1.OCR技术汇总
我尝试了如下方法,总的来说,OCR一般包括三步,分别是文字方向检测、文字区域识别、文字识别。目前神经网络可以很好的完成文字识别了,只是需要大量的样本进行训练,如果全世界的语言都能做到的话,那量就非常大,一种语音的模型大小差不多就1G左右。最后一步(文字识别)用CRNN就能做到很好的效果,基本可以达到商用标准,不过要优化下速度或者机器要很高的配置。
1.1 Tesseract
Tesseract是惠普布里斯托实验室在1985到1995年间开发的一一个开源的OCR引擎,曾经在1995 UNLV精确度测试中名列前茅。但1996年后基本停止了开发。2005年,惠普将其对外开源,2006 由Google对Tesseract进行改进、消除Bug、优化工作。目前项目地址为: https://github.com/tesseract-ocr/tesseract。
它与Leptonica图片处理库结合,可以读取各种格式的图像并将它们转化成超过60种语言的文本,我们还可以不断训练自己的库,使图像转换文本的能力不断增强。
Tesseract 4增加了LSTM,主要用来进行线识别,下面有说到文本线。
总的来说Tesseract 是基于字符方面的识别,尤其是多边形近似法,识别步骤是step by step的。以前传统的特征识别方法,不是卷积神经网络的。
1.2 Recursive Recurrent Nets with Attention Modeling for OCR in the Wild
Recursive Recurrent Nets with Attention Modeling for OCR in the Wild,该模型有三部分组成,分别是recursive CNN、RNN(Recurrent neural net work)、soft attention model。recursive CNN用于图片encoding(图片特征提取),RNN用于字符水平的语言模型,attention 关注更好的图片特征使用。
同时本模型不用基于字典。
总结,该模型没有用CTC,所以只识别单个单词。不过可以在最后结合CTC识别长字符,多个单词。本模型和CRNN类似,CRNN是CNN+RNN(LSTM)+CTC。
1.3 CTPN+CRNN
一共分为3个网络
1. 文本方向检测网络-Classify(vgg16)
2. 文本区域检测网络-CTPN(CNN+RNN)
3. EndToEnd文本识别网络-CRNN(CNN+GRU/LSTM+CTC)
1.4 Chineseocr:YOLO3+CRNN
Git地址:https://github.com/chineseocr/chineseocr。目前支持darknet、keras、tensorflow、pytorch。但将来会主要支持darknet。Yolo3开始就是用darknet编写的。
基于yolo3 与crnn 实现中文自然场景文字检测及识别。我试的身份证识别效果很好。主要是CRNN训练的很好。
YOLO3:目标检测。
CRNN: EndToEnd文本识别网络-CRNN(CNN+GRU/LSTM+CTC)
2.文字区域识别技术汇总
2.1 YOLO3-目标检测
YOLO将输入图像分成SxS个格子,若某个物体 Ground truth 的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这个物体。
“分而治之”,从yolo_v1开始,yolo算法就是通过划分单元格来做检测,只是划分的数量不一样。
采用"leaky ReLU"作为激活函数。
端到端进行训练。一个loss function搞定训练,只需关注输入端和输出端。
从yolo_v2开始,yolo就用batch normalization作为正则化、加速收敛和避免过拟合的方法,把BN层和leaky relu层接到每一层卷积层之后。
多尺度训练。在速度和准确率之间tradeoff。想速度快点,可以牺牲准确率;想准确率高点儿,可以牺牲一点速度。
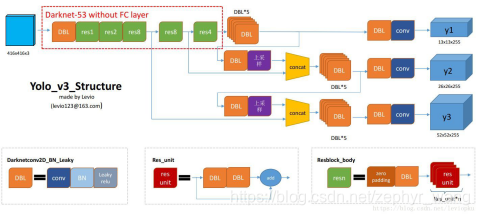
DBL: 如图1左下角所示,也就是代码中的Darknetconv2d_BN_Leaky,是yolo_v3的基本组件。就是卷积+BN+Leaky relu。对于v3来说,BN和leaky relu已经是和卷积层不可分离的部分了(最后一层卷积除外),共同构成了最小组件。
resn:n代表数字,有res1,res2, … ,res8等等,表示这个res_block里含有多少个res_unit。这是yolo_v3的大组件,yolo_v3开始借鉴了ResNet的残差结构,使用这种结构可以让网络结构更深(从v2的darknet-19上升到v3的darknet-53,前者没有残差结构)。对于res_block的解释,可以在图1的右下角直观看到,其基本组件也是DBL。
concat:张量拼接。将darknet中间层和后面的某一层的上采样进行拼接。拼接的操作和残差层add的操作是不一样的,拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变。
2.2 PSENet
PSENet(Progressive Scale Expansion Network)称为渐进尺度扩展网络,主要是进行任意形状的文字定位,比如弯曲的。可以处理不同的光照条件、不同的颜色、不同的尺度大小。甚至可以处理文字区域非常接近,以及有部分重合的图片。
2.3 CTPN
CTPN模型主要包括三个部分,分别是卷积层、Bi-LSTM层、全连接层.
1.通过识别一系列小框框文字,分别给于文字分数、非文字分数,然后将他们结合在一起进行预测。
2.In-network 循环网络直接应用于卷积神经网络提取的图片特征。
3.可以同时处理一张图片中的多个文字,以及同时处理多种语音文字。
4.速度、精度都高,0.88 F-measure over 0.834 on the ICDAR 2013, and 0.61 F-measure over 0.54 in on the ICDAR 2015。速度达到0.14s/image。