


01 | 基本架构:一个键值数据库包含什么?
而 Redis 支持的 value 类型包括了 String、哈希表、列表、集合等。Redis 能够在实际业务场景中得到广泛的应用,就是得益于支持多样化类型的 value。

为了和 Redis 保持一致,我们的 SimpleKV 就采用内存保存键值数据。接下来,我们来了解下 SimpleKV 的基本组件。
大体来说,一个键值数据库包括了访问框架、索引模块、操作模块和存储模块四部分(见下图)。接下来,我们就从这四个部分入手,继续构建我们的 SimpleKV



02 | 数据结构:快速的Redis有哪些慢操作?



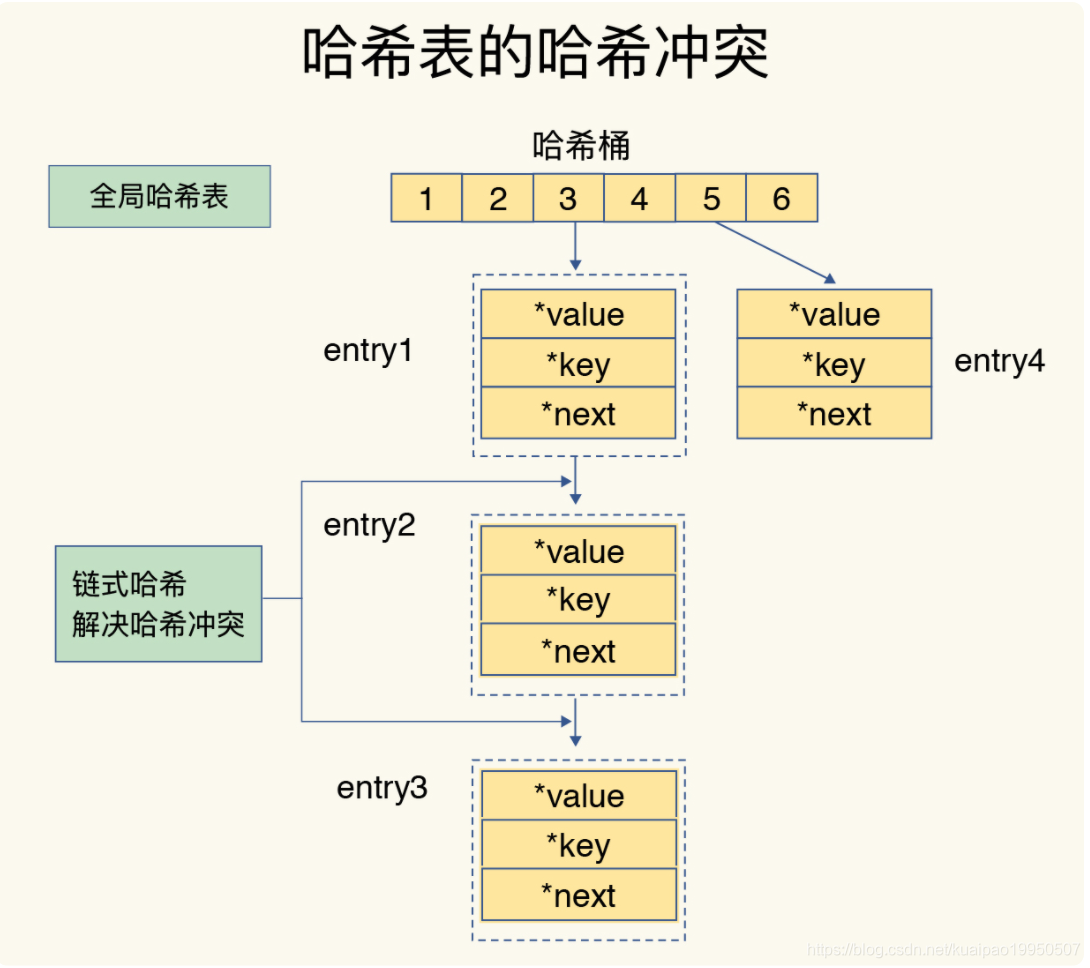
但是,这里依然存在一个问题,哈希冲突链上的元素只能通过指针逐一查找再操作。如果哈希表里写入的数据越来越多,哈希冲突可能也会越来越多,这就会导致某些哈希冲突链过长,进而导致这个链上的元素查找耗时长,效率降低。对于追求“快”的 Redis 来说,这是不太能接受的。
所以,Redis 会对哈希表做 rehash 操作。rehash 也就是增加现有的哈希桶数量,让逐渐增多的 entry 元素能在更多的桶之间分散保存,减少单个桶中的元素数量,从而减少单个桶中的冲突。那具体怎么做呢?
Redis 开始执行 rehash,这个过程分为三步:
1. 给哈希表 2 分配更大的空间,例如是当前哈希表 1 大小的两倍;
2. 把哈希表 1 中的数据重新映射并拷贝到哈希表 2 中;
3 .释放哈希表 1 的空间。
简单来说就是在第二步拷贝数据时,Redis 仍然正常处理客户端请求,每处理一个请求时,从哈希表 1 中的第一个索引位置开始,顺带着将这个索引位置上的所有 entries 拷贝到哈希表 2 中;等处理下一个请求时,再顺带拷贝哈希表 1 中的下一个索引位置的 entries。如下图所示

这样就巧妙地把一次性大量拷贝的开销,分摊到了多次处理请求的过程中,避免了耗时操作,保证了数据的快速访问



Redis 从 2.8 版本开始提供了 SCAN 系列操作(包括 HSCAN,SSCAN 和 ZSCAN),这类操作实现了渐进式遍历,每次只返回有限数量的数据。这样一来,相比于 HGETALL、SMEMBERS 这类操作来说,就避免了一次性返回所有元素而导致的 Redis 阻塞。