
hadoop fs -put test.txt /
hadoop fs -copyFromLocal test.txt /test.txt.2
2、下载文件
hadoop fs -get /test.txt.2
hadoop fs -copyToLocal /test.txt.2
3、创建目录
hadoop fs -mkdir /aaa
hadoop fs -mkdir -p /bbb/xxx
4、删除目录
hadoop fs -rm -r /aaa
5、移动/重命名
hadoop fs -mv /test.txt.2 /test.txt.3
hadoop fs -mv /test.txt.3 /bbb/test.txt.4
6、拷贝文件
hadoop fs -cp /test.txt /bbb/
7、查看目录下的子文件夹和文件
hadoop fs -ls /bbb/xxx/
hadoop fs -ls -R / ##递归显示指定路径下的所有文件和文件夹信息
8、查看《文本》文件内容
hadoop fs -cat /test.txt
hadoop fs -tail /test.txt
9、下载多个文件在本地生成一个合并文件
hadoop fs -getmerge /test/*.dat ./xx.dat
客户端部署
修改core.site.xml文件
运行客户端命令
执行eclipse中HDFS的操作
1.1. HDFS安装常见问题:
-
主机名:不能带下划线: “_”
症状:启动失败,报错:there is not valid host:port 无效的主机名和端口号 -
输入hadoop命令,报错:command not found
原因是:linux查找命令执行的搜索机制
可以把hadoop命令所在的目录配入PATH环境变量
或者指定路径来执行这个命令 -
第一次启动前忘了初始化namenode的元数据目录
症状:namenode启动失败,报错:元数据目录不存在或者不可访问
storage directory does not exist or is not accessible. -
防火墙忘了关
症状:网页无法连接;
或者namenode不识别datanode -
启动datanode失败
报错:datanode上的clusterID与namenode上的clusterID不一致
原因: namenode再次被format后,生成了一个新的clusterID,导致与原来的datanode上的clusterID不一致
解决办法:将nn和dn上的clusterID修改一致
所谓的命令行客户端,是hadoop软件中自带的一个客户端程序,通过命令的形式来使用
客户端,该命令是:(老版本:hadoop fs) 新版本: hdfs dfs
客户端程序改在哪里运行呢? 客户端程序可以在任何机器上运行(集群内的机器、集群外的机器、linux、windows、mac),前提是,那个机器上安装了hadoop软件
注意: hadoop的命令行客户端,可以访问各种文件系统:本地文件系统
HDFS文件系统
亚马逊分布式文件系统
当你直接 hdfs dfs -ls /
它就不知道你要访问的是哪一个文件系统了!!!
默认访问的是本机的本地文件系统!
如果要访问一个指定的文件系统,需要在目标路径前加上这个文件系统的URI
URI : http://www.taobao.com:80/abc.html
jdbc:mysql://xx:3306/db1
hdfs://nn1.hdp:9000/
如果要让hdfs客户端默认就访问我们想指定的文件系统,那么就在core-site.xml配置文件中,覆盖一个参数:
fs.defaultFS = file:///
改成:
fs.defaultFS = hdfs://nn1.hdp:9000/
core-site.xml
fs.defaultFS
hdfs://nn1.hdp:9000/
命令行客户端文件操作命令:
文件夹:
创建文件夹:
hdfs dfs -mkdir /abc
hdfs dfs -mkdir -p /xx/yy
删除文件夹:
hdfs dfs -rm -r /xx
上传文件:
hdfs dfs -put /本地路径 /hdfs路径
下载文件:
hdfs dfs -get /abc/hadoop-2.8.5.tar.gz
下载到了本地的当前路径下
移动文件:
hdfs dfs -mv /abc/hadoop-2.8.5.tar.gz /
拷贝文件:
hdfs dfs -cp /hadoop-2.8.5.tar.gz /abc/hdp.tar.gz
读文件内容:
hdfs dfs -cat /a.txt
hdfs dfs -tail /a.txt
hdfs dfs -tail -f /a.txt
追加内容到已存在的文件:
hdfs dfs -appendToFile ./2.txt /a.txt
下载多个文件并在本地合并成一个文件:
hdfs dfs -getmerge /*.txt ./big.txt
修改指定文件的副本数量:
hdfs dfs -setrep 1 /a.txt
hdfs dfs客户端的命令大全:
Usage: hadoop fs [generic options]
[-appendToFile … ]
[-cat [-ignoreCrc] …]
[-checksum …]
[-chgrp [-R] GROUP PATH…]
[-chmod [-R] <MODE[,MODE]… | OCTALMODE> PATH…]
[-chown [-R] [OWNER][:[GROUP]] PATH…]
[-copyFromLocal [-f] [-p] [-l] [-d] … ]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] … ]
[-count [-q] [-h] [-v] [-t []] [-u] [-x]
[-cp [-f] [-p | -p[topax]] [-d] … ]
[-createSnapshot []]
[-deleteSnapshot ]
[-df [-h] [
[-du [-s] [-h] [-x]
[-expunge]
[-find
[-get [-f] [-p] [-ignoreCrc] [-crc] … ]
[-getfacl [-R]
[-getfattr [-R] {-n name | -d} [-e en]
[-getmerge [-nl] [-skip-empty-file] ]
[-help [cmd …]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [
[-mkdir [-p]
[-moveFromLocal … ]
[-moveToLocal ]
[-mv … ]
[-put [-f] [-p] [-l] [-d] … ]
[-renameSnapshot ]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] …]
[-rmdir [–ignore-fail-on-non-empty]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>}
[-setfattr {-n name [-v value] | -x name}
[-setrep [-R] [-w]
[-stat [format]
[-tail [-f] ]
[-test -[defsz]
[-text [-ignoreCrc] …]
[-touchz
[-truncate [-w]
[-usage [cmd …]]
HDFS运行机制的观察:
-
如果强行进入datanode的数据存储目录,删掉一个block块副本
发现:过一段时间后,namenode会指派拥有这个block副本的一台danode,将这个副本复制给另一台datanode,以恢复副本数量! -
如果将一个副本数量为3的文件,通过 setrep 命令将副本数量降低为2
发现:namenode会指派拥有这个文件的block的某些datanode,删除掉每一个block的一个副本 -
客户端上传到hdfs中的文件,确实被分块存储,而且是存在不同datanode服务器的data存储目录中;
-
如果文件的某个block副本全部丢失,namenode会发现,并在web console上汇报
解决办法: hdfs dfs -rm /这个坏了的文件
客户端补充:身份和权限问题:
客户端重要参数:
core-site.xml 默认访问的文件系统: fs.defaultFS = file:///(默认) hdfs://nn1.hdp:9000/
hdfs-site.xml上传文件模块切块大小: dfs.blocksize = 134217728(默认)
hdfs-site.xml 上传文件时请求的存储副本数量:dfs.replication = 3(默认)
身份和权限问题:
hdfs客户端,会先在系统中寻找一个变量HADOOP_USER_NAME的值作为访问身份,
比如,在linux系统中,使用命令行客户端,则可以提前设置该参数:
export HADOOP_USER_NAME=root
如果这个变量没有配置,则使用当前所在操作系统的登录用户名作为访问hdfs系统的客户端用户身份
你还可以修改hdfs上的文件夹或者文件的chmod,来添加访问权限;
hdfs dfs -chmod 777 /abc
@notrecommended
还可以关闭HDFS的权限验证:
dfs.permissions.enabled = true(默认值)
常用运维命令:
- namenode的安全模式管理:
namenode如果发现丢失的block数量超过0.1%时,会自动进入安全模式。
namenode也会自动退出安全模式;
如果namenode自动退出安全模式没有成功,可以用运维命令,强行退出安全模式:
强行进入安全模式:
hdfs dfsadmin -safemode enter
强行退出安全模式:
hdfs dfsadmin -safemode leave
scp hosts slave2:$PWD