前言
我的另外一篇基于tensorflow的迁移学习文章:AI实战:迁移学习之使用ResNet做分类
本文介绍pytorch版DenseNet迁移学习。
本质:迁移学习到的是特征。
DenseNet
Dense Convolutional Network
-
DenseNet的优点
1.减轻了梯度消失
2.加强了feature的传递
3.加强了feature的重用
4.一定程度上减少了参数数列
-
Dense Block
核心思想是Dense Block,在每一个Dense Block中,任何两层之间都有直接的连接,也就是说,网络每一层的输入都是前面所有层输出的并集,而该层所学习的特征图也会被直接传给其后面所有层作为输入。通过密集连接,缓解梯度消失问题,加强特征传播,鼓励特征复用,极大的减少了参数量。
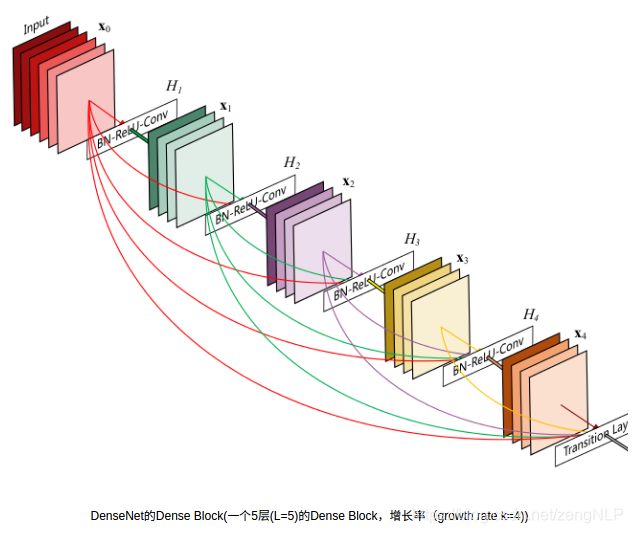 两个Dense Block之间使用Batch+1x1Conv+2x2AvgPool作为transition layer的方式来匹配特征图的尺寸。 这样就充分利用了学习的特征图,而不会使用零填充来增加不必要的外在噪声,或者使用1x1Conv+stride=2来采样已学习到的特征(stride=2会丢失部分学习的特征)。
两个Dense Block之间使用Batch+1x1Conv+2x2AvgPool作为transition layer的方式来匹配特征图的尺寸。 这样就充分利用了学习的特征图,而不会使用零填充来增加不必要的外在噪声,或者使用1x1Conv+stride=2来采样已学习到的特征(stride=2会丢失部分学习的特征)。 -
DenseNet的主体框架

在每个Dense Block内部采用了密集连接,而在相邻的Dense Block之间采用的时Conv+Pool的方式
加载预训练模型
- 特征层 model.features
- 分类层 model.classifier
构建base model,作为特征层
model = models.densenet121(pretrained=True)
其他的网络可以参考: https://pytorch.org/docs/0.3.0/torchvision/models.html#torchvision-models
环境
- Ubuntu 16.04
- torch 1.2.0
- torchvision 0.4.0
代码
import argparse
import numpy
import os
import shutil
import time
from PIL import Image
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.distributed as dist
import torch.optim
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torchvision.models as models
# Load all model arch available on Pytorch
model_names = sorted(name for name in models.__dict__
if name.islower() and not name.startswith("__")
and callable(models.__dict__[name]))
parser = argparse.ArgumentParser(description='PyTorch ImageNet Training')
parser.add_argument('--data', default='./input', metavar='DIR',
help='path to dataset')
parser.add_argument('--outf', default='./output',
help='folder to output model checkpoints')
parser.add_argument('--evalf', default="./eval" ,help='path to evaluate sample')
parser.add_argument('--arch', '-a', metavar='ARCH', default='densenet201',
choices=model_names,
help='model architecture: ' +
' | '.join(model_names) +
' (default: resnet18)')
parser.add_argument('-j', '--workers', default=4, type=int, metavar='N',
help='number of data loading workers (default: 4)')
parser.add_argument('--epochs', default=90, type=int, metavar='N',
help='number of total epochs to run')
parser.add_argument('--start-epoch', default=0, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('-b', '--batch-size', default=256, type=int,
metavar='N', help='mini-batch size (default: 256)')
parser.add_argument('--lr', '--learning-rate', default=0.1, type=float,
metavar='LR', help='initial learning rate')
parser.add_argument('--momentum', default=0.9, type=float, metavar='M',
help='momentum')
parser.add_argument('--weight-decay', '--wd', default=1e-4, type=float,
metavar='W', help='weight decay (default: 1e-4)')
parser.add_argument('--print-freq', '-p', default=10, type=int,
metavar='N', help='print frequency (default: 10)')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='path to latest checkpoint (default: none)')
parser.add_argument('-e', '--evaluate', dest='evaluate', action='store_true',
help='evaluate model on validation set')
parser.add_argument('--train', action='store_true',
help='train the model')
parser.add_argument('--test', action='store_true',
help='test a [pre]trained model on new images')
parser.add_argument('-t', '--fine-tuning', action='store_true',
help='transfer learning + fine tuning - train only the last FC layer.')
parser.add_argument('--pretrained', dest='pretrained', action='store_true',
help='use pre-trained model')
parser.add_argument('--world-size', default=1, type=int,
help='number of distributed processes')
parser.add_argument('--dist-url', default='tcp://224.66.41.62:23456', type=str,
help='url used to set up distributed training')
parser.add_argument('--dist-backend', default='gloo', type=str,
help='distributed backend')
best_prec1 = torch.FloatTensor([0])
def get_images_name(folder):
"""Create a generator to list images name at evaluation time"""
onlyfiles = [f for f in os.listdir(folder) if os.path.isfile(os.path.join(folder, f))]
for f in onlyfiles:
yield f
def pil_loader(path):
"""Load images from /eval/ subfolder and resized it as squared"""
with open(path, 'rb') as f:
with Image.open(f) as img:
sqrWidth = numpy.ceil(numpy.sqrt(img.size[0]*img.size[1])).astype(int)
return img.resize((sqrWidth, sqrWidth))
def main():
global args, best_prec1, cuda, labels
args = parser.parse_args()
try:
os.makedirs(args.outf)
except OSError:
pass
cuda = torch.cuda.is_available()
print ("=> using cuda: {cuda}".format(cuda=cuda))
args.distributed = args.world_size > 1
print ("=> distributed training: {dist}".format(dist=args.distributed))
############ DATA PREPROCESSING ############
# Data loading code
traindir = os.path.join(args.data, 'train')
valdir = os.path.join(args.data, 'val')
testdir = args.evalf
# Normalize on RGB Value
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
# Size on model
size = (224, 256)
# Train -> Preprocessing -> Tensor
train_dataset = datasets.ImageFolder(
traindir,
transforms.Compose([
transforms.RandomSizedCrop(size[0]),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
]))
print ('classes:', train_dataset.classes)
# Get number of labels
labels = len(train_dataset.classes)
if args.distributed:
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
else:
train_sampler = None
# Pin memory
if cuda:
pin_memory = True
else:
pin_memory = False
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=args.batch_size, shuffle=(train_sampler is None),
num_workers=args.workers, pin_memory=pin_memory, sampler=train_sampler)
# Validate -> Preprocessing -> Tensor
val_loader = torch.utils.data.DataLoader(
datasets.ImageFolder(valdir, transforms.Compose([
transforms.Scale(size[1]), # 256
transforms.CenterCrop(size[0]), # 224 , 299
transforms.ToTensor(),
normalize,
])),
batch_size=args.batch_size, shuffle=False,
num_workers=args.workers, pin_memory=pin_memory)
if args.test:
# Testing -> Preprocessing -> Tensor
test_loader = torch.utils.data.DataLoader(
datasets.ImageFolder(testdir, transforms.Compose([
transforms.Scale(size[1]), # 256
transforms.CenterCrop(size[0]), # 224 , 299
transforms.ToTensor(),
normalize,
]), loader=pil_loader),
batch_size=1, shuffle=False,
num_workers=args.workers, pin_memory=pin_memory)
############ BUILD MODEL ############
if args.distributed:
dist.init_process_group(backend=args.dist_backend, init_method=args.dist_url,
world_size=args.world_size)
# Create model from scratch or use a pretrained one
if args.pretrained:
print("=> using pre-trained model '{}'".format(args.arch))
model = models.__dict__[args.arch](pretrained=True)
# print(model)
else:
print("=> creating model '{}'".format(args.arch))
model = models.__dict__[args.arch](num_classes=labels)
# print(model)
# Freeze model, train only the last FC layer for the transfered task
if args.fine_tuning:
print("=> transfer-learning mode + fine-tuning (train only the last FC layer)")
# Freeze Previous Layers(now we are using them as features extractor)
for param in model.parameters():
param.requires_grad = False
# Fine Tuning the last Layer For the new task
# RESNET
if args.arch == 'densenet121': # DENSENET
model.classifier = nn.Linear(1024, labels)
parameters = model.classifier.parameters()
# print(model)
elif args.arch == 'densenet201': # DENSENET
model.classifier = nn.Linear(1920, labels)
parameters = model.classifier.parameters()
# print(model)
else:# densenet161 | densenet169 按照上面方法修改即可
print("Error: Fine-tuning is not supported on this architecture.")
exit(-1)
else:
parameters = model.parameters()
# Define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss()
if cuda:
criterion.cuda()
# Set SGD + Momentum
optimizer = torch.optim.SGD(parameters, args.lr,
momentum=args.momentum,
weight_decay=args.weight_decay)
# optionally resume from a checkpoint
if args.resume:
if os.path.isfile(args.resume):
print("=> loading checkpoint '{}'".format(args.resume))
if cuda:
checkpoint = torch.load(args.resume)
else:
# Load GPU model on CPU
checkpoint = torch.load(args.resume, map_location=lambda storage, loc: storage)
args.start_epoch = checkpoint['epoch']
best_prec1 = checkpoint['best_prec1']
model.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
print("=> loaded checkpoint '{}' (epoch {})"
.format(args.resume, checkpoint['epoch']))
else:
print("=> no checkpoint found at '{}'".format(args.resume))
# Load model
if cuda:
model.cuda()
else:
model.cpu()
############ TRAIN/EVAL/TEST ############
cudnn.benchmark = True
# Evaluate
if args.evaluate:
print("=> evaluating...")
validate(val_loader, model, criterion)
return
# Testing
if args.test:
print("=> testing...")
# Name generator
names = get_images_name(os.path.join(testdir, 'images'))
test(test_loader, model, names, train_dataset.classes)
return
# Training
if args.train:
print("=> training...")
for epoch in range(args.start_epoch, args.epochs):
if args.distributed:
train_sampler.set_epoch(epoch)
adjust_learning_rate(optimizer, epoch)
# Train for one epoch
train(train_loader, model, criterion, optimizer, epoch)
# Evaluate on validation set
prec1 = validate(val_loader, model, criterion)
# Remember best prec@1 and save checkpoint
if cuda:
prec1 = prec1.cpu() # Load on CPU if CUDA
# Get bool not ByteTensor
is_best = bool(prec1.numpy() > best_prec1.numpy())
# Get greater Tensor
best_prec1 = torch.FloatTensor(max(prec1.numpy(), best_prec1.numpy()))
save_checkpoint({
'epoch': epoch + 1,
'arch': args.arch,
'state_dict': model.state_dict(),
'best_prec1': best_prec1,
'optimizer' : optimizer.state_dict(),
}, is_best)
def train(train_loader, model, criterion, optimizer, epoch):
"""Train the model on Training Set"""
batch_time = AverageMeter()
data_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
top5 = AverageMeter()
# switch to train mode
model.train()
end = time.time()
for i, (input, target) in enumerate(train_loader):
# measure data loading time
data_time.update(time.time() - end)
if cuda:
input, target = input.cuda(async=True), target.cuda(async=True)
input_var = torch.autograd.Variable(input)
target_var = torch.autograd.Variable(target)
# compute output
output = model(input_var)
#topk = (1,5) if labels >= 100 else (1,) # TO FIX
# For nets that have multiple outputs such as Inception
if isinstance(output, tuple):
loss = sum((criterion(o,target_var) for o in output))
# print (output)
for o in output:
prec1 = accuracy(o.data, target, topk=(1,))
top1.update(prec1[0], input.size(0))
losses.update(loss.items(), input.size(0)*len(output))
else:
loss = criterion(output, target_var)
prec1 = accuracy(output.data, target, topk=(1,))
top1.update(prec1[0], input.size(0))
losses.update(loss.items(), input.size(0))
# compute gradient and do SGD step
optimizer.zero_grad()
loss.backward()
optimizer.step()
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
# Info log every args.print_freq
if i % args.print_freq == 0:
print('Epoch: [{0}][{1}/{2}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Data {data_time.val:.3f} ({data_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Prec@1 {top1_val} ({top1_avg})'.format(
epoch, i, len(train_loader), batch_time=batch_time,
data_time=data_time, loss=losses,
top1_val=numpy.asscalar(top1.val.cpu().numpy()),
top1_avg=numpy.asscalar(top1.avg.cpu().numpy())))
def validate(val_loader, model, criterion):
"""Validate the model on Validation Set"""
batch_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
top5 = AverageMeter()
# switch to evaluate mode
model.eval()
end = time.time()
# Evaluate all the validation set
for i, (input, target) in enumerate(val_loader):
if cuda:
input, target = input.cuda(async=True), target.cuda(async=True)
input_var = torch.autograd.Variable(input, volatile=True)
target_var = torch.autograd.Variable(target, volatile=True)
# compute output
output = model(input_var)
# print ("Output: ", output)
#topk = (1,5) if labels >= 100 else (1,) # TODO: add more topk evaluation
# For nets that have multiple outputs such as Inception
if isinstance(output, tuple):
loss = sum((criterion(o,target_var) for o in output))
# print (output)
for o in output:
prec1 = accuracy(o.data, target, topk=(1,))
top1.update(prec1[0], input.size(0))
losses.update(loss.items(), input.size(0)*len(output))
else:
loss = criterion(output, target_var)
prec1 = accuracy(output.data, target, topk=(1,))
top1.update(prec1[0], input.size(0))
losses.update(loss.items(), input.size(0))
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
# Info log every args.print_freq
if i % args.print_freq == 0:
print('Test: [{0}/{1}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Prec@1 {top1_val} ({top1_avg})'.format(
i, len(val_loader), batch_time=batch_time,
loss=losses,
top1_val=numpy.asscalar(top1.val.cpu().numpy()),
top1_avg=numpy.asscalar(top1.avg.cpu().numpy())))
print(' * Prec@1 {top1}'
.format(top1=numpy.asscalar(top1.avg.cpu().numpy())))
return top1.avg
def test(test_loader, model, names, classes):
"""Test the model on the Evaluation Folder
Args:
- classes: is a list with the class name
- names: is a generator to retrieve the filename that is classified
"""
# switch to evaluate mode
model.eval()
# Evaluate all the validation set
for i, (input, _) in enumerate(test_loader):
if cuda:
input = input.cuda(async=True)
input_var = torch.autograd.Variable(input, volatile=True)
# compute output
output = model(input_var)
# Take last layer output
if isinstance(output, tuple):
output = output[len(output)-1]
# print (output.data.max(1, keepdim=True)[1])
lab = classes[numpy.asscalar(output.data.max(1, keepdim=True)[1].cpu().numpy())]
print ("Images: " + next(names) + ", Classified as: " + lab)
def save_checkpoint(state, is_best, filename='checkpoint.pth.tar'):
torch.save(state, os.path.join(args.outf, filename))
if is_best:
shutil.copyfile(os.path.join(args.outf, filename), os.path.join(args.outf,'model_best.pth.tar'))
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def adjust_learning_rate(optimizer, epoch):
"""Sets the learning rate to the initial LR decayed by 10 every 30 epochs"""
lr = args.lr * (0.1 ** (epoch // 30))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
def accuracy(output, target, topk=(1,)):
"""Computes the precision@k for the specified values of k"""
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].view(-1).float().sum(0, keepdim=True)
res.append(correct_k.mul_(100.0 / batch_size))
return res
if __name__ == '__main__':
main()
支持的模型
- densenet201
- densenet121
数据
- 使用猫狗数据集
- 官网下载地址: Kaggle Cats and Dogs Dataset
- 将数据集分为 train、val、test
用法
- 训练
python main.py -a densenet201 --train --fine-tuning --pretrained --epochs 10 -b 4 - 测试
python main.py -a densenet201 --test --fine-tuning --evalf ./input/test/ --resume ./output/model_best.pth.tar
参考
- https://github.com/floydhub/imagenet
- https://www.jianshu.com/p/19eb2075effe