第三章 基础知识
1.技术选型
Scrapy VS Requests+bs4
- requests和bs4都是库,scrapy是框架。实际上框架是可以继承很多第三方库的,所以在scrapy中是可以加入requests和bs4的。
- scrapy基于twisted,是个异步IO的框架,所以性能十分高,性能是最大的优势。
- scrapy内置的css和xpath selector非常方便,所以在scrapy中不会用到bs4。bs4最大的缺点就是慢(上百倍)。
- scrapy方便扩展,提供了很多内置的功能。
所以,主要选择scrapy+requests
2.网页分类
- 静态网页,在服务器端已经生成好了一个页面,这个页面内容是不会变的,不需要与数据库交互。
- 动态网页,根据我们传的参数,来从服务器数据库取数据填充网页。
- webservice(restapi),实际上也是动态网页的一种。
3.爬虫能做什么
- 搜索引擎----百度、垂直领域搜索引擎
- 推荐引擎----今日头条
- 机器学习的数据样本
- 数据分析(如金融数据分析)、舆情分析
4.正则表达式
- ^ $ * ? + {2} {2,} {2,5}
- [] [^](取反的意思) [a-z]
- \s \S \w \W
- [\u4E00-\u9FA5] () \d
import re
line = "bobby123"
regex_str = "^b.*3$" #以b开头、以4结尾、中间任意多个字符
if re.match(regex_str,line):
print("yes") #输出yes
?非贪婪模式
#贪婪匹配模式
import re
line = "boooobby123"
regex_str = ".*(b.*b).*"
match_obj = re.match(regex_str,line)
if match_obj:
print(match_obj.group(1))#输出bb 贪婪匹配是反向匹配,从右到左匹配
#非贪婪模式
line = "boooobby123"
regex_str = ".*?(b.*?b).*"
match_obj = re.match(regex_str,line)
if match_obj:
print(match_obj.group(1))#输出boooob 从左边开始匹配,满足一个就匹配
案例:匹配出生日期
import re
line = "出生于2001年6月1日"
line = "出生于2001年6月"
line = "出生于2001/6/1"
line = "出生于2001-6-1"
line = "出生于2001-06-01"
line = "出生于2001-06"
regex_str = "出生于(\d{4}[年/-]\d{1,2}([月/-]\d{1,2}|[月/-]$|$))"
match_obj = re.match(regex_str,line)
if match_obj:
print(match_obj.group(1)) #可以尝试下group(2)
5.深度优先与广度优先算法
网站url结构图(以伯乐在线为例)
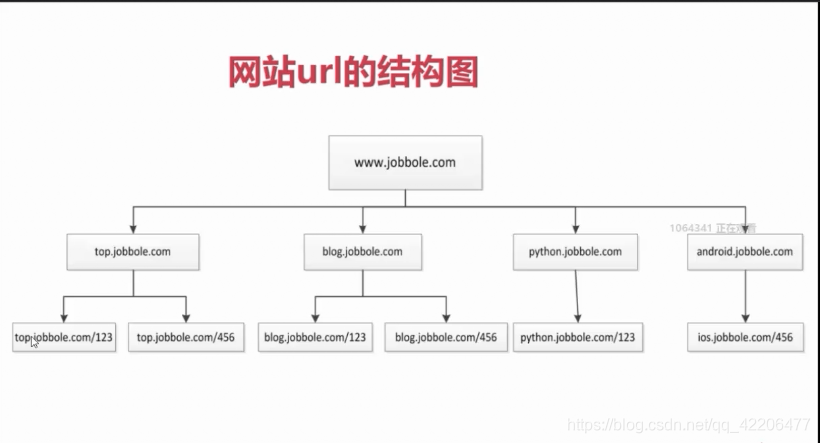
- 可以从上图看出,整个网站的url是一个树形结构
实际链接逻辑图:
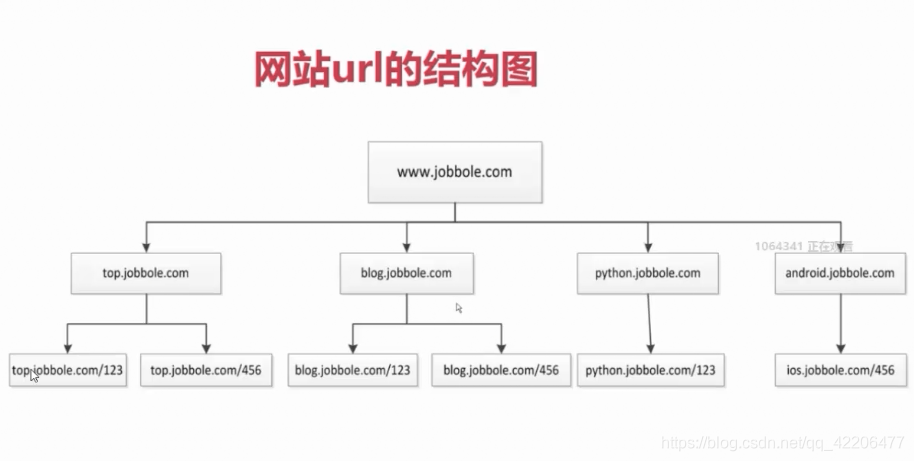
- 链接存在环路(几乎任何页面都可以跳到首页)
- 解决环路问题:URL去重(爬取过的链接 不再爬)
深度优先算法与广度优先算法
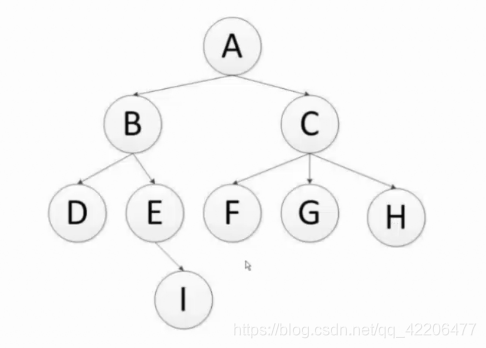

- 深度爬取顺序:A B D E I C F G H(递归实现)
- 广度爬取顺序:A B C D E F G H I(队列实现)
- scrapy 默认深度优先算法
深度优先过程

广度优先过程

6.爬虫去重策略
- 将访问过的url保存到数据库中。当获取下一个url时,在数据库查询是否包含。虽然数据库有缓存,但是每一个url都要查询一次,效率特别低。
- 将访问过的url保存到set中,只需要O(1)的代价就可以查询url,但是当url数量过大时,十分占内存。
- url经过md5等方法哈希后保存到set,将任意长度url压缩到统一长度,很大程度上节省了内存,scrapy就是采用这种方式。
- 用bitmap方法,将访问的url通过hash函数映射到某一位,能更进一步压缩内存,但是容易出现冲突。
- bloomfilter方法对bitmap进行改进,多重hash函数降低冲突。
7.字符串编码
-
计算机只能处理数字,文本转换为数字(二进制)才能处理。计算机中8个bit作为一个字节,所以一个字节能表示最大的数字就是255
-
计算机是美国人发明的,所以一个字节可以表示所有字符了,ASCII(一个字节)编码就成为美国人的标准编码
-
但是ASCLL处理中文明显是不够的,中文不止255个汉字,所以中国制定了GB2312编码,用两个字节表示一个汉字。GB2312还把ASCLL包含进去了,同理,日文、韩文等等上百个国家为了解决这个问题就都发展了一套字节的编码,标准越来越多,如果出现多种语言混合显示就一定会出现乱码
-
于是unicode出现了,将所有语言统一到一套编码中
-
ASCII和unicode编码:
字母A用ASCLL编码是 0100 0001
汉字“中”已经超过ASCLL编码的范围,用unicode编码是01001110 00101101
A用unicode编码只需要前面补0,编码是 00000000 0100 0001 -
乱码问题解决了,但是如果内容全是英文,unicode编码比ASCLL需要多一倍的存储空间,同时如果传输需要多一倍的传输。
-
所以就出现了可变长的编码"utf-8",把英文变长一个字节,汉字3个字节。特别生僻的变成4-6字节,如果传输大量的英文,utf8作用就很明显了。
-
但是由于utf8可变长的性质,utf8在内存编码处理较复杂。所以在传输存储时转换成utf8,在内存操作时转换成unicode编码,就十分有必要了。
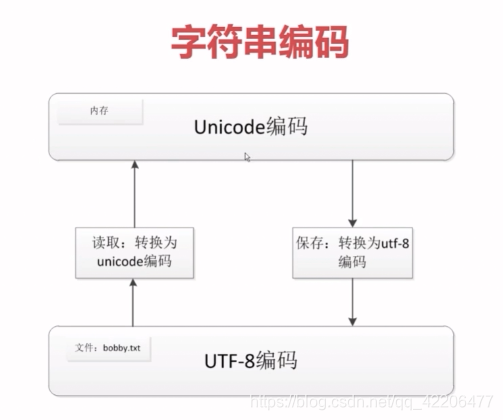
unicode与utf-8相互转换:
s.decode("utf-8") #将utf8转换成unicode
s.encode("utf-8") #将unicode转换成utf8