一、列表(List)
列表是python的基础数据类型之一 ,其他编程语言也有类似的数据类型.比如JS中的数组, java中的数组等等. 它是以[ ]括起来, 每个元素用’ , '隔开而且可以存放各种数据类型。列表相比于字符串,不仅可以储存不同的数据类型,而且可以储存大量数据,32位python的限制是 536870912 个元素,64位python的限制是 1152921504606846975 个元素。而且列表是有序的,有索引值,可切片,方便取值。
什么时候用:存储大量的数据,且需要这些数据有序的时候。制定一些特殊的数据群体:按顺序,按规则,自定制设计数据
- 创建列表的3种方式
-
第一种(常用)
- li = [‘山药’,‘韭菜’,‘120’,666]
-
第二种(不常用)
- l1 = list() #空列表
- l1 = list(iterable) # 可迭代对象
- l1 = list(‘666’) #[‘6’, ‘6’, ‘6’]
-
列表推导式
-
它的结构是在一个中括号里包含一个表达式,然后是一个for语句,然后是 0 个或多个 for 或者 if 语句。那个表达式可以是任意的,意思是你可以在列表中放入任意类型的对象。返回结果将是一个新的列表,在这个以 if 和 for 语句为上下文的表达式运行完成之后产生。
列表推导式的执行顺序:各语句之间是嵌套关系,左边第二个语句是最外层,依次往右进一层,左边第一条语句是最后一层。 -
[x*y for x in range(1,5) if x > 2 for y in range(1,4) if y < 3] 执行顺序如下: for x in range(1,5) if x > 2 for y in range(1,4) if y < 3 x*y # eg: # 8以内大于3的数 li = [ i for i in range(1,9) if i > 3] print(li) # [4, 5, 6, 7, 8]
-
- 列表的索引切片
l1 = ['shanyao', '韭菜', '枸杞', 22, 666]
print(l1[0]) #shanyao
print(l1[-1]) #666
print(l1[1:3]) #['韭菜', '枸杞']
print(l1[:-1]) #['shanyao', '韭菜', '枸杞', 22]
print(l1[::2]) #['shanyao', '枸杞', 666]
print(l1[::-1]) #[666, 22, '枸杞', '韭菜', 'shanyao']
print(l1[4:1:-1]) #[666, 22, '枸杞'
# 练习题:
li = [1, 3, 2, "a", 4, "b", 5,"c"]
#通过对li列表的切片形成新的列表l1,l1 = [1,3,2]
print(li[:3])
# 通过对li列表的切片形成新的列表l2,l2 = ["a",4,"b"]
print(li[3:6])
# 通过对li列表的切片形成新的列表l4,l4 = [3,"a","b"]
print(li[1:6:2])
# 通过对li列表的切片形成新的列表l6,l6 = ["b","a",3]
print(li[-3::-2])
- 列表的增
# append 追加,给列表的最后面追加一个元素
li = [2, 3, 'b']
li.append('山药')
print(li) # [2, 3, 'b', '山药']
# insert 在列表的任意位置插入元素
li = [2, 3, 'b']
li.insert(1,'山药')
print(li) # [2, '山药', 3, 'b']
# extend 迭代着追加,在列表的最后面迭代着追加一组数据
li = [2, 3, 'b']
li.extend('山药b')
print(li) # [2, 3, 'b', '山', '药', 'b']
- 列表的删
# pop 通过索引删除列表中对应的元素,该方法有返回值,返回值为删除的元素
li = ['山药','yam','韭菜','枸杞']
ret = li.pop(1)
print(li) #['山药', '韭菜', '枸杞']
print(ret) #yam 返回值,即删除的元素
# remove 通过元素删除列表中该元素
li = ['山药','yam','韭菜','枸杞']
ret = li.remove('yam')
print(li) #['山药', '韭菜', '枸杞']
# clear 清空列表
li = ['山药','yam','韭菜','枸杞']
ret = li.clear()
print(li) # []
# del 按照索引删除该元素
li = ['山药','yam','韭菜','枸杞']
del li[0]
print(li) # ['yam', '韭菜', '枸杞']
# 切片删除该元素
li = ['山药','yam','韭菜','枸杞']
del li[1:3]
print(li) #['山药', '枸杞']
# 切片(步长)删除该元素
li = ['山药','yam','韭菜','枸杞']
del li[::2]
print(li) # ['yam', '枸杞']
- 列表的改
# 按照索引改值
li = ['山药','yam','韭菜','枸杞']
li[2] = '222'
print(li) # ['山药', 'yam', '222', '枸杞']
# 按照切片改值(迭代着增加)
li = ['山药','yam','韭菜','枸杞']
li[1:3] = 'b2b'
print(li) #['山药', 'b', '2', 'b', '枸杞']
# 按照切片(步长)改值(必须一一对应,改变两个字符串就应该赋予一个字符串,其中有两个字符)
li = ['山药','yam','韭菜','枸杞']
li[::2] = 'bb'
print(li) #['b', 'yam', 'b', '枸杞']
- 列表的查
切片去查,或者循环去查
li = ['山药','yam','韭菜','枸杞']
for i in range(len(li)):
print(li[i])
# 输出结果:
山药
yam
韭菜
枸杞
- 列表的其它操作
count(数)(统计某个元素在列表中出现的次数)。
li = ['a','b','c','a','a',1,2,1]
print(li.count('a')) # 3
index(用于从列表中找出某个值第一个匹配项的索引位置)
li = ['a','b','c','a','a',1,2,1]
print(li.index(1)) # 5
sort (对列表进行排序)
li = [3,6,8,9,4,1,2,1]
li.sort() # 没有返回值,只能打印
print(li) # [1, 1, 2, 3, 4, 6, 8, 9]
li = [3,6,8,9,4,1,2,1]
li.sort(reverse=True) # reverse=True 降序
print(li) # [9, 8, 6, 4, 3, 2, 1, 1]
列表的加、乘
l1 = [1, 2, 3]
l2 = [4, 5, 6]
print(l1+l2) # [1, 2, 3, 4, 5, 6]
print(l1*3) # [1, 2, 3, 1, 2, 3, 1, 2, 3]
- 列表的嵌套
l1 = [1, 2, 'taibai', [1, 'WuSir', 3,]]
# 1, 将l1中的'taibai'变成大写并放回原处。
l1[2] = l1[2].upper()
print(l1) # [1, 2, 'TAIBAI', [1, 'WuSir', 3]]
# 2,给小列表[1,'WuSir',3,]追加一个元素,'老男孩教育'。
l1[3].append('老男孩教育')
print(l1) # [1, 2, 'taibai', [1, 'WuSir', 3, '老男孩教育']]
# 3,将列表中的'WuSir'通过字符串拼接的方式在列表中变成'WuSirsb'
l1[3][1] = l1[3][1]+'sb'
print(l1) # [1, 2, 'taibai', [1, 'WuSirsb', 3]]
-
列表的倒叙法
# 循环删除列表的元素 # 删除偶数 li = [11,22,33,44,55] for index in range(len(li)-1,-1,-1): #range(4,-1,-1)表示从4开始,逐渐递减,递减至-1的前面那个元素的值,为0 if index % 2 == 1: li.pop(index) print(li) # [11, 33, 55]
二、元组(tuple)
只能查看而不能增删改,这种数据类型就是元组。俗称不可变的列表,又被称为只读列表,用小括号()括起来以放任何数据类型的数据,查询可以,循环也可以,切片也可以.但就是不能改。将一些非常重要的不可让人改动的数据放在元组中,只供查看。常用于元组的拆包。
元组中如果只含有一个元素且没有逗号,则该元组不是元组,与该元素数据类型一致;如果有逗号,那么它是元组。
-
元组的索引切片
tu1 = ('a', 'b', '太白', 3, 666) print(tu1[0]) # 'a' print(tu1[-1]) # 666 print(tu1[1:3]) # ('b', '太白') print(tu1[:-1]) # ('a', 'b', '太白', 3) print(tu1[::2]) # ('a', '太白', 666) print(tu1[::-1]) # (666, 3, '太白', 'b', 'a') -
元组其他操作方法
index:通过元素找索引(可切片),找到第一个元素就返回,找不到该元素即报错。tu = ('太白', [1, 2, 3, ], 'WuSir', '女神') print(tu.index('女神')) # 3count: 获取某元素在列表中出现的次数
tu = ('太白', [1, 2, 3, ], 'WuSir', '女神','女神','女神') print(tu.count('女神')) # 3len(): 获取长度
tu = ('太白', [1, 2, 3, ], 'WuSir', '女神','女神','女神') print(len(tu)) # 6区分元组
tu1 = (2) tu2 = (2,) print(tu1,type(tu1)) # 2 <class 'int'> print(tu2,type(tu2)) # (2,) <class 'tuple'> tu3 = ([2,3,'山药']) tu4 = ([2,3,'山药'],) print(tu3,type(tu3)) # [2, 3, '山药'] <class 'list'> print(tu4,type(tu4)) # ([2, 3, '山药'],) <class 'tuple'>
三、字典(dict)
字典的引入:
列表可以存储大量的数据类型,但是如果数据量大的话,他的查询速度比较慢;列表只能按照顺序存储,数据与数据之间关联性不强。所以针对于以上的缺点,就需要引入另一种容器型的数据类型,解决上面的问题,这就需要dict字典。
可变与不可变的数据类型的分类:
不可变(可哈希)的数据类型:int,str,bool,tuple。
可变(不可哈希)的数据类型:list,dict,set。
字典是Python语言中的映射类型,他是用{}括起来,里面的内容是以键值对的形式储存的:
Key: 不可变(可哈希)的数据类型.并且键是唯一的,不重复的。
Value:任意数据(int,str,bool,tuple,list,dict,set)等等。
在Python3.5版本之前,字典是无序的。
在Python3.6版本之后,字典会按照初建字典时的顺序排列(即第一次插入数据的顺序排序)。
当然,字典也有缺点:他的缺点就是内存消耗巨大。
-
创建字典的几种方式
dic1 = dict((('three',3),('two',2),('one',1))) #dic1 = dict([('three',3),('two',2),('one',1)]) print(dic1,type(dic1)) # {'three': 3, 'two': 2, 'one': 1} <class 'dict'> dic2 = dict(one=1,two=2,three=3) print(dic2) # {'one': 1, 'two': 2, 'three': 3} dic3 = dict({'one':1,'two':2,'three':3}) print(dic3) # {'one': 1, 'two': 2, 'three': 3} # 字典推导式 dic4 = { k:v for k,v in [('one',1),('two',2),('three',3)]} print(dic4) # {'one': 1, 'two': 2, 'three': 3} # fromkeys:创建一个字典:字典的所有键来自一个可迭代对象,字典的值使用同一个值 dic5 = dict.fromkeys('山药','补肾壮阳') print(dic5) # {'山': '补肾壮阳', '药': '补肾壮阳'} # 如果fromkeys得到的字典的值为可变的数据类型,那么你得小心了。 dic6 = dict.fromkeys('123',['a','b','c']) dic6['1'].append('山药') print(dic6) # 全部增加了。 {'1': ['a', 'b', 'c', '山药'], '2': ['a', 'b', 'c', '山药'], '3': ['a', 'b', 'c', '山药']} -
字典的常用操作方法
-
字典的增
# 通过键值对直接增加 dic1 = dict({'name':'山药','年龄':20}) dic1['weight'] = 80 # 没有weight这个键,就增加键值对 print(dic1) # {'name': '山药', '年龄': 20, 'weight': 80} dic1['年龄'] = 18 # 有'年龄'这个键,就会改变键的值 print(dic1) # {'name': '山药', '年龄': 18, 'weight': 80} # setdefault dic2 = dict({'name':'山药','年龄':20}) dic2.setdefault('weight',90) # 没有weight这个键,就增加键值对 print(dic2) # {'name': '山药', '年龄': 20, 'weight': 90} dic2.setdefault('年龄',18) # # 有此键则键的值不变 print(dic2) # {'name': '山药', '年龄': 20, 'weight': 90} ret = dic2.setdefault('name') #它有返回值 print(ret) # 山药 -
字典的删
# pop 通过key删除字典的键值对,有返回值,可设置返回值。 dic1 = dict({'name':'山药','年龄':20}) ret = dic1.pop('年龄') print(ret,dic1) # 20 {'name': '山药'} dic1 = dict({'name':'山药','年龄':20}) ret = dic1.pop('QQ',None) print(ret,dic1) # None {'name': '山药', '年龄': 20} #popitem 3.5版本之前,popitem为随机删除,3.6之后为删除最后一个,有返回值 dic1 = dict({'name':'山药','年龄':20}) ret = dic1.popitem() print(ret,dic1) # ('年龄', 20) {'name': '山药'} #clear 清空字典 dic1 = dict({'name':'山药','年龄':20}) dic1.clear() print(dic1) # {} # del 通过键删除键值对 dic1 = dict({'name':'山药','年龄':20}) del dic1['name'] print(dic1) # {'年龄': 20} del dic1 # 删除整个字典 -
字典的改
# 通过键值对直接改 dic1 = dict({'name':'山药','年龄':20}) dic1['年龄'] = 18 print(dic1) # {'name': '山药', '年龄': 18} # update dic1 = dict({'name':'山药','年龄':20}) dic1.update(年龄=18,sex='男') print(dic1) # {'name': '山药', '年龄': 18, 'sex': '男'} dic1 = dict({'name':'山药','年龄':20}) dic1.update([(1,'a'),(2,'b')]) print(dic1) # {'name': '山药', '年龄': 20, 1: 'a', 2: 'b'} dic2 = dict((('No.1',1),('Two',2),('Three',3))) dic3 = dict([('Jan.','一月'),('Feb','二月'),('March','三月')]) dic3.update(dic2) print(dic3) # {'Jan.': '一月', 'Feb': '二月', 'March': '三月', 'No.1': 1, 'Two': 2, 'Three': 3} print(dic2) # {'No.1': 1, 'Two': 2, 'Three': 3} -
字典的查
# 通过键查询 # 直接dic[key](没有此键会报错) dic1 = dict({'name':'山药','年龄':20}) print(dic1['name']) # 山药 # get # 没有此键不会报错,而且可以设置提示信息,比如下面的'No key' dic1 = dict({'name':'山药','年龄':20}) v = dic1.get('年龄') print(v) # 20 v = dic1.get('name1') print(v) # None v = dic1.get('name2','No key') print(v) # No key # keys 获取字典的键 dic1 = dict({'name':'山药','年龄':20}) v = dic1.keys() print(v) # dict_keys(['name', '年龄']),一个高仿列表,存放的都是字典中的key # 并且这个高仿的列表可以转化成列表 print(list(v)) # ['name', '年龄'] # 还可以循环打印 for i in dic1: print(i) # name # 年龄 # values 获取字典的键的值 dic1 = dict({'name':'山药','年龄':20}) v = dic1.values() print(v) # dict_values(['山药', 20]),一个高仿列表,存放都是字典中的value # 并且这个高仿的列表可以转化成列表 print(list(v)) # ['山药', 20] # 它还可以循环打印 for i in dic1.values(): print(i) # 山药 # 20 # items 获取字典的键值对 dic1 = dict({'name':'山药','年龄':20}) v = dic1.items() print(v) # dict_items([('name', '山药'), ('年龄', 20)]),一个高仿列表,存放是多个元祖,元祖中第一个是字典中的键,第二个是字典中的值 # 并且这个高仿的列表可以转化成列表 print(list(v)) # [('name', '山药'), ('年龄', 20)] # 它还可以循环打印 for i in dic1.items(): print(i) # ('name', '山药') # ('年龄', 20) -
字典的相关练习题
dic = {'k1': "v1", "k2": "v2", "k3": [11,22,33]} # 请在字典中添加一个键值对,"k4": "v4",输出添加后的字典 dic.setdefault('k4','v4') print(dic) # {'k1': 'v1', 'k2': 'v2', 'k3': [11, 22, 33], 'k4': 'v4'} # 请修改字典中 "k1" 对应的值为 "alex",输出修改后的字典 dic.update(k1='alex') print(dic) # {'k1': 'alex', 'k2': 'v2', 'k3': [11, 22, 33], 'k4': 'v4'} # 请在k3对应的值中追加一个元素 44,输出修改后的字典 dic['k3'].append(44) print(dic) # {'k1': 'alex', 'k2': 'v2', 'k3': [11, 22, 33, 44], 'k4': 'v4'} # 请在k3对应的值的第 1 个位置插入个元素 18,输出修改后的字典 dic['k3'].insert(0,18) print(dic) # {'k1': 'alex', 'k2': 'v2', 'k3': [18, 11, 22, 33, 44], 'k4': 'v4'} # 将字典中含'k'元素的键值对删掉 # 在循环一个字典的过程中,不要改变字典的大小(增,删字典的元素),这样会直接报错 # 方法一: dic = {'k1':123,'k2':'abc','k3':'山药','number':88} li = [] for key in dic: if 'k' in key: li.append(key) # # print(li) # ['k1', 'k2', 'k3'] for i in li: dic.pop(i) print(dic) # {'number': 88} # 方法二: for key in list(dic.keys()): # ['k1', 'k2', 'k3', 'number'] if 'k' in key: dic.pop(key) print(dic) # {'number': 88} -
分别赋值,即拆包
a,b = 5,6 print(a,b) # 5 6 a,b = ('山药','nb') print(a,b) # 山药 nb a,b = ['nb','山药'] print(a,b) # nb 山药 a,b = {'山药':'nb','you':'不行'} print(a,b) # 山药 you # so,上面的字典还可以这样查: dic1 = dict({'name':'山药','年龄':20}) for k,v in dic1.items(): print('This is Key: ',k) print('This is Values: ',v) # This is Key: name # This is Values: 山药 # This is Key: 年龄 # This is Values: 20
-
-
字典的嵌套
dic = { 'name':'汪峰', 'age':48, 'wife':[{'name':'国际章','age':38}], 'children':{'girl_first':'小苹果','girl_second':'小怡','girl_three':'顶顶'} } # 1. 获取汪峰的名字。 print(dic.get('name')) # 汪峰 # 2.获取这个字典:{'name':'国际章','age':38}。 print(dic.get('wife')[0]) # {'name': '国际章', 'age': 38} # 3. 获取汪峰妻子的名字。 print(dic.get('wife')[0]['name']) # 国际章 # 4. 获取汪峰的第三个孩子名字。 print(dic.get('children')['girl_three']) # 顶顶 dic1 = { 'name':['alex',2,3,5], 'job':'teacher', 'oldboy':{'alex':['python1','python2',100]} } # 1,将name对应的列表追加⼀个元素’wusir’。 dic1['name'].append('wusir') print(dic1['name']) # ['alex', 2, 3, 5, 'wusir'] # 2,将name对应的列表中的alex⾸字⺟⼤写。 dic1.get('name')[0] = 'Alex' print(dic1['name']) # ['Alex', 2, 3, 5, 'wusir'] # 3,oldboy对应的字典加⼀个键值对’⽼男孩’,’linux’。 dic1['oldboy'].setdefault('老男孩','Linux') print(dic1['oldboy']) # {'alex': ['python1', 'python2', 100], '老男孩': 'Linux'} # 4,将oldboy对应的字典中的alex对应的列表中的python2删除 del dic1.get('oldboy')['alex'][1] print(dic1.get('oldboy')['alex']) # ['python1', 100]
四、集合(set)
集合是无序的,不重复的数据集合,它里面的元素是可哈希的(不可变类型),但是集合本身是不可哈希(所以集合做不了字典的键)的。以下是集合最重要的两点:
去重:把一个列表变成集合,就自动去重了。
关系测试:测试两组数据之前的交集、差集、并集等关系。
-
集合的创建
set1 = set({1,2,'山药'}) set2 = {'山药','python',5,6} print(set1,type(set1)) # {1, 2, '山药'} <class 'set'> print(set2,type(set2)) # {'python', 5, 6, '山药'} <class 'set'> -
集合的增
set1 = set({1,2,'山药','Linux'}) set1.add(3) print(set1) # {1, 2, 3, 'Linux', '山药'} #update:迭代着增加 set1.update('a') print(set1) # {1, 2, 3, '山药', 'a', 'Linux'} set1.update('老师') print(set1) # {1, 2, 3, '山药', 'Linux', '老', 'a', '师'} set1.update([4,5,6]) print(set1) # {1, 2, 3, 4, 5, 6, '老', 'Linux', '师', 'a', '山药'} -
集合的删
set1 = set({1,2,'山药','Linux'}) set1.remove('Linux') # 删除一个元素 print(set1) # {'山药', 1, 2} set1 = set({1,2,'山药','Linux'}) set1.pop() # 随机删除一个元素 print(set1) # {2, 'Linux', '山药'} set1 = set({1,2,'山药','Linux'}) set1.clear() # 清空集合 print(set1) # set() set1 = set({1,2,'山药','Linux'}) del set1 # 删除集合 print(set1) -
集合的其他操作
# 交集:& 或者 intersection set1 = {1,2,3,4,5} set2 = {4,5,6,7,8} print(set1 & set2) # {4, 5} print(set1.intersection(set2)) # {4, 5} # 并集: | 或者 union set1 = {1,2,3,4,5} set2 = {4,5,6,7,8} print(set1 | set2) # {1, 2, 3, 4, 5, 6, 7, 8} print(set1.union(set2)) # {1, 2, 3, 4, 5, 6, 7, 8} # 差: - 或者 difference set1 = {1,2,3,4,5} set2 = {4,5,6,7,8} print(set1 - set2) # {1, 2, 3} print(set2 - set1) # {8, 6, 7} print(set1.difference(set2)) # {1, 2, 3} print(set2.difference(set1)) # {8, 6, 7} # 反交集: ^ 或者 symmetric_difference set1 = {1,2,3,4,5} set2 = {4,5,6,7,8} print(set1 ^ set2) # {1, 2, 3, 6, 7, 8} print(set1.symmetric_difference(set2)) # {1, 2, 3, 6, 7, 8} # 子集与超集 set1 = {1,2,3} set2 = {1,2,3,4,5,6} print(set1 < set2) # True print(set1.issubset(set2)) # True ,这两个相同,都是说明set1是set2子集。 print(set2 > set1) # True print(set2.issuperset(set1)) # True,这两个相同,都是说明set2是set1超集。 # frozenset不可变集合,让集合变成不可变类型 s = frozenset('barry') print(s,type(s)) # frozenset({'b', 'y', 'a', 'r'}) <class 'frozenset'>
五、数据类型间的转换
str list 两者转换
# str ---> list
s1 = 'alex 太白 武大'
print(s1.split()) # ['alex', '太白', '武大']
# list ---> str # 前提 list 里面所有的元素必须是字符串类型才可以
l1 = ['alex', '太白', '武大']
print(','.join(l1)) # alex,太白,武
list set 两者转换
# list ---> set
s1 = [1, 2, 3]
print(set(s1)) # {1, 2, 3}
# set ---> list
set1 = {1, 2, 3, 3,}
print(list(set1)) # [1, 2, 3]
str bytes 两者转换
# str ---> bytes
s1 = '山药'
print(s1.encode('utf-8')) # b'\xe5\xb1\xb1\xe8\x8d\xaf'
# bytes ---> str
b = b'\xe5\xb1\xb1\xe8\x8d\xaf'
print(b.decode('utf-8')) # '山药'
所有数据都可以转化成bool值
转化成bool值为False的数据类型有:
'', 0, (), {}, [], set(), None
六、基础数据类型的总结
按存储空间的占用分(从低到高)
数字
字符串
集合:无序,即无序存储索引相关信息
元组:有序,需要存储索引相关信息,不可变
列表:有序,需要存储索引相关信息,可变,需要处理数据的增删改
字典:有序,需要存储key与value映射的相关信息,可变,需要处理数据的增删改(3.6之后有序)
按存值个数区分
| 标量/原子类型 | 数字,字符串 |
|---|---|
| 容器类型 | 列表,元组,字典 |
按可变不可变区分
| 可变 | 列表,字典 |
|---|---|
| 不可变 | 数字,字符串,元组,布尔值 |
按访问顺序区分
| 直接访问 | 数字 |
|---|---|
| 顺序访问(序列类型) | 字符串,列表,元组 |
| key值访问(映射类型) | 字典 |
七、编码
ASCII码:包含英文字母,数字,特殊字符与01010101对应关系。
a 01000001 一个字符一个字节表示。
GBK:只包含本国文字(以及英文字母,数字,特殊字符,即ASCII码)与0101010对应关系。
a 01000001 ascii码中的字符:一个字符一个字节表示。
中 01001001 01000010 中文:一个字符两个字节表示。
Unicode:包含全世界所有的文字与二进制0101001的对应关系,所有的字符都采用4个字节。
a 01000001 01000010 01000011 00000001
b 01000001 01000010 01100011 00000001
中 01001001 01000010 01100011 00000001
UTF-8:*包含全世界所有的文字与二进制0101001的对应关系(最少用8位一个字节表示一个字符)。*
a 01000001 ascii码中的字符:一个字符一个字节表示。
To 01000001 01000010 (欧洲文字:葡萄牙,西班牙等)一个字符两个字节表示。
中 01001001 01000010 01100011 亚洲文字;一个字符三个字节表示。
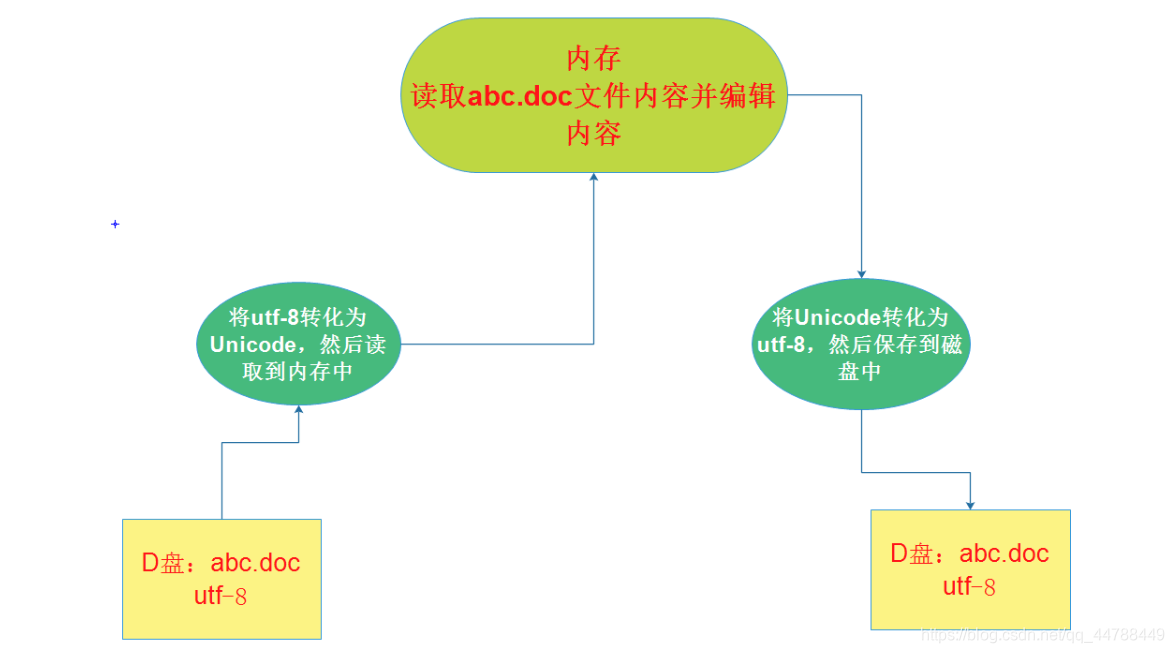
1. 在计算机内存中,统一使用Unicode编码,当需要将数据保存到硬盘或者需要网络传输的时候,就转换为非Unicode编码比如:UTF-8编码。
举个例子:用文件编辑器(word,wps等)编辑文件的时候,将会从文件中读取你的数据(此时你的数据是非Unicode(可能是UTF-8,也可能是gbk,这个编码取决于你的编辑器设置))字符被转换为Unicode字符读到内存里,进行相应的编辑,编辑完成后,保存的时候再把Unicode转换为非Unicode(UTF-8,GBK 等)保存到文件中。
2. 不同编码之间,不能直接互相识别。
必须将这个其他数据类型转化成一个特殊的字符串类型bytes,然后才可以传输出去,数据的存储也是如此
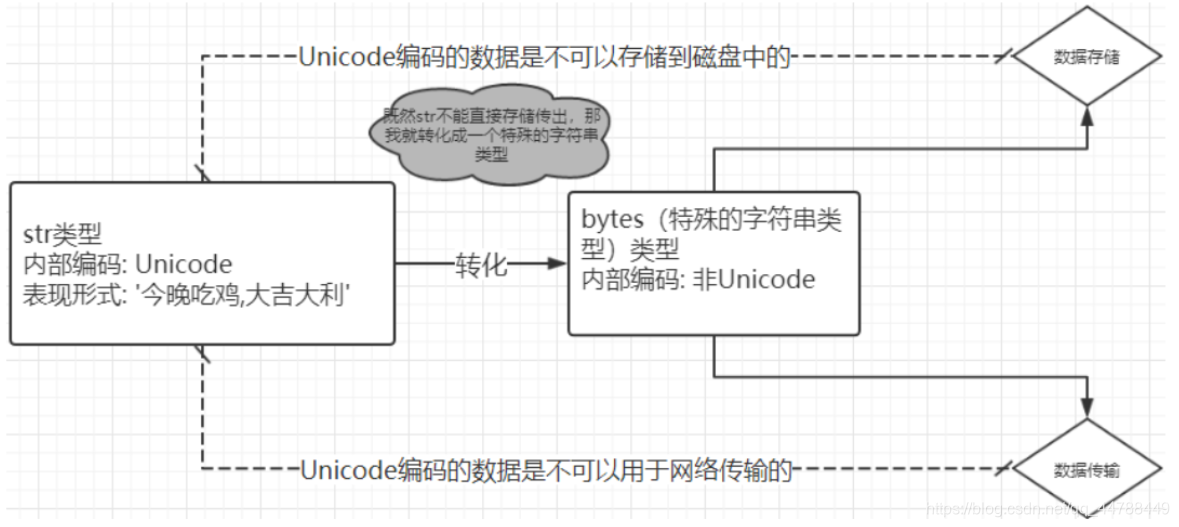
bytes类型也称作字节文本,他的主要用途就是网络的数据传输与数据存储.bytes类型与str差不多,而且操作方法也很相似
表现形式: 前面加个b
英文:b’alex’
中文:b’\xe4\xb8\xad\xe5\x9b\xbd’
如果你的str数据想要存储到文件或者传输出去,那么直接是不可以的,要将str数据转化成bytes数据就可以了。
str ----> bytes
# encode称为编码: 将str转化成bytes类型
s1 = '山药'
b1 = s1.encode('utf-8') # 转化成utf-8的bytes类型
print(s1) # 山药
print(b1) # b'\xe5\xb1\xb1\xe8\x8d\xaf'
s1 = '山药'
b1 = s1.encode('gbk') # 转化成gbk的bytes类型
print(s1) # 山药
print(b1) # b'\xc9\xbd\xd2\xa9'
bytes —> str
# decode称为解码, 将 bytes 转化成 str类型
b1 = b'\xe5\xb1\xb1\xe8\x8d\xaf'
s1 = b1.decode('utf-8')
print(s1) # 山药
不同编码之间不能直接转化,但是可以间接转化,列如:先将utf-8------>unicode,再unicode------gbk
python 3的编码,默认是unicode
s1 = '山药'
# 字符串'山药'已经是unicode编码,无需decode,直接encode
b1 = s1.encode('gbk')
print(b1) # b'\xc9\xbd\xd2\xa9'
# gbk需要先解码成unicode,再编码成utf-8
b2 =b1.decode('gbk').encode('utf-8')
print(b2) # b'\xe5\xb1\xb1\xe8\x8d\xaf'
# 解码成unicode字符编码
b3 = b2.decode('utf-8')
print(b3) # 山药
# 成功完成了从gbk编码转化为utf-8编码
八、练习题
#将kind列表使用'_'连接
kind = ['山药','枸杞','韭菜','人参']
s = ''
for index in range(len(kind)):
if index == 0:
s += str(kind[index])
else:
s = s+'_'+str(kind[index])
print(s) # 山药_枸杞_韭菜_人参
# 将元组 v1 = (11,22,33) 中的所有元素追加到列表 v2 = [44,55,66]中
v1 = (11,22,33)
v2 = [44,55,66]
# for i in v1:
# v2.append(i)
# print(v2) # [44, 55, 66, 11, 22, 33]
v2.extend(v1)
print(v2) # [44, 55, 66, 11, 22, 33]
# 将元组v1=(11,22,33,44,55,66,77,88,99)中的所有偶数索引位置的元素追加到列表v2=[44,55,66]中
v1=(11,22,33,44,55,66,77,88,99)
v2=[44,55,66]
#第一种方法
# for index in range(len(v1)):
# if index % 2 == 0:
# v2.append(v1[index])
# print(v2) # # [44, 55, 66, 11, 33, 55, 77, 99]
#第二种方法
v2.extend(v1[::2])
print(v2) # [44, 55, 66, 11, 33, 55, 77, 99]
# 将字典{'k1':'v1','k2':'v2','k3':'v3'}的键和值分别追加到key_list和value_list两个列表中
key_list = []
value_list = []
info = {'k1':'v1','k2':'v2','k3':'v3'}
# for key,value in info.items():
# key_list.append(key)
# value_list.append(value)
# print(key_list) # ['k1', 'k2', 'k3']
# print(value_list) # ['v1', 'v2', 'v3']
key_list.extend(info.keys())
print(key_list) # ['k1', 'k2', 'k3']
value_list.extend(info.values())
print(value_list) # ['v1', 'v2', 'v3']
# 将字符串'k: 1|k1:2|k2:3 |k3 :4'处理成为字典{'k':1,'k1':2,'k2':3,'k3':4'}
dic = {}
str1 = 'k: 1|k1:2|k2:3 |k3 :4'
# str1.strip()
# print(str1)
str2 = str1.strip().split('|')
# print(str2)
for i in str2:
key,value = i.split(':')
dic[key.strip()] = value.strip()
print(dic) # {'k': '1', 'k1': '2', 'k2': '3', 'k3': '4'}
# 要求:
# 1.将goods列表显示出来: 序号+商品名称+商品价格, 如:1 电脑 5999
# 2.用户输入商品序号,然后打印商品名称及价格
# 3.若用户输入的商品序号有误,则提示重新输入
# 4.用户输入q或者Q退出程序
goods = [
{'name':'电脑','price':5999},
{'name':'鼠标','price':100},
{'name':'键盘','price':200},
{'name':'耳机','price':300}
]
while 1:
for num,dic in enumerate(goods):
print('商品序号: {}\t商品名称: {}\t商品价格: {}'.format(num + 1, dic['name'], dic['price']))
goods_num = input('请输入商品序号:(按q或者Q退出!)').strip()
if goods_num.isdecimal():
goods_num = int(goods_num)
if 0 < goods_num <= len(goods):
print('您选择的商品是: {}\t商品价格是: {}\n'.format(goods[goods_num-1]['name'],goods[goods_num-1]['price']))
else:
print('您输入的序号超出范围,请重新输入!')
elif goods_num.upper() == 'Q':
break
else:
print('您输入了非数字元素,请重新输入!')
# 输出结果:
商品序号: 1 商品名称: 电脑 商品价格: 5999
商品序号: 2 商品名称: 鼠标 商品价格: 100
商品序号: 3 商品名称: 键盘 商品价格: 200
商品序号: 4 商品名称: 耳机 商品价格: 300
请输入商品序号:(按q或者Q退出!)2
您选择的商品是: 鼠标 商品价格是: 100
商品序号: 1 商品名称: 电脑 商品价格: 5999
商品序号: 2 商品名称: 鼠标 商品价格: 100
商品序号: 3 商品名称: 键盘 商品价格: 200
商品序号: 4 商品名称: 耳机 商品价格: 300
请输入商品序号:(按q或者Q退出!)d
您输入了非数字元素,请重新输入!
商品序号: 1 商品名称: 电脑 商品价格: 5999
商品序号: 2 商品名称: 鼠标 商品价格: 100
商品序号: 3 商品名称: 键盘 商品价格: 200
商品序号: 4 商品名称: 耳机 商品价格: 300
请输入商品序号:(按q或者Q退出!)6
您输入的序号超出范围,请重新输入!
商品序号: 1 商品名称: 电脑 商品价格: 5999
商品序号: 2 商品名称: 鼠标 商品价格: 100
商品序号: 3 商品名称: 键盘 商品价格: 200
商品序号: 4 商品名称: 耳机 商品价格: 300
请输入商品序号:(按q或者Q退出!)q
Process finished with exit code 0