文章目录
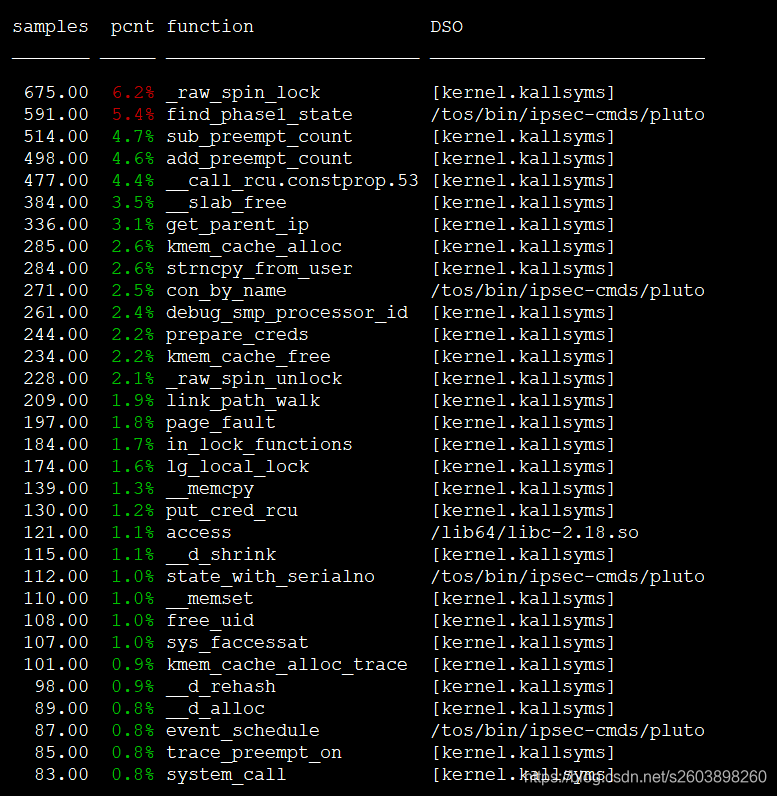
1 pluto中CPU占有率高的接口统计
1.0 list and resolution
| 序号 | 函数名称 | 原因 | 修改方案 |
|---|---|---|---|
| 1 | con_by_name() | 根据隧道名查询连接,遍历现有连接,效率太低 | 添加哈希表 |
| 2 | find_phase1_state() | 遍历所有的state, 找到最合适的状态。statetable[32]为哈希表;但是在此函数中没有起到效果 | 添加哈希表 |
| 3 | event_schedule() | 任务调用器。升序链表,每次需要头插法排序效率很低 | 需要更换任务调用模型(小根堆可考虑) |
| 4 | state_with_serialno() | 从状态中查询序号,需要逐个遍历 | 添加哈希表 |
| 5 | find_connection_by_reqid() | 遍历所有的连接,查找匹配的reqid | 添加哈希表 |
| 6 | delete_old_ipsec_sasp() | 每次生成一个IPSecSA后,需要遍历所有的SA 和SP,确保IPSecSA的唯一性 | 无 |
| 7 | 锁太大 | SADB, SPDB的锁太大 | 应该减小锁的作用范围。对于协商流程无益,因此暂不修改 |
| 8 | |||
| 9 |
openswan源码中的pluto进程在处理隧道数量比较少时效率问题没有那么突出,而当隧道增加到成千上万条时,它的性能问题显得格外的突出,表中便是当添加1万~2万条隧道时,CPU占有率的统计情况,然后将与pluto有关的接口单独列出。这几个接口效率比较低都有一个共同点:在搜索时都是无差别遍历所有的链表节点,因此当添加上万个隧道时性能下降很多。为了优化无差别遍历所有节点的问题,分别为不同类型的参数创建了哈希表,也就是说一个connnection链表或statetable哈希表存在多个哈希表结构(根据不同参数构建的哈希表),这在一定程度上能够提高搜索效率。下面分别对con_by_name, find_phase1_state, state_with_serialno, find_connection_by_reqid 接口按上述方案进行优化。
而event_schedule任务调度采用了升序链表的方式,在插入任务时,由于需要进行时间排序,节点很多时效率很低。优化方式通常是更换定时器,常见的高效并发定时器有时间轮、最小堆等实现方式。它们都是采用了散列的思想,在插入节点时避免因排序遍历整个链表,从而能节省时间提高定时器的效率。
1.1 con_by_name()接口优化
1.1.1 优化方案
在连接的单向链表的基础上添加一个hash表,通过连接的名字来获取hash值。
1.1.2 涉及的函数接口及变量:
| 序号 | 函数名称 | 说明 |
|---|---|---|
| 1 | #define CONNECTION_HASH 1024 | hash节点个数 |
| 2 | struct connection *conn_hash[CONNECTION_HASH]={NULL} | 连接哈希表 |
| 3 | get_hash_from_name() | 根据连接名称获取哈希值 |
| 4 | con_by_name() | 根据连接名字查询连接 |
| 5 | delete_connection() | 删除连接 |
| 6 | add_connection() | 添加连接 |
-
get_hash_from_name()
关于“采用何种hash方式才能保证散列均匀”这个问题,需要仔细斟酌和尝试,这里暂且使用比较简单的方式:对连接的名字(字符以及出现的位置)做hash运算。
实现如下:
static int get_hash_from_name(const char *name) { int i, len; unsigned int value = 0; if(!name){ return -1; } len = strlen(name); for(i=0;i<len;i++){ value += name[i] * i;/*how to calculate should be considered carefully*/ } return (int)(value % CONNECTION_HASH); } -
con_by_name()
源码中根据名字查询连接是通过遍历整个链表来实现的,当查询到此连接时,为了提高后续处理效率,将此连接节点移动到链表的头部。但是这样的查询方式效率依然比较低,为此,在单链表的基础上重新添加一个哈希表,通过对连接的名字取hash,然后再遍历该哈希节点下的链表,能够极大的提高效率。
struct connection * con_by_name(const char *nm, bool strict) { struct connection *p, *prev; int hash = get_hash_from_name(nm); if(hash < 0){ return NULL; } for (prev = NULL, p = conn_hash[hash]; ; prev = p, p = p->nh_next) { if (p == NULL) { if (strict) whack_log(RC_UNKNOWN_NAME , "no connection named \"%s\"", nm); break; } if (streq(p->name, nm) && (!strict || p->kind != CK_INSTANCE)) { if (prev != NULL) { prev->nh_next = p->nh_next; /* remove p from list */ p->nh_next = conn_hash[hash]; /* and stick it on front */ conn_hash[hash] = p; } break; } } return p; } -
delete_connection()
删除连接时,先将哈希表中的节点删除,然后再将该节点从连接的链表中删除。
void
delete_connection(struct connection *c, bool relations)
{
... ...
/* find and delete c from connections name hash list */
int nh = get_hash_from_name(c->name);
list_rm(struct connection, nh_next, c, conn_hash[nh]);
/* find and delete c from connections list */
list_rm(struct connection, ac_next, c, connections);
cur_connection = old_cur_connection;
... ...
pfree(c);
}
- add_connection()
在添加连接时,同时计算连接name的哈希值,然后添加到哈希表中。
void
add_connection(const struct whack_message *wm)
{
... ...
int nh = get_hash_from_name(c->name);
if(nh < 0){
openswan_log("Add connection get name hash error\n");
return;
}
c->nh_next = conn_hash[nh];
conn_hash[nh] = c;
... ...
}
1.2 find_phase1_state()接口优化
1.2.1 优化方案
在状态statetable的基础上再添加一个hash表,通过连接的主机对和保护子网来获取hash值构建哈希链表。
1.2.2 涉及的函数接口及变量:
| 序号 | 函数名称 | 说明 |
|---|---|---|
| 1 | #define STATE_TABLE_SIZE2 1024 | hash节点个数 |
| 2 | struct state *statetable_subnet[STATE_TABLE_SIZE2]; | 状态哈希表 |
| 3 | state_subnet_hash() | 根据子网主机对获取哈希值 |
| 4 | init_states() | 初始化哈希表 |
| 5 | insert_state() | 将状态插入到哈希表中 |
| 6 | unhash_state() | 将状态从哈希标移除 |
| 7 | find_phase1_state() | 查找第一阶段对应的最优状态 |
| 8 |
- state_subnet_hash()
对本段子网、对端子网、本地隧道地址、对端隧道地址求取哈希值,然后将其存储到statetable_subnet哈希表中。
实现如下:
/*state.c*/
int /* 0 for error */
get_mask_len(src)
const ip_address *src;
{
int n;
switch (src->u.v4.sin_family) {
case AF_INET:
n = 4;
break;
case AF_INET6:
n = 16;
break;
default:
return 0;
break;
}
return n;
}
int
get_ipaddr_hash(a, nbits, hashval)
const ip_address *a;
int nbits;
unsigned int *hashval;
{
unsigned char *ap;
size_t n;
char m = 0;
n = addrbytesptr(a, &ap);
if (n == 0)
return 0;
if (nbits > n*8)
return 0;
for (; nbits >= 8; nbits -= 8, ap++)
*hashval += *ap * nbits;
if (nbits > 0) {
m = ~(0xff >> nbits);
*hashval += *ap & m;
}
return 1;
}
int
get_subnet_hash(subnet, hashval)
const ip_subnet *subnet;
unsigned int *hashval;
{
return get_ipaddr_hash(subnet->addr, subnet->maskbits, hashval);
}
struct state **
state_seq_hash(so_serial_t seq)
{
unsigned long hashval = 0;
hashval = seq * 1311 % STATE_TABLE_SIZE2;
return &statetable_seq[hashval];
}
struct state **
state_subnet_hash(const struct connection *c)
{
unsigned int hashval_me, hashval_him, hashval_this, hashval_that, hashval;
int ret = 0;
hashval_me = hashval_him = hashval_this = hashval_that = hashval = 0;
if(!c || !c->host_pair){
return NULL;
}
get_ipaddr_hash(c->host_pair->me.addr, get_mask_len(c->host_pair->me.addr), &hashval_me) ;
get_ipaddr_hash(c->host_pair->him.addr, get_mask_len(c->host_pair->me.addr), &hashval_him) ;
get_subnet_hash(&(c->spd.this.client), &hashval_this);
get_subnet_hash(&(c->spd.that.client), &hashval_that);
hashval = ( hashval_me + hashval_him * 2 + hashval_this * 4 + hashval_that * 8 ) % STATE_TABLE_SIZE2;
DBG(DBG_CONTROL, DBG_log("state_subnet_hash hashval=%d", hashval));
return &statetable_subnet[hashval];
}
- init_states()
将三个哈希表依次完成初始化操作。
void
init_states(void)
{
int i;
for (i = 0; i < STATE_TABLE_SIZE; i++){
statetable[i] = (struct state *) NULL;
}
for (i = 0; i < STATE_TABLE_SIZE2; i++){
statetable_seq[i] = (struct state *) NULL;
statetable_subnet[i] = (struct state *)NULL;
}
}
- insert_state()
在插入状态时,分别将状态添加到statetable_subnet[]和statetable_seq[](后面优化接口时会用到)
void
insert_state(struct state *st)
{
struct state **p = state_hash(st->st_icookie, st->st_rcookie
, &st->st_connection->spd.that.host_addr);
passert(st->st_hashchain_prev == NULL && st->st_hashchain_next == NULL);
if (*p != NULL)
{
passert((*p)->st_hashchain_prev == NULL);
(*p)->st_hashchain_prev = st;
}
st->st_hashchain_next = *p;
*p = st;
/*Add by Sunzd for optimize states at 2020.08.06 begin*/
{
/*intset seq hash chain*/
passert(st->st_seq_hashchain_prev == NULL && st->st_seq_hashchain_next == NULL);
p = state_seq_hash(st->st_serialno);
if(NULL == p)
{
DBG(DBG_CONTROL, DBG_log("### ERROR: state_seq_hash IS NULL",st->st_serialno, (void *) st));
}else
{
if (*p != NULL)
{
passert((*p)->st_seq_hashchain_prev == NULL);
(*p)->st_seq_hashchain_prev = st;
}
st->st_seq_hashchain_next = *p;
*p = st;
}
}
{
/*intset subnet hash chain*/
passert(st->st_subnet_hashchain_prev == NULL && st->st_subnet_hashchain_next == NULL);
p = state_subnet_hash(st->st_connection);
if(NULL == p)
{
DBG(DBG_CONTROL, DBG_log("### ERROR: state_subnet_hash IS NULL",st->st_serialno, (void *) st));
}
else
{
if (*p != NULL){
passert((*p)->st_subnet_hashchain_prev == NULL);
(*p)->st_subnet_hashchain_prev = st;
}
st->st_subnet_hashchain_next = *p;
*p = st;
}
}
/*Add by Sunzd for optimize states at 2020.08.06 end*/
/* Ensure that somebody is in charge of killing this state:
* if no event is scheduled for it, schedule one to discard the state.
* If nothing goes wrong, this event will be replaced by
* a more appropriate one.
*/
if (st->st_event == NULL)
event_schedule(EVENT_SO_DISCARD, 0, st);
}
- unhash_state()
将state结构从状态哈希表中移除。
代码如下:
void
unhash_state(struct state *st)
{
/* unlink from forward chain */
#if 0
struct state **p = st->st_hashchain_prev == NULL
? state_hash(st->st_icookie, st->st_rcookie
, &st->st_connection->spd.that.host_addr)
: &st->st_hashchain_prev->st_hashchain_next;
#endif
struct state **p;
if(st->st_hashchain_prev == NULL) {
p = state_hash(st->st_icookie, st->st_rcookie, &st->st_connection->spd.that.host_addr);
if(*p != st) {
p = state_hash(st->st_icookie, zero_cookie, &st->st_connection->spd.that.host_addr);
}
} else {
p = &st->st_hashchain_prev->st_hashchain_next;
}
/* unlink from forward chain */
passert(*p == st);
*p = st->st_hashchain_next;
/* unlink from backward chain */
if (st->st_hashchain_next != NULL)
{
passert(st->st_hashchain_next->st_hashchain_prev == st);
st->st_hashchain_next->st_hashchain_prev = st->st_hashchain_prev;
}
st->st_hashchain_next = st->st_hashchain_prev = NULL;
/*Add by Sunzd for optimize states at 2020.08.06 begin*/
{
/*intset seq hash chain*/
passert(st->st_seq_hashchain_prev == NULL && st->st_seq_hashchain_next == NULL);
if(st->st_seq_hashchain_prev == NULL)
{
p = state_seq_hash(st->st_serialno);
}else
{
p = &st->st_seq_hashchain_prev->st_seq_hashchain_next;
}
/* unlink from forward chain */
passert(*p == st);
*p = st->st_seq_hashchain_next;
/* unlink from backward chain */
if (st->st_seq_hashchain_next != NULL)
{
passert(st->st_seq_hashchain_next->st_seq_hashchain_prev == st);
st->st_seq_hashchain_next->st_seq_hashchain_prev = st->st_seq_hashchain_prev;
}
st->st_seq_hashchain_next = st->st_seq_hashchain_prev = NULL;
}
{
/*intset subnet hash chain*/
passert(st->st_subnet_hashchain_prev == NULL && st->st_subnet_hashchain_next == NULL);
if(st->st_subnet_hashchain_prev == NULL)
{
p = state_subnet_hash(st->st_connection);
}else
{
p = &st->st_subnet_hashchain_prev->st_subnet_hashchain_next;
}
/* unlink from forward chain */
passert(*p == st);
*p = st->st_subnet_hashchain_next;
/* unlink from backward chain */
if (st->st_subnet_hashchain_next != NULL)
{
passert(st->st_subnet_hashchain_next->st_subnet_hashchain_prev == st);
st->st_subnet_hashchain_next->st_subnet_hashchain_prev = st->st_subnet_hashchain_prev;
}
st->st_subnet_hashchain_next = st->st_subnet_hashchain_prev = NULL;
}
/*Add by Sunzd for optimize states at 2020.08.06 end*/
}
- find_phase1_state()
根据连接查询第一阶段的状态时,对连接上的主机对和保护子网求取哈希值,然后将statetable_subnet[]中对应的头节点返回,然后依次遍历此链表节点进行精确匹配,从而提升搜索效率。
代码如下:
struct state *
find_phase1_state(const struct connection *c, lset_t ok_states)
{
openswan_log("in func:%s\n", __func__);
struct state
**st,
*best = NULL;
int i;
st = state_subnet_hash(c);
for (; *st != NULL; st = &(*st)->st_subnet_hashchain_next) {
openswan_log("find_phase1_state: c->name=[%s],type=[%d],st->name=[%s],type=[%d]",c->name, c->is_gmcon, (*st)->st_connection->name, (*st)->st_connection->is_gmcon);
if (LHAS(ok_states, (*st)->st_state)
&& c->host_pair == (*st)->st_connection->host_pair
&& same_peer_ids(c, (*st)->st_connection, NULL)
&& c->is_gmcon == (*st)->st_connection->is_gmcon
&& (best == NULL || best->st_serialno < (*st)->st_serialno))
{
best = (*st);
}
}
return best;
}
效果:
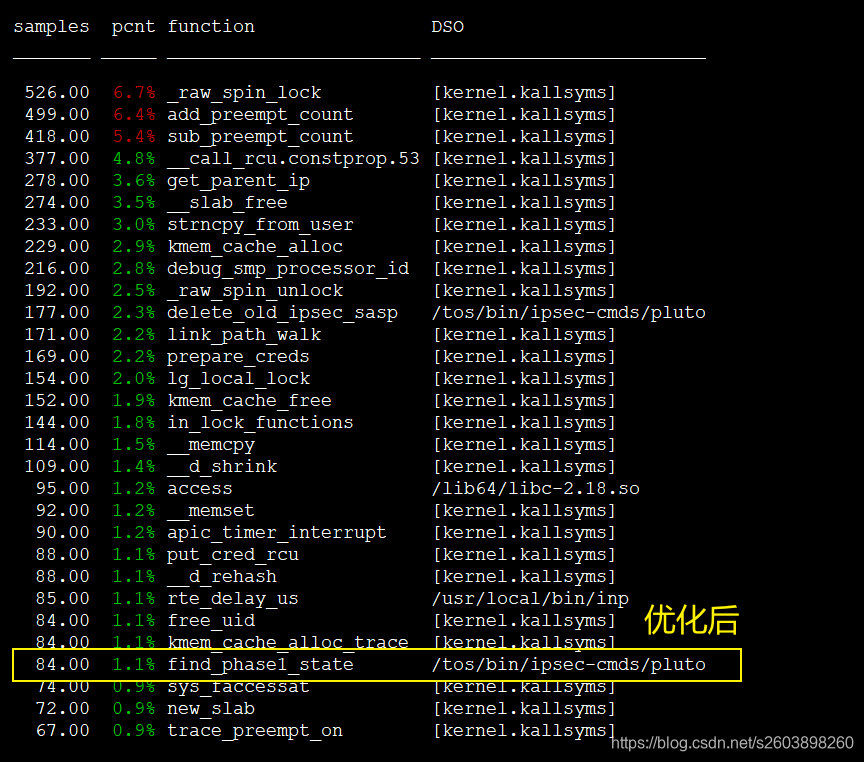
1.3 state_with_serialno()接口优化
1.3.1 优化方案
在原有的状态哈希表的基础上添加一个hash表,通过状态的序号来获取hash值。
- 此接口优化和find_phase1_state()函数都涉及到statetable[]哈希表,且优化的方式思路:根据不同的需求分别连接哈希表。
1.3.2 涉及的函数接口及变量:
| 序号 | 函数名称 | 说明 | 注 |
|---|---|---|---|
| 1 | #define STATE_TABLE_SIZE2 1024 | hash节点个数 | 同2.2章节 |
| 2 | struct state *statetable_subnet[STATE_TABLE_SIZE2]; | 序号哈希表 | |
| 3 | init_states() | 初始化哈希表 | 同2.2章节 |
| 4 | insert_state() | 将状态插入到哈希表中 | 同2.2章节 |
| 5 | unhash_state() | 将状态从哈希表中移除 | 同2.2章节 |
| 6 | state_seq_hash() | 根据序号计算hash值 | |
| 7 | state_with_serialno() | 根据序号找到状态 |
- state_seq_hash()
根据状态的序号获取哈希值。
代码实现如下:
struct state **
state_seq_hash(so_serial_t seq)
{
unsigned long hashval = 0;
hashval = seq * 1311 % STATE_TABLE_SIZE2;
return &statetable_seq[hashval];
}
- state_with_serialno()
根据状态的序号来查询对应的状态。
代码实现如下:
struct state *
state_with_serialno(so_serial_t sn)
{
if (sn >= SOS_FIRST)
{
struct state **st = state_seq_hash(sn);
for (; *st != NULL; st = &((*st)->st_hashchain_next)){
if ((*st)->st_serialno == sn)
return *st;
}
}
return NULL;
}
-
其他接口
参见
2.2 find_phase1_state()接口优化
1.4 find_connection_by_reqid()接口优化
1.4.1 优化方案
在原有的连接链表基础上添加一个hash表,通过reqid来获取hash值。
1.4.2 涉及的函数接口及变量:
| 序号 | 函数名称 | 说明 |
|---|---|---|
| 1 | #define CONNECTION_HASH 1024 | hash节点个数 |
| 2 | struct connection *conn_seq_hash[CONNECTION_HASH] = {NULL}; | 连接哈希表 |
| 3 | gen_reqid() | 根据连接id获取哈希值 |
| 4 | find_connection_by_reqid() | 根据连接id查询连接 |
| 5 | delete_connection() | 删除连接 |
| 6 | add_connection() | 添加连接 |
- gen_reqid()
根据reqid计算哈希值,注意在代码中发现有一个& ~3操作,就是说seqid的低两位无效,忽略。因此构建的哈希表仅有1/4个节点使用到。
代码实现如下:
static uint32_t
gen_reqid(void)
{
uint32_t start;
static uint32_t reqid = IPSEC_MANUAL_REQID_MAX & ~3;
start = reqid;
do {
reqid += 4;
if (reqid == 0)
reqid = (IPSEC_MANUAL_REQID_MAX & ~3) + 4;
if (!find_connection_by_reqid(reqid))
return reqid;
} while (reqid != start);
exit_log("unable to allocate reqid");
}
- find_connection_by_reqid()
根据连接的seqid来匹配连接。
代码实现如下:
struct connection *
find_connection_by_reqid(uint32_t reqid)
{
struct connection *c;
reqid &= ~3;
int nsh = get_hash_from_reqid(reqid);
for (c = conn_seq_hash[nsh]; c != NULL; c = c->nsh_next)
{
if (c->spd.reqid == reqid)
return c;
}
return NULL;
}
- add_connection()
在添加连接时,计算连接的seqid的哈希值,然后插入到对应的哈希链表中。(下面的代码中将conn_seq_hash,conn_hash哈希表插入都列出来了)。
代码实现如下:
void
add_connection(const struct whack_message *wm)
{
... ...
unsigned int nsh = get_hash_from_reqid(c->spd.reqid);
if(nsh > CONNECTION_HASH){
openswan_log("Add connection get seqid hash error\n");
return;
}
c->nsh_next = conn_seq_hash[nsh];
conn_seq_hash[nsh] = c;
/*---------------------------------------------------*/
int nh = get_hash_from_name(c->name);
if(nh < 0){
openswan_log("Add connection get name hash error\n");
return;
}
c->nh_next = conn_hash[nh];
conn_hash[nh] = c;
... ...
}
- delete_connection()
直接从对应的哈希表中移除该连接指针即可。
代码实现如下:
void
delete_connection(struct connection *c, bool relations)
{
... ...
/* find and delete c from connections seqid hash list */
int nsh = get_hash_from_reqid(c->name);
list_rm(struct connection, nsh_next, c, conn_seq_hash[nsh]);
/* find and delete c from connections name hash list */
int nh = get_hash_from_name(c->name);
list_rm(struct connection, nh_next, c, conn_hash[nh]);
... ...
}