爬虫心得《第一篇》
一、 爬虫介绍
爬虫是一种自动获取网页内容的程序,是搜索引擎的重要组成部分。网络爬虫为搜索引擎从万维网下载网页。一般分为传统爬虫和聚焦爬虫
二、爬虫步骤
- 分析网页结构
- 请求网页数据链接
- 解析网页和数据元素
- 数据清洗和可视化分析
- 保存数据
三、案列《以南京出租房举例》
1.爬虫环境
- python
python下载链接 - pycharm
pycharm下载链接 - mysql
mysql下载链接
2.爬虫网站
- 网站链接
- 主页面
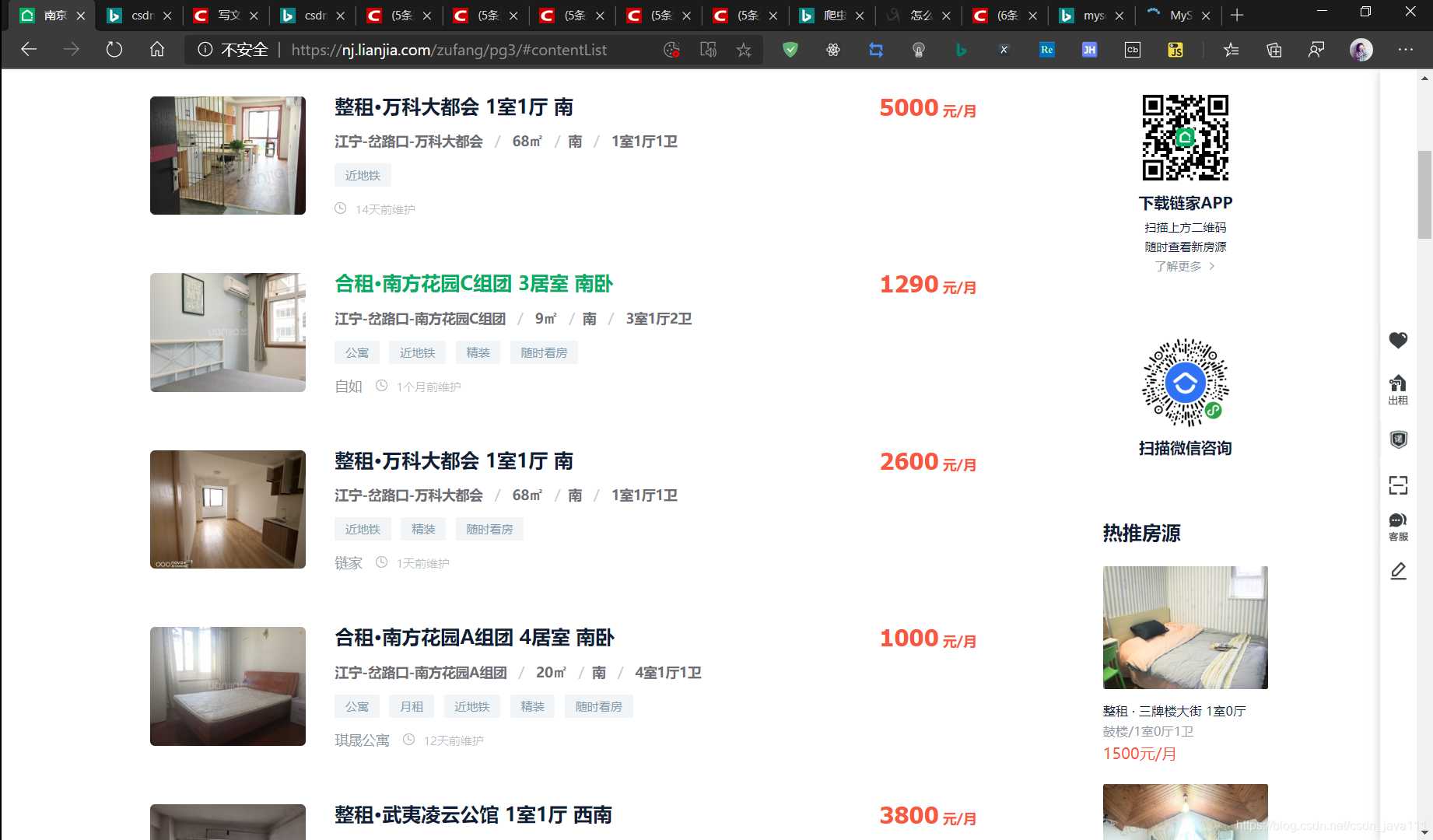
- 详情页
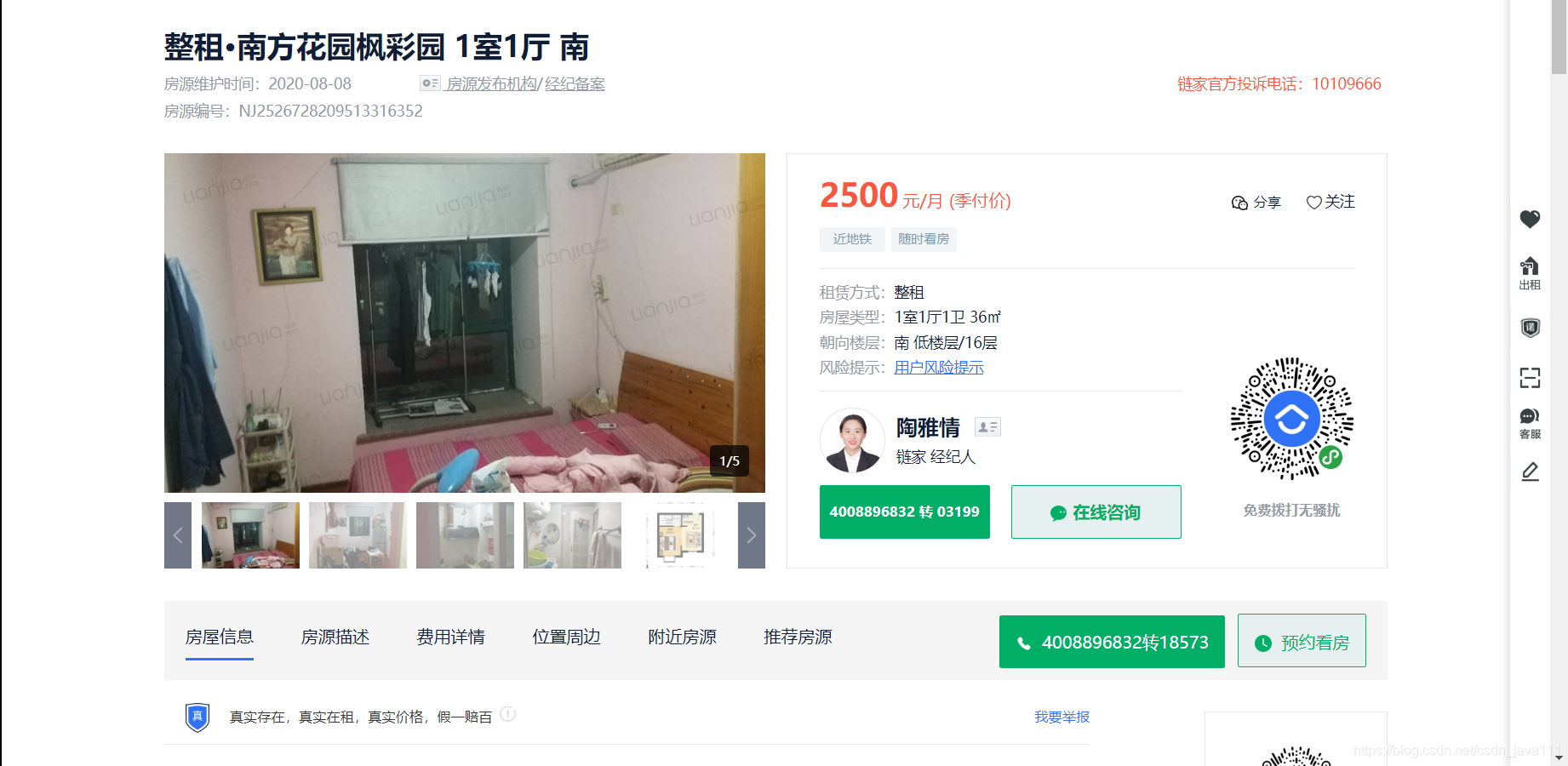
分析详情网站
- 需求分析
我们需要抓取它的房源、租期、入住、价格、面积、朝向、楼层、电梯、车位、维护 - 解析网页
#可以使用 lxml、BeautifulSoup
列如:
dom=etree.HTML(resp)
soup =BeautifulSoup(resp,'html.parser')
- 定位元素
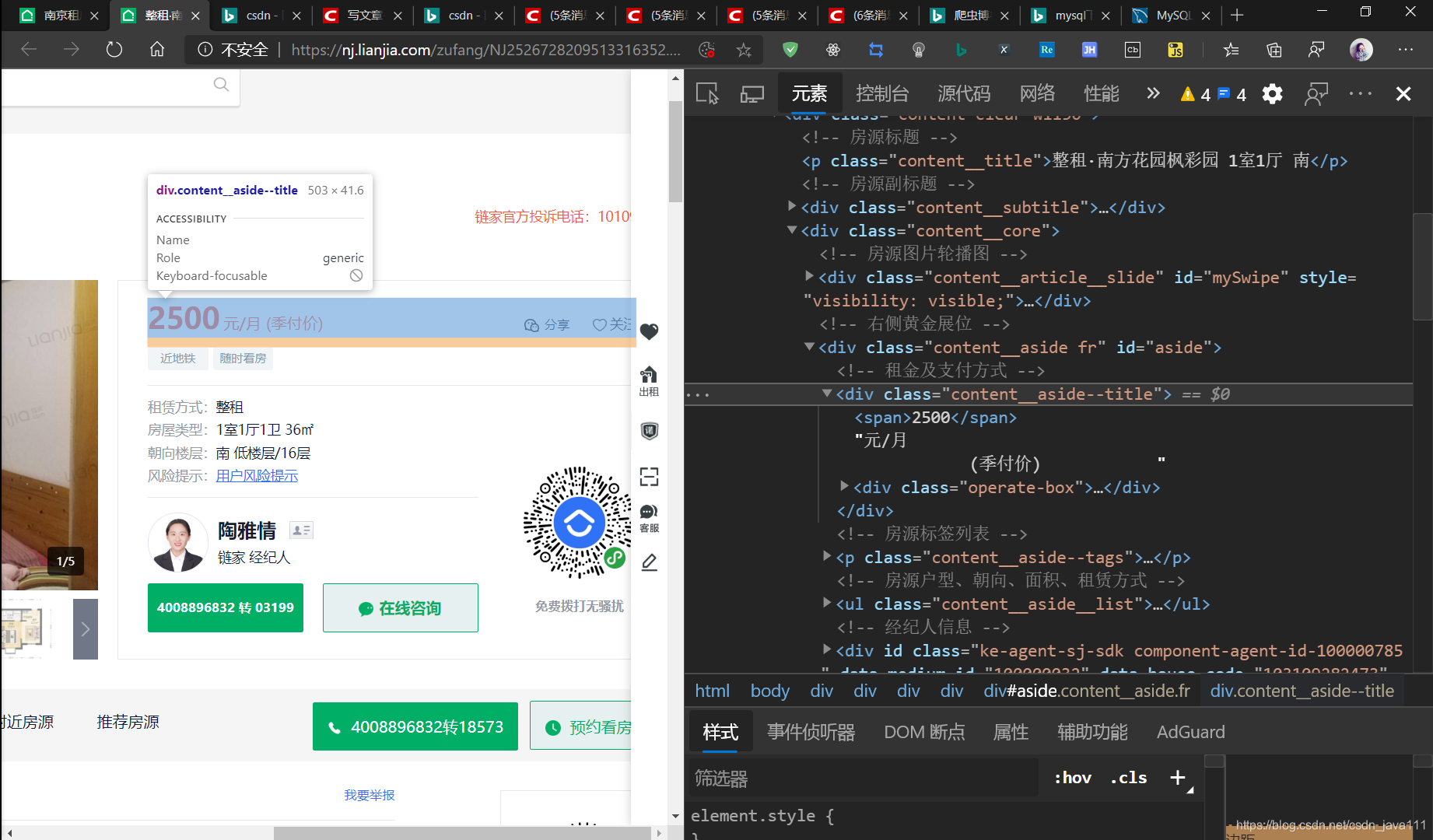
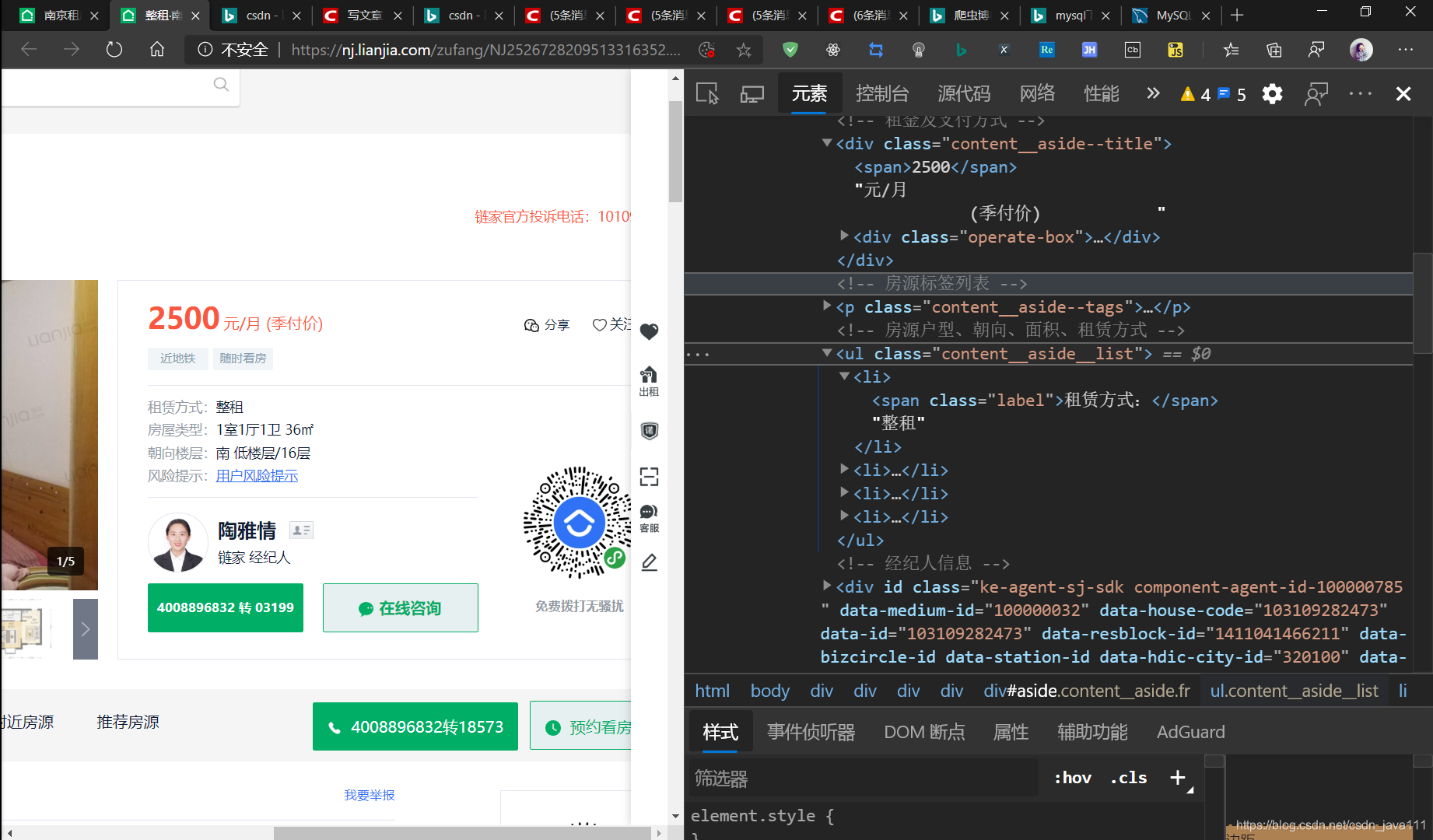
#可以使用 xpath、re、BeautifulSoup
我这里使用的BeautifulSoup进行定位的:
price = soup.find('div', class_="content__aside--title").span.text + '{}'.format("元/月")
# li=soup.find('ul',class_="content__aside__list")
ul = soup.find_all('li', class_="fl oneline")
# 房源
housingMenu = soup.find('p', class_="content__title").text
# 朝向
floorRound = ul[2].text[3:]
# 面积
zoomarea = ul[1].text[3:]
# 维护
maintain = ul[4].text[3:]
# 入住
domain = ul[5].text[3:]
# 楼层
floor = ul[7].text[3:]
# 电梯
elevator = ul[8].text[3:]
# 车位
parkingspace = ul[10].text[3:]
# 租期
leases = ul[18].text[3:]
- 数据清洗
#我这里把数据装成了字典,一边后面拿出来
info={
'房源': housingMenu,
'租期': leases,
'入住': domain,
'价格': price,
'面积': zoomarea,
'朝向': floorRound,
'楼层': floor,
'电梯': elevator,
'车位': parkingspace,
'维护': maintain
}
- 保存数据
#我这里是把他保存到数据库里
def insert_data(db,house):
values = "'{}'," *9 + "'{}'"
sql_values = values.format(
house['房源'],house['价格'],house['入住'],house['租期'],house['面积'],
house['朝向'],house['楼层'],house['电梯'],house[ '车位'],house['维护'])
sql = '''insert into `housingconnections`(`房源`,`价格`,`入住`,`租期`,`面积`,`朝向`,`楼层`,`电梯`,`车位`,`维护`)
values({});
'''.format(sql_values)
cursor=db.cursor()
cursor.execute(sql)
db.commit()
分析主网站


'''
https://nj.lianjia.com/zufang/pg1/#contentList
https://nj.lianjia.com/zufang/pg2/#contentList
'''
分析链接,爬取多个页面,以抓取十页为例
可以用 %、format
例如:
url='https://nj.lianjia.com/zufang/pg{}/#contentList'
for i in range(1,11):
url.format(i)
for i in range(1,11):
url='https://nj.lianjia.com/zufang/pg%d/#contentList'%i
如果不理解什么意思可参考:菜鸟教程格式化字符
3.数据库操作
- 连接数据库
连接数据库首先要开启服务:
net start mysql
关闭服务是:net stop mysql
可以手动进行开启:去搜索框去输入服务找到mysql或者快捷键
win+R 输入 services.msc找到mysql进行开启
- 创建数据库和表
create database "数据库名"
create table `表名`
- 我的数据库语句
CREATE TABLE `housingconnections` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`房源` varchar(50) DEFAULT NULL,
`价格` varchar(50) DEFAULT NULL,
`入住` varchar(50) DEFAULT NULL,
`租期` varchar(50) DEFAULT NULL,
`面积` varchar(50) DEFAULT NULL,
`朝向` varchar(50) DEFAULT NULL,
`楼层` varchar(50) DEFAULT NULL,
`电梯` varchar(20) DEFAULT NULL,
`车位` varchar(50) DEFAULT NULL,
`维护` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
'''
以id为主键(primary key)
其中AUTO_INCREMENT 是自动递增的意思
字符集:ENGINE=InnoDB DEFAULT CHARSET=utf8
'''
- python操作数据库
'''
我这里使用的是MySQLdb
查询、插入、更新、删除都必须要设立游标
cursor=db.cursor()
运行sql语句
cursor.execute(sql)
'''
1.连接数据库
database={
'host':'127.0.0.1',
'user':'root',
'password':'root',
'db':'es'
}
db=MySQLdb.connect(host='localhost',user='root',password='root',db='es')
#等价于
db=MySQLdb.connect('localhost','root','root','es')
# 等价于
db=MySQLdb.connect(**database)
2.数据库查询
sql='select * from class'
3.数据库插入
sql="insert into `class` (`id`, `name`) values ('124', 'chen');"
4.数据库更新
sql="update `class` set `name`='chng' where `id`='123' "
5.数据库删除
sql="delete from `class` where `id`='127'"
4.python代码解释
- 导入第三方库
import requests
from bs4 import BeautifulSoup
import threading
import MySQLdb
import time
import re
'''
python之所以强大,是因为它的第三方库强大。
可以使用 pip、conda
以request为例
前提:python加入了环境变量,这里就不细说了
命令行输入:快捷键 win + R 输入cmd然后回车
pip install requests
conda install requests
下图展示:我这里是之前装好了
'''
- 请求网页链接
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36 Edg/84.0.522.52"
}
def get_page(url):
resp = requests.get(url, headers=headers).text
soup =BeautifulSoup(resp,'html.parser')
return soup
'''
为了防止反爬构造请求头headers
这个网站可以不需要,已经测试过了。
'''
- 获取多个页面
def get_link(link_url):
soup=get_page(link_url)
links_div = soup.find_all('a', class_="content__list--item--aside")
links = ['{}'.format("https://nj.lianjia.com/") + div.get('href') for div in links_div]
return links
'''
列表表达式非常方便可以试着用一用
['{}'.format("https://nj.lianjia.com/") + div.get('href') for div in links_div]
'''
- 主程序开关
if __name__ == '__main__':
s=time.time()
db=open_sql(database)
count = 0
for i in range(1,10):
url='https://nj.lianjia.com/zufang/pg{}/#contentList'
links=get_link(url.format(i))
for link in links:
time.sleep(3)
count+=1
print('第{}条数据保存成功'.format(count))
house=parser_page(link)
process = threading.Thread(target=insert_data,args=(db,house))
process.start()
e=time.time()
print('**************{}条数据保存成功'.format(count),"用时:",e-s)
测试过程中出错处理
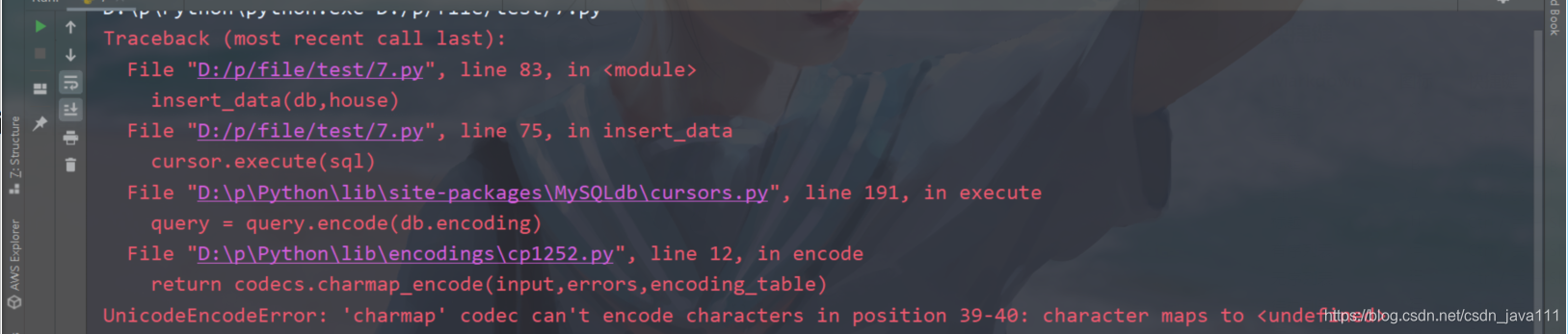
database={
'host': '127.0.0.1',
'user': 'root',
'password': 'root',
'db': 'house',
'charset': 'utf8'
}
'''
需要加入字符集utf8
'''
5.效果展示
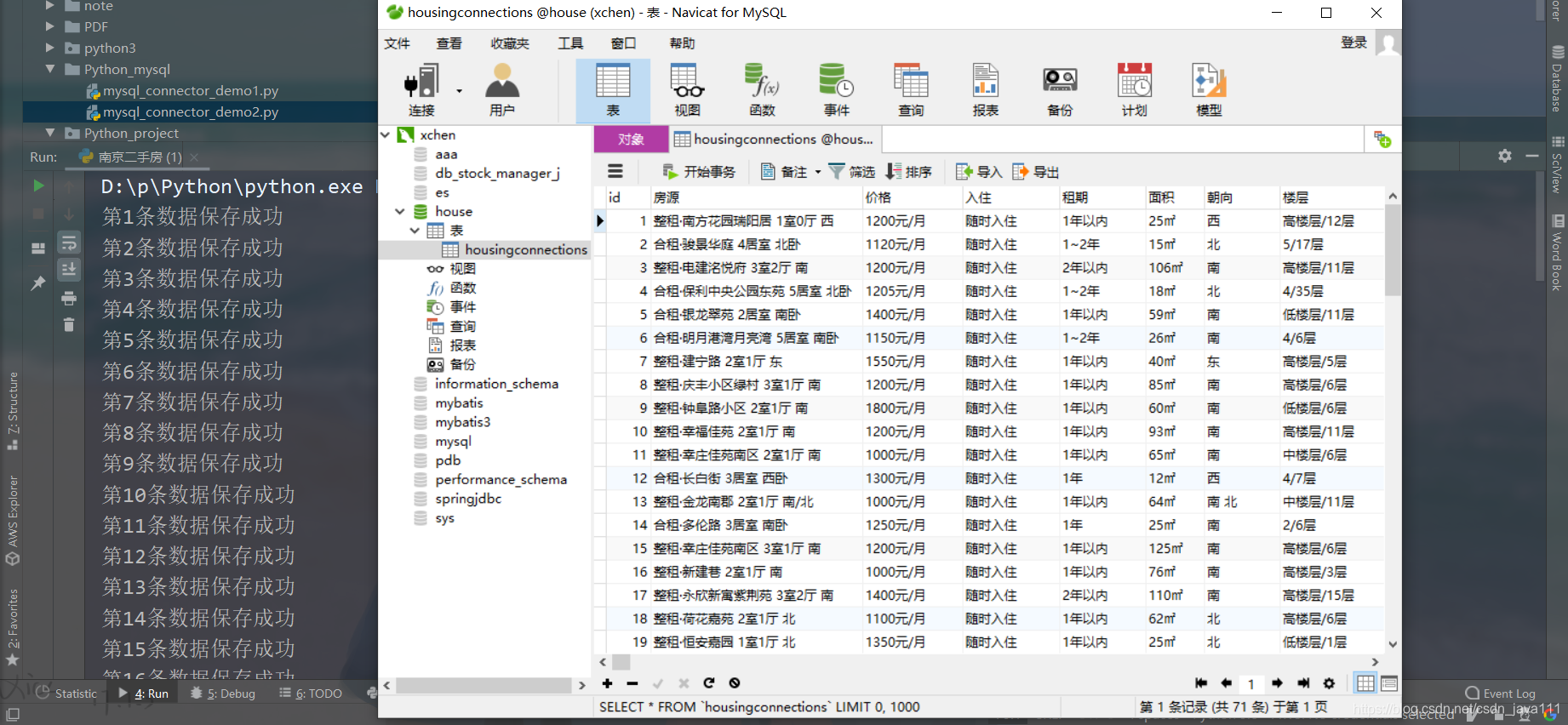
6.源代码展示
# -*- coding: utf-8 -*-
"""
@File : 南京二手房.py
@Time : 2020/8/8 21:00
@Author : xchen-IT
@Email : [email protected]
@Software: PyCharm
"""
import requests
from bs4 import BeautifulSoup
import threading
import MySQLdb
import time
import re
thread_process=threading.BoundedSemaphore(value=10)
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36 Edg/84.0.522.52"
}
def get_page(url):
resp = requests.get(url, headers=headers).text
soup =BeautifulSoup(resp,'html.parser')
return soup
def get_link(link_url):
soup=get_page(link_url)
links_div = soup.find_all('a', class_="content__list--item--aside")
links = ['{}'.format("https://nj.lianjia.com/") + div.get('href') for div in links_div]
return links
def parser_page(house_url):
soup=get_page(house_url)
price = soup.find('div', class_="content__aside--title").span.text + '{}'.format("元/月")
# li=soup.find('ul',class_="content__aside__list")
ul = soup.find_all('li', class_="fl oneline")
# 房源
housingMenu = soup.find('p', class_="content__title").text
# 朝向
floorRound = ul[2].text[3:]
# 面积
zoomarea = ul[1].text[3:]
# 维护
maintain = ul[4].text[3:]
# 入住
domain = ul[5].text[3:]
# 楼层
floor = ul[7].text[3:]
# 电梯
elevator = ul[8].text[3:]
# 车位
parkingspace = ul[10].text[3:]
# 租期
leases = ul[18].text[3:]
info={
'房源': housingMenu,
'租期': leases,
'入住': domain,
'价格': price,
'面积': zoomarea,
'朝向': floorRound,
'楼层': floor,
'电梯': elevator,
'车位': parkingspace,
'维护': maintain
}
return info
database={
'host': '127.0.0.1',
'user': 'root',
'password': 'root',
'db': 'house',
'charset': 'utf8'
}
def open_sql(setting):
return MySQLdb.connect(**setting)
def insert_data(db,house):
values = "'{}'," *9 + "'{}'"
sql_values = values.format(
house['房源'],house['价格'],house['入住'],house['租期'],house['面积'],
house['朝向'],house['楼层'],house['电梯'],house[ '车位'],house['维护'])
sql = '''insert into `housingconnections`(`房源`,`价格`,`入住`,`租期`,`面积`,`朝向`,`楼层`,`电梯`,`车位`,`维护`)
values({});
'''.format(sql_values)
cursor=db.cursor()
cursor.execute(sql)
db.commit()
if __name__ == '__main__':
s=time.time()
db=open_sql(database)
count = 0
for i in range(1,10):
url='https://nj.lianjia.com/zufang/pg{}/#contentList'
links=get_link(url.format(i))
for link in links:
time.sleep(3)
count+=1
print('第{}条数据保存成功'.format(count))
house=parser_page(link)
process = threading.Thread(target=insert_data,args=(db,house))
process.start()
e=time.time()
print('**************{}条数据保存成功'.format(count),"用时:",e-s)
'''
分析url
https://nj.lianjia.com/zufang/pg1/#contentList
'''
结束语:博主第一次写博客,望多多指教。。。