第1章 自然语言处理简介
1. pyton总结:
- list列表功能
- help()和dir(lst)可以了解结构相关函数
- strip()删除其尾随空白符
- upper()/lower()改变字符串大小写
- replace()替换目标字符串中子串
- 正则表达式匹配
- 字典
利用字典结构获取单词频率:
string="I like you and you like me too!"
word_freq={}
for tok in string.split():
if tok in word_freq:
word_freq[tok]+=1;
else:
word_freq[tok]=1
print(word_freq)
结果如下:

2. 预处理网页:
用不到的HTML标签和其它多余字符,删除掉具有某一长度的单词
代码如下:
import urllib.request
#用urllib.request代替urllib2
import re
import nltk
from bs4 import BeautifulSoup
import operator
#Beautiful头文件
response=urllib.request.urlopen("http://www.nltk.org/api/nltk.html#nltk.util.clean_html")
html=response.read()
#html即网址获得的内容
clean=BeautifulSoup(html).get_text()
#利用BeautifulSoup来处理文本
tokens=[tok for tok in clean.split()]
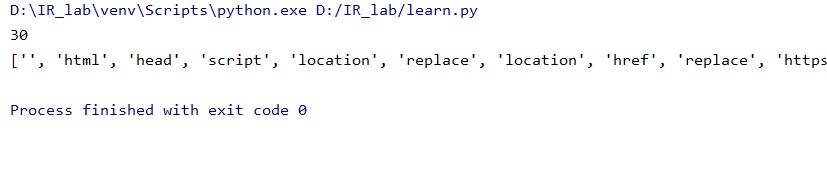
print(tokens[:100])
结果如下:
可以看出词项都非常精简,有效!!!
3. 统计词频:
(1)传统方法:
正确代码:
import urllib.request
#用urllib.request代替urllib2
import re
import nltk
from bs4 import BeautifulSoup
import operator
#Beautiful头文件
response=urllib.request.urlopen("http://www.nltk.org/api/nltk.html#nltk.util.clean_html")
html=response.read()
#html即网址获得的内容
clean=BeautifulSoup(html).get_text()
#利用BeautifulSoup来处理文本
tokens=[tok for tok in clean.split()]
#print(tokens[:24])
freq_dis = {}
for tok in tokens:
if tok in freq_dis:
freq_dis[tok]+=1
else:
freq_dis[tok]=1
#利用sorted来排序
sorted_freq_dist= sorted(freq_dis.items(), key=operator.itemgetter(1), reverse=True)
print(sorted_freq_dist[:25])
结果展示:

(2)利用NLTK库
代码:
import urllib.request
#用urllib.request代替urllib2
import re
import nltk
from bs4 import BeautifulSoup
import operator
#Beautiful头文件
response=urllib.request.urlopen("http://www.nltk.org/api/nltk.html#nltk.util.clean_html")
html=response.read()
#html即网址获得的内容
clean=BeautifulSoup(html).get_text()
#利用BeautifulSoup来处理文本
#以上是获取数据
#下述通过FreqDist来获取词频
tokens=[tok for tok in clean.split()]
Fre_dist_nltk=nltk.FreqDist(tokens)
print(Fre_dist_nltk)
for k,v in Fre_dist_nltk.items():
print(str(k)+':'+str(v))
结果展示:

利用nltk计算词频代码很短!!!
以上就是第一节!!!简单设计NLP内容;
下一节:
文本的歧义及其清理