写在前面: 我是
「nicedays」,一枚喜爱做特效,听音乐,分享技术的大数据开发猿。这名字是来自world order乐队的一首HAVE A NICE DAY。如今,走到现在很多坎坷和不顺,如今终于明白nice day是需要自己赋予的。
白驹过隙,时光荏苒,珍惜当下~~
写博客一方面是对自己学习的一点点总结及记录,另一方面则是希望能够帮助更多对大数据感兴趣的朋友。如果你也对大数据与机器学习感兴趣,可以关注我的动态https://blog.csdn.net/qq_35050438,让我们一起挖掘数据与人工智能的价值~
文章目录
Spark–DataFrameAPI常见操作:
元数据:
def createAndLoadData()={
val spark = SparkSession.builder().appName("test").master("local[1]").getOrCreate()
}
def getLocalTeacher(spark:SparkSession)={
val schema = StructType(
List(
StructField("t_id",StringType,nullable = true),
StructField("t_name",StringType,nullable = true)
)
)
spark.createDataFrame(spark.sparkContext.parallelize(Seq(
Row("1","张三"),
Row("2","李四")
)),schema)
}
def getLocalStudent(spark:SparkSession)={
val schema = StructType(
List(
StructField("s_id",StringType,nullable = true),
StructField("s_name",StringType,nullable = true),
StructField("s_birth",StringType,nullable = true),
StructField("s_sex",StringType,nullable = true)
)
)
spark.createDataFrame(spark.sparkContext.parallelize(Seq(
Row("1","赵雷","1990,01,01","男"),
Row("2","钱电","1990,12,21","男"),
Row("3","孙风","1990,05,20","男"),
Row("4","李云","1990,08,01","男"),
Row("5","周梅","1991,12,01","女"),
Row("6","吴兰","1992,03,01","女"),
Row("7","郑竹","1989,07,01","女"),
Row("8","王菊","1990,01,20","女")
)),schema)
}
def getLocalCourse(spark:SparkSession)={
val schema = StructType(
List(
StructField("c_id",StringType,nullable = true),
StructField("c_name",StringType,nullable = true),
StructField("t_id",StringType,nullable = true)
)
)
spark.createDataFrame(spark.sparkContext.parallelize(Seq(
Row("1","语文","2"),
Row("2","数学","1"),
Row("3","英语","3")
)),schema)
}
def getLocalScore(spark:SparkSession)={
val schema = StructType(
List(
StructField("s_id",StringType,true),
StructField("c_id",StringType,true),
StructField("s_score",StringType,true)
)
)
spark.createDataFrame(spark.sparkContext.parallelize(Seq(
Row("1","1","80"),
Row("1","2","90"),
Row("1","3","99"),
Row("2","1","70"),
Row("2","2","60"),
Row("2","3","65"),
Row("3","1","80"),
Row("3","2","80"),
Row("3","3","80"),
Row("4","1","50"),
Row("4","2","30"),
Row("4","3","40"),
Row("5","1","76"),
Row("5","2","87"),
Row("6","1","31"),
Row("6","3","34"),
Row("7","2","89"),
Row("7","3","98")
)),schema)
}
// 获取基础数据
val (spark,course,student,teacher,score) = createAndLoadData()
处理日期和时间戳:
查询本周过生日的学生
student.select($"s_id",$"s_name",weekofyear(concat(year(current_date()),date_format($"s_birth","-MM-dd"))). alias("nt"),weekofyear(current_date()).alias("dt")).
filter($"nt" === $"dt").
show()
处理数据空值:
基于DataFrame,处理null值主要方式是.na子包。
ifnull
- 如果第一个值为空,则允许第二个值去取代他
nullif
- 如果两个值相等,则返回null,否则返回第二个值
nvl
- 如果第一个值为null,则返回第二个值,否则返回第一个值
nvl2
- 如果第一个不为null,返回第二个指定值,否则返回最后一个指定值
drop
- 删除包含null的行
df.na.drop()
df.na.drop("any") # 存在null就删除
df.na.drop("all") # 全部为null才能删除
df.na.drop("any",Seq("StockCode","InvoiceNo")) # 指定列删除
fill
- 用一组值填充一列或者多列
df.na.fill("value") # 将字符类型列的null值替换
df.na.fill(5,Seq("store")) # 指定列替换null值
replace
- 将当前值替换掉某列的所有值
df.na.replace("description",Map("" -> "UNKNOWN"))
窗口函数解决问题:
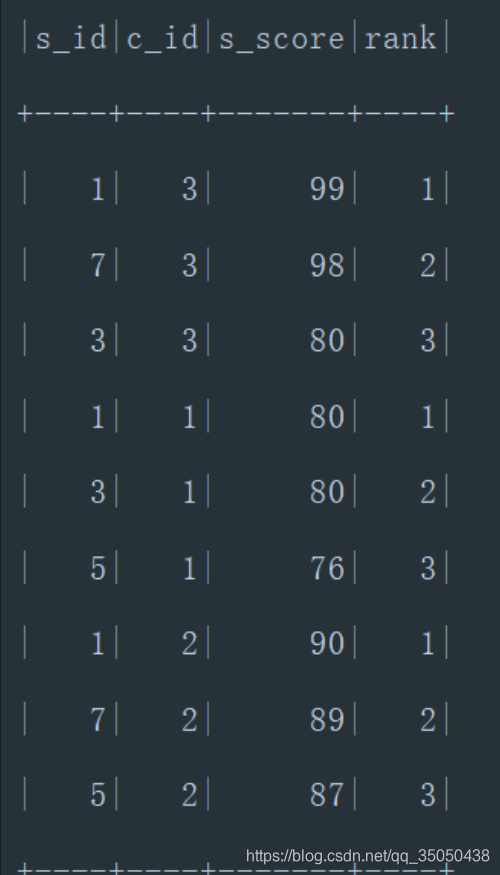
查询每门课程成绩最好的前三名
score.select($"s_id",$"c_id",$"s_score",row_number().over(Window.partitionBy("c_id").orderBy(desc("s_score"))).alias("rank")).
withColumn("s_id",regexp_replace(isnull($"s_id"),"NULL",$"s_id")).
filter($"rank" <= 3).
show()
UDF自定义函数:
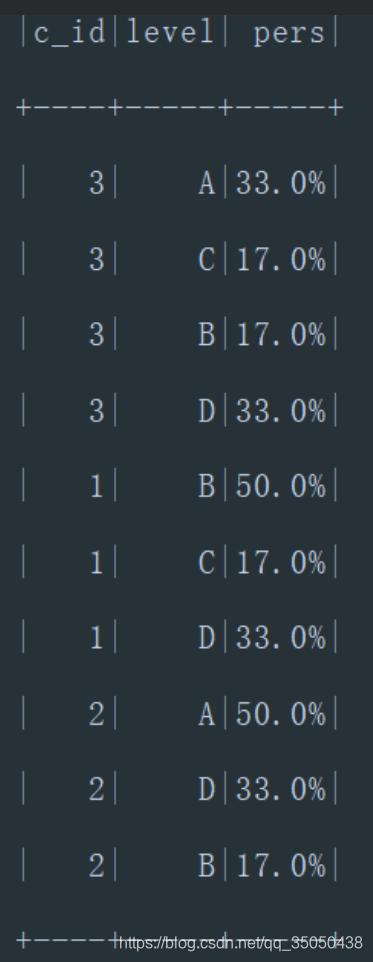
统计各科成绩各分数段人数:课程编号,课程名称,[100-85],[85-70],[70-60],[0-60]及所占百分比
// udf
val scoreTransaction = udf{score: String => {
score.toInt match {
case x if x > 85 => "A"
case x if x > 70 => "B"
case x if x > 60 => "C"
case _ => "D"
}
}
val countval = score.groupBy($"c_id").agg(count($"c_id").alias("Csum"))
score.select($"s_id", $"c_id", scoreTransaction($"s_score").alias("level")).
join(countval,"c_id").
groupBy($"c_id", $"level").
agg((round(count($"level") / first($"Csum"),2) * 100).alias("per")).
withColumn("%",lit("%")).
select($"c_id",$"level",concat($"per",$"%").alias("pers")).
show()
列转行:
查询各科成绩最高分、最低分和平均分:
以如下形式显示:课程 ID,课程 name,及格率,中等率,优良率,优秀率及格为>=60,中等为:70-80,优良为:80-90,优秀为:>=90
要求输出课程号和选修人数,查询结果按人数降序排列,若人数相同,按课程号升序排列
val tmp = score.
join(course,Seq("c_id")).
groupBy($"c_name",$"c_id"). agg(round(count(when($"s_score">=60,1).otherwise(null))/count($"c_id"),2).as("jige_ratio"),
round(count(when($"s_score">=70 && $"s_score"<80 ,1).otherwise(null))/count($"s_id"),2).as("zhongdeng_ratio"),
round(count(when($"s_score">=80 && $"s_score"<90 ,1).otherwise(null))/count($"c_id"),2).as("youliang_ratio"),
round(count(when($"s_score">=90,1).otherwise(null))/count($"c_id"),2).as("youxiu_ratio"),
count($"c_id").as("nums")).
sort(desc("nums"),asc("c_id")).
show()

取反,差集,交集:
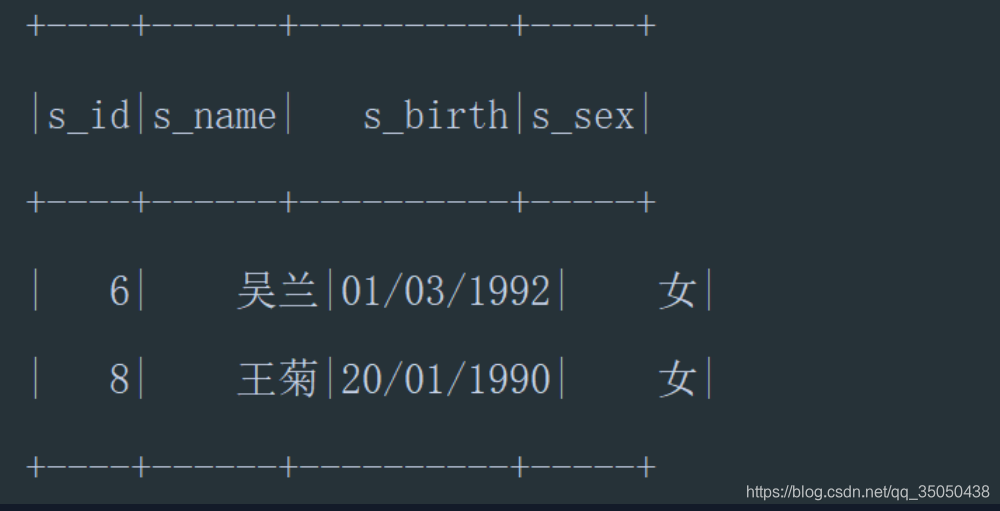
查询没学过"张三"老师授课的同学的信息:–左反连接
val tmp = teacher.
filter($"t_name" === lit("张三")).
join(course, "t_id").
select("c_id").
join(score, "c_id").
groupBy($"s_id").
agg(count($"s_id")).
select("s_id")
// Seq("s_id") <=> student("s_id") === frame("s_id")
student.join(tmp,Seq("s_id"), "left_anti" ).show()
侧视图:
explode:
- explode方法可以从规定的Array或者Map中使用每一个元素创建一列
import org.apache.spark.sql.functions._
// 数组和列表
df.withColumn("entityPair", explode(col("entityList")));
// map
df.select(df("name"),explode(df("myScore"))).toDF("key","value")
| name | age | interest |
|---|---|---|
| A | 20 | 篮球,羽毛球 |
| B | 32 | 游泳,慢跑,看电视 |
| … | … | … |
转成:
| name | age | interest |
|---|---|---|
| A | 20 | 篮球 |
| A | 20 | 羽毛球 |
| B | 32 | 游泳 |
| B | 32 | 慢跑 |
| B | 32 | 看电视 |
DataFrame某列转集合后获取对应行的元素:
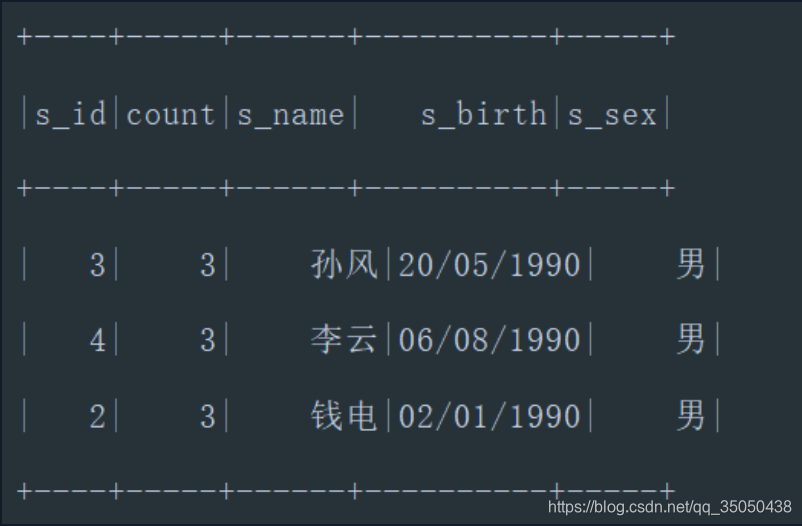
查询和"01"号的同学学习的课程完全相同的其他同学的信息:
/** score.
filter($"s_id" === 1).
groupBy($"s_id").
agg(collect_set($"s_id").as("c1")).
//select($"c1").
// map对每行进行遍历,getas拿到c1的每行数据再把它转化成seq
map(a => a.getAs[Seq[String]]("c1").toArray).
collectAsList()
get(0)
**/
val value= score.
filter("s_id = 1").
select("c_id").distinct().
agg(count("c_id").alias("co")).
select("co").
collect().
flatMap(x=>x.toSeq).
toList
val value1 = score.
filter("s_id = 1").
select("c_id").
distinct()
val frame = score.
join(value1, "c_id").
groupBy("s_id").
agg(count(score("s_id")).alias("count")).
filter($"count".isin(value:_*) && $"s_id" =!= 1).
join(student,"s_id").
show()