一 序
因为要迁移rocketmq 到新集群,梳理下对应的知识点。
内容来自于杨开元编写的《rocketmq 实战于原理解析》。
二 知识
2.1 基础知识
基础概念:Producer、 Consumer、 Broker 和 NameServer
配置参数含义:
l)namesrvAddr:NamerServer 的地址,可以是多个 。
2)brokerClusterName=Cluster 的地址,如果集群机器数比较多,可以分成多个 Cluster,每个 Cluster 供一个业务群使用 。
3)brokerName:
Broker 的名称, Master 和 Slave 通过使用相同的 Broker 名称来表明相互关系,以说明某个 Slave 是哪个 Master 的 Slave。
4) brokerid=一个 Master Barker可以有多个 Slave, 0表示 Master,大于 0表示不同 Slave 的 ID。
5) fileReservedTime=在磁盘上保存消息的时长,单位是小时,自动删除超时的消息.
6) deleteWhen=与 fileReservedTim巳参数呼应,表明在几点做消息删除动作
7) brokerRole=
brokerRole 有 3 种: SYNC MASTER、 ASYNC MASTER、 SLAVE。 关键 词 SY1叫C 和 ASYNC 表示 Master 和 Slave 之间同步消息的机制, SYNC 的意思 是当 Slave 和 Master 消息同步完成后,再返回发送成功的状态 。
8) flushDiskType=ASYNC FLUSH (这个影响丢不丢消息)
flushDiskType表示刷盘策略,分为SYNC_FLUSH和ASYNC_FLUSH两 种,分别代表同步刷盘和异步刷盘。 同步刷盘情况下,消息真正写人磁盘后再 返回成功状态;异步刷盘情况下,消息写人 page_cache 后就返回成功状态 。
9) listenPort=
Broker监听的端口 号,如果一台机器上启动了多个 Broker, 则要设置不同的端口号,避免冲 突。
10 ) storePathRootDir=存储消息以及一些配置信息的根目录 。
管理集群使用console控制台。
2.1consumer
1) Consumer的 GroupName用于把多个 Consumer组织到一起, 提高并发 处理能力, GroupName需要和消息模式 (MessageModel)配合使用。
RocketMQ支持两种消息模式: Clustering和Broadcasting。
在 Clustering模式下,同一个 ConsumerGroup(GroupName相同) 里的每 个 Consumer 只消费所订阅消 息 的一部分 内容, 同一个 ConsumerGroup 里所有的 Consumer消费的内容合起来才是所订阅 Topic 内容的整体, 从而达到负载均衡的目的 。
在 Broadcasting模式下,同一个 ConsumerGroup里的每个 Consumer都 能消费到所订阅 Topic 的全部消息,也就是一个消息会被多次分发,被 多个 Consumer消费。
2) NameServer 的地址和端口 号,可以填写多个 ,用分号隔开
3) Topic名称用来标识消息类型, 需要提前创建。 如果不需要消费某 个 Topic 下的所有消息,可以通过指定消息的 Tag 进行消息过滤,比如: Consumer.subscribe (”TopicTest”J’tagl 11 tag2 11 tag3”), 表示这个 Consumer要 消费“ TopicTest”下带有 tagl 或 tag2 或 tag3 的消息( Tag 是在发送消息时设 置 的标签) 。 在填写 Tag 参数的位置,用 null 或者“ V 表示要消费这个 Topic 的所有消息 。
DefaultMQPushConsumer
consumer通过“长轮询”方式达到 Push效果的方法,长轮询方式既有 Pull 的优点,又兼具 Push方式的实时性。“长轮询”的核 心 是, Broker 端 HOLD 住客户端过来的请求一小段时间,在这个时间内有新 消息到达,就利用现有的连接 立 刻返回消息给 Consumer。超过请求时间也没有消息,就返回空结果 。
consumer流量控制:
因为消费者使用了线程池,不好监控mq的积压情况,RocketMQ定义了一个快照类 ProcessQueue来解决这些问题。
ProcessQueue对象里主要的内容是一个 TreeMap 和一个读写锁。 TreeMap 里以 Message Queue 的 Offset作为 Key,以消息内容的引用为 Value,保存了 所有从 MessageQueue 获取到,但是还未被处理的消息; 读写 锁控制着多个线程对 TreeMap 对象的并发访 问 。
客 户 端在每次 Pull请求前会做下 面三个判断来控制流量(获取但还未处理的消息个数、消 息总大小、 Offset 的跨度),任何一个值超过设定的大小就隔一段时间再拉取消 息,从而达到流量控制的目的 。 此外 ProcessQueue 还可以辅助实现顺序消费的 逻辑。
DefaultMQPullConsumer
( 1 )获取 Message Queue 并遍历
( 2 )维护 Offsetstore
( 3 )根据不同的消息状态做不同的处理
Consumer 的启动、关闭流程
Consumer分为 Push和l Pull两种方式,对于 PullConsumer来说,要注意的是 Offset 的保存.
DefaultMQPushConsumer 的退出, 要调用 shutdown() 函数,以便 释放资 源、保存 Offset 等 。可以使用注解的方式:
@Bean(initMethod = "start", destroyMethod = "shutdown", name = "dataConsumer")
PushConsumer在启动的时候,如果遇到异常比如无法连接 NameServer,程序仍然 可以正常启动不报错(日 志里有 WARN 信息 )。
2.2 producer
生产者发送消息默认使用的是 DefaultMQProducer类,再发消息之前也需要配置参数:
DefaultMQProducer defaultMQProducer = new DefaultMQProducer(senderGroup);
defaultMQProducer.setNamesrvAddr(namesrvAddr);
defaultMQProducer.setInstanceName(senderInstanceName);
defaultMQProducer.setRetryTimesWhenSendFailed(6);消息的发送有同步和异步两种方式,消息发送的返回状态有如下四种 : FLUSH_DISK_SENDTIMEOUT 、 FLUSH_SLAVE_TIMEOUT、SLAVE_NOT_AVAILABLE 、OK,不同状态在不同的刷盘策略和同步策略的配置下含义是不同的 。
FLUSH_DISK_SENDTIMEOUT : 表示没有在规定时间内完成刷盘(需要 Broker 的刷盘策 Il创立设置成 SYNC_FLUSH 才会报这个错误) 。
FLUSH_SLAVE_TIMEOUT :表示在主备方式下,并且 Broker被设 置 成 SYNC_MASTER 方式,没有在设定时间内完成 主从同步 。
SLAVE_NOT_AVAILABLE : 这个状态 产生的场景和 FLUSH_SLAVE_TIMEOUT 类似, 表示在主备 方式下,并且 Broker被设置成 SYNC_MASTER,但是没有找到被配置成 Slave 的 Broker。
SEND_OK :表示发送成功,发送成功的具体含义,比如消息是否已经 被存储到融盘?消息是否被同步到了 Slave上?消息在 Slave上是否被 写人磁盘?需要结合所配置的刷盘策略、主从策略来定 。
发送延迟消息
RocketMQ 支持发送延迟消息, Broker收到这类消息后 ,延迟一段时间再处理, 使消息在规定的一段时间后生效。
调用 setDelayTimeLevel ( int level) 方法设置延迟时间,注意不要跟setDelayTime混了。
自定义消息发送规则
一个 Topic会有多个 Message Queue,如果使用 Producer的默认配置,这 个 Producer 会轮流向各个 Message Queue 发 送 消息。如果业务 需 要我们把消息 发 送到指定的 Message Queue 里,比如把同 一 类型 的消息都发 往 相同的 Message Queue,可以用 Message QueueSelector。
发送消息的时候,把 MessageQueueSelector 的对象作为参数,使用 public SendResult send ( Message msg, MessageQueueSelector selector, Object arg)函 数发送消 息即可 。 在 MessageQueueSelector 的实现中,根据传人的 Object参 数,或者根据 Message 消息内容确定把消息发往那个 Message Queue,返回被 选中的 Message Queue。
RocketMQ 采用两阶段提交 的方式实现事务消息,文字较长,找个图来替代
a: 发送半消息
b:执行本地事务
c:发送Commit/Rollback
d:提供回查接口
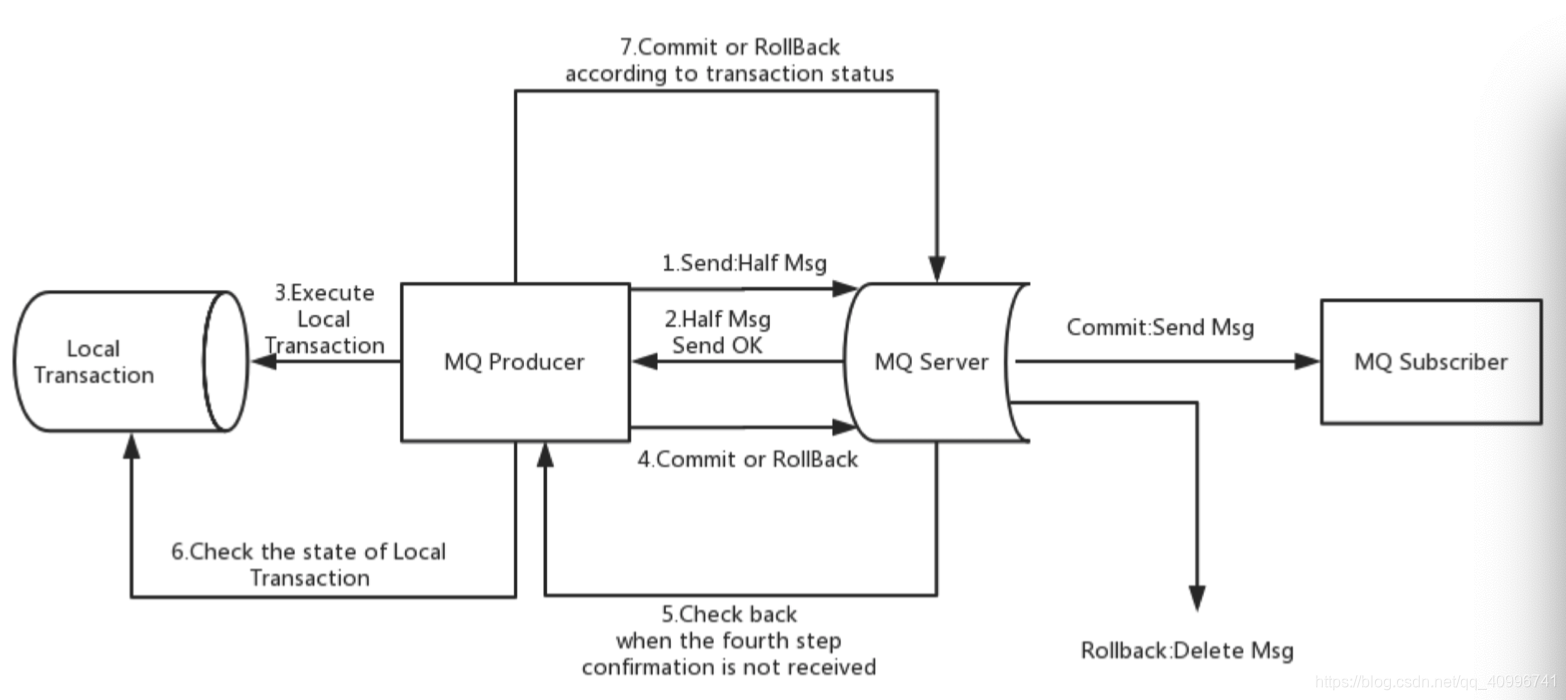
Offset是指某个 Topic下的一条消息在某个 Message Queue里的 位置,通过 Offset的值可以定位到这条消息,或者指示 Consumer从这条消息 开始向后继续处理 。
对于 DefaultMQPushConsurner来说,默认是 CLUSTERING 模 式,也就是同一个 Consumer group 里的多个消费者每人消费一部分,各自收到 的消息内容不一样 。由 Broker 端存储和控制 Offset 的值,使用 RemoteBrokerOffsetStore 结构 。
再BROADCASTING模式下,每个 Consumer 都收到这个 Topic 的全部消息,各个 Consumer 间相互没有干扰, RocketMQ 使 用 LocalfileOffsetStore,把 Offset存到本地 。
在使用DefaultMQPushConsumer的时候,我们不用关心OffsetStore的 事,但是如果 PullConsumer,我们就要自己处理 OffsetStore了。
2.3 nameserver
NameServer是整个消息队列中 的状态服务器,集群的各个组件通过它来了 解全局的信息 。NamServer可以部署多个,相互之间独立,其他角色同时向多个 NameServer 机器上报状态信息,从而达到热备份的目的。 NameServer本身是无状态的,也就 是说 NameServer 中的 Broker、 Topic 等状态信息不会持久存储,都是由各个角色 定时上报并存储到内存中的.
在org.apache.rocketmq.namesrv.routeinfo的RoutelnfoManager类中,有五 个变量 ,集群的状态就保存在这五个变量中
topicQueueTable
topicQueueTable 这个结构的 Key 是 Topic 的名称,它存储了所有 Topic 的属性信息 . Value 是个 QueueData 队列 , 队里的长度 等于这 个 Topic 数据存储的 MasterBroker的个数, QueueData里存储着 Broker的名称、 读写queue的数量、 同步标识等。
Broker- AddrTable
以 BrokerName 为 索 引 ,相 同 名 称的 Broker 可能存在多台机器,一个 Master 和多个 Slave。 这个结构存储着一个 BrokerName 对应的属性信 息,包括所属的 Cluster 名称, 一 个 Master Broker 和多个 Slave Broker 的地址信息 。
ClusterAddrTable
存储的是集群中 Cluster 的信息,结果很简单,就是一个 Cluster 名称对 应一个由 BrokerName组成的集合。
Broker- LiveTable
这个结构和 BrokerAddrTable有关系,但是内容完全不同,这个结构的 Key 是 BrokerAddr,也就是对应着一台 机器, BrokerAddrTable 中的 Key 是BrokerName, 多个机器的BrokerName可以相同。 BrokerLiveTable 存储的内容是这台 Broker机器的实时状态,包括上次更新状态的时间 戳, NameServer会定期检查这个时间戳,超时没有更新就认为这个 Broker无效了,将其从 Broker列表里清除。
filterServerTable
Filter Server是过滤服务器,是 RocketMQ 的一种服务端过滤方式,一 个 Broker 可以有 一个 或 多个 Filter Server。 这个结构的 Key 是 Broker 的地址, Value 是和这个 Broker关联的多个 Filter Server 的地址 。
为什么不用zookeeper?
RocketMQ 的 NameServer 只有很少的代码,不需要zk的复杂功能。
底层通信机制
分布式系统各个角色间的通信效率很关键,通信效率的高低直接 影 响系 统性能,
RemotingService 为最上层接口,RemotingClient和 RemotingServer继承 RemotingService接口,并增加 了 自己特有的方法 。通过上面的封装 , RocketMQ各个模块间的通信, 可以通过发送统一格式 的自定义消息 (RemotingCommand) 来完成, 各个模块间的通信实现简洁明了 。RocketMQ是基于Netty库来完成RemotingServer和RemotingClient具体的 通信实现的,屏蔽了底层的socket、NIO等复杂细节。
3 消息队列的核心机制
3.1 消息的存储和发送
分布式队列因为有高可靠性的要求,所以数据要通过磁盘进行持久化存储 。用磁盘存储消息顺序写速度可以达到 600MB/s,随机的速度只有大概 100KB/s,差别很大。
通过使用 mmap 的方式,可以省去向用户态的内存复制,提高速度 。 这 种机制在 Java 中是通过 MappedByteBuffer 实现的。也就是所谓的“零拷贝”技术,提高消息存 盘和网络发送的速度 。
3.2 消息存储结构
RocketMQ消息的存储是由ConsumeQueue和CommitLog配合完成的, 消息真正的物理存储文件是 CommitLog, ConsumeQueue 是消息的逻辑队 列,类似数据库的索引文件,存储的是指向物理存储的地址 。 每个 Topic 下 的每个 Message Queue都有一个对应的 ConsumeQueue 文件 。 文件地址在 ${$storeRoot}\consumequeue\${topicName}\${queueld}\${fileName}。

CommitLog 以物理文件的方式存放,每台 Broker上的 CommitLog被本 机器所有 ConsumeQueue 共 享,文 件地址:$ {user.home} \store\${commitlog}\ ${白leName}。 在 CommitLog 中,一个消息的存储长度是不固定的, RocketMQ 采取一些机制,尽量 向 CommitLog 中顺序写 ,但是随机读 。ConsumeQueue 的 内容也会被写到磁盘里作持久存储 .
存储机制这样设计有以下几个好处:
1 ) CommitLog 顺序 写 ,可以大大提 高写人效率 。
2 ) 虽然是随机读,但是利用操作系统的 pagecache机制,可以批量地从磁 盘读取,作为cache存到内存中,加速后续的读取速度。
3 )为了保证完全的顺序写,需要 ConsumeQueue 这个中间结构 ,在实际情况中,大部 分的 ConsumeQueue 能够被全部读人内存,可以认为是内存读取的速度 。
3.3 高可用机制
RocketMQ 分布式集群是通过 Master 和 Slave 的配合达到高可用性的,Master角色 的 Broker支持读和写, Slave角色的 Broker仅支持读。
在 Consumer 的配置文件中,并不需要设置是从 Master读还是从 Slave 读,有自动切换 Consumer 这种机制,当一个 Master 角色的机器出现故障后, Consumer 仍然可以从 Slave 读取消息,不影响 Consumer 程序 。
如何达到发送端的高可用性呢?在创建 Topic 的时候,把 Topic 的多个 Message Queue创建在多个 Broker组上(相同 Broker名称,不同 brokerId 的 机器组成 一 个 Broker 组),这样当 一 个 Broker 组的 Master 不可用后,其他组 的 Master 仍然可用, Producer 仍然可以发送消息。
3.4 同步刷盘和异步刷盘
RocketMQ 为了提高性能,会尽可能地保证 磁盘的顺序写 。
异步刷盘方式:在返回写成功状态时 ,消息可 能只是被写人了内存的 PAGECACHE ,写操作的返回快,吞吐 量大 ;当内存里的消息 量 积累到 一定程度时 ,统一触发 写磁盘动 作,快速 写人 。
同步刷盘方式:在返回写成功状态时,消息已经被写人磁盘 。 具体流程 是,消息、写入内存的 PAGECACHE 后,立刻通知刷盘线程刷盘,然后 等待刷盘完成,刷盘线程执行完成后唤醒等待的线程,返回消息写成功 的状态 。
同步刷盘还是异步刷盘,是通过 Broker 配置文件里的 flushDiskType 参数 设置的,这个参数被配置成 SYNC FLUSH、 ASYNC FLUSH 中的一个。
3.5 同步复制还是异步复制
如果一个 Broker组有 Master和 Slave, 消息需要从 Master复制到 Slave 上,同步复制方式是 等 Master 和 Slave 均写成功 后才反馈给客户端写成功状态;异步复制方式是只要 Master 写成功即可反馈给 客户端写成功状态 。
异步复制:优点性能好,缺点可能丢失数据(只写入master没写入slave)
同步复制:优点slave数据有全量,缺点性能差。
实际应用中要结合业务场景,合理设置刷盘方式和主从复制方式,尤其是 SYNC FLUSH 方式,由于频 繁 地触发磁盘 写动 作, 会明显 降低性能 。 通常情 况下,应该把 Master和 Save配置成 ASYNC FLUSH 的刷盘方式,主从之间配 置成 SYNC MASTER 的 复制方式,这 样即使有 一台机器出故障, 仍然能保证 数据不丢,是个不错的选择 。
4 可靠性优先的使用场景
4.1 顺序消息
全局顺序消息
RocketMQ 在 默认情 况下不保证顺序,要保 证全局顺序消息, 需要先把Topic 的读写队列数设置为一,然后 Producer 和 Consumer 的并发设置也要是一。就是牺牲了性能。在实际应用中,更多的是像订单类消息那样,只需要部分有序即可。依然可以保持高并发性能。
部分顺序消息
要保证部分消息有序,需要发送端和消费端配合处理 。 在发送端,要做到 把同一业务 ID 的消息发送到同一个 Message Queue ;在消费过程中,要做到从 同一个 Message Queue 读取的消息不被并发处理,这样才能达到部分有序 。
4.2 消息重复问题
消费方自己做幂等就好。
4.3 动态增加机器
nameserver除了http的方式,通常需要修改配置后重启生效。
动态增减broker:
只增加 Broker 不会对原有的 Topic 产生影响,原来创建好的 Topic 中数 据的读写依然在原来的那些 Broker上进行。
集群扩容后, 一 是可以 把新 建的 Topic 指定到新的 Broker 机器上,均衡利 用资源;另一种方式是通过 updateTopic命令更改现有的 Topic 配置,在新加 的 Broker 上创建新的队列 。
减少 Broker:当一个 Topic 只有一个 Master Broker,停掉这个 Broker后,消息的发送肯定会受到影响.当某个 Topic有多个 Master Broker,停了其中一个.如果使用同步方 式 send ( msg)发送,在 DefaultMQProducer 内部有个自动重试逻辑不会丢消息,如 果使用异步方式发送 send ( msg, callback),或者用 sendOneWay方式,会 丢失切换过程中的消息 。
如果 Producer 程序能够暂停,在有一个Master 和一个Slave 的情况下也可 以顺利切换 。 可以关闭 Producer 后关闭 Mast巳r Broker,这个时候所有的读取都 会被定向到 Slave机器,消费消息不受影响。 把MasterBroker机器置换完后, 基于原来的数据启动这个 Master Broker,然后再启动 Producer 程序正常发送消息 。
4.4各种故障对消息的影响
1 )多 Master,每个 Master 带有 Slave;
2 )主从之间设置成 SYNC_MASTER;
3 ) Producer 用同 步方式写;
4 )刷盘策略设置成 SYNC FLUSH。
就可以消除单点依赖,即使某台机器出现极端故障也不会丢消息 。
4.5 消息优先级
RocketMQ 是个先人先出的队列,不支持消息级别或者 Topic 级别的优先级 。 业务中简单的优先级需求,可以通过间接的方式解决。下面举例介绍场景:
1同一个topic里面:包含大量A\B,消息,C消息少来了处理不及时。可以单独给C一个topic。
2 很多发消息入口,队列有限,某个入口业务量较大,影响其他入口发送,可以创建一个Topic, 设置Topic 的 MessageQueue 数量超过发送方入口数量,轮询发送。
3是强优先级需求,a>b>c, 消费者自己编码处理。
5 吞吐量优先的使用场景
5.1 在 Broker 端进行消息过滤
在 Broker端进行消息过滤,可以减少元效消息发送到 Consumer,少占用网络带宽从而提高吞吐量 。 Broker端有三种方式进行消息过滤 。
消息的Tag和Key
对一个应用来说,尽可能只用一个 Topic,不同的消息子类型用 Tag来标识,服务器端基于 Tag 进行过滤,并不需要读取消息体 的内容,所以效率很高 。发送消息设置了Tag 以后,消费方在订阅消息时,才可以利用 Tag 在 Broker 端做消息过滤 。
其次是消息的 Key。对发送的消息设置好 Key,以后可以根据这个 Key 来 查找消息。Broker会创建专门的索引文件,来存 储 Key 到消息的映射,由于是哈希索引,应尽量使 Key唯一 ,避免潜在的哈希冲突。
Tag用在 Consumer的代码中,用 来进行服务端消息过滤, Key 主要用于通过命令行查询消息 。
此外,还支持SQL方式、filter方式过滤。
5.2 提高consumer消费能力
1)同一个 ConsumerGroup 下( Clustering 方式),可以通过增加 Consumer 实例的数量来提高并行度。注意总的 Consumer数量不要超过 Topic下 Read Queue 数量,超过的 Consumer 实例接收不到消息 。 此外,通过提高单个 Consumer 实例中的并行处理的线程数 可以在同一个 Consumer 内增加并行度 来提高吞吐量(设置方法是修改 consumeThreadMin 和 consumeThreadMax)。
( 2 )以批量方式进行消费
( 3 )检测延时情况,跳过非重要消息
5.3 Consumer 的负载均衡
在 RocketMQ 中,负载均衡或者消息分配是在 Consumer端代码中完成的, Consumer从 Broker处获得全局信息,然后自己做 负载均衡,只处理分给自己的那部分消息。
DefaultMQPushConsumer:自动处理
Pull Consumer可以看到所有的 Message Queue, 而且从哪个 Message Queue读取消息,读消息时的 Offset都由使用者控制。可以通过registerMessageQueueListener实现。
5.4 提高 Producer 的发送速度
发送一条消息出去要经过三步,一是客户端发送请求到服务器,二是服务器处理该请求, 三是 服务器向客户端返回应答, 一次 消息的发送耗时是上述 三 个步骤的总和 。在一些对速度要求高,但是可靠性要求不高的场景下,比如日 志收集类应用 ,可以 采用 Oneway 方式发 送, Oneway 方式只发送请求不等待应答,即将数据写人客户端的 Socket缓冲区就返回,不等待对方返回结果。(都这样了,还不如用kafka呢)
2使用多个 Producer 同时发送.
性能调优的一般步骤:
1. 查看CPU
top
top - 19:01:16 up 665 days, 7:22, 1 user, load average: 0.83, 0.91, 1.06
Tasks: 700 total, 1 running, 699 sleeping, 0 stopped, 0 zombie
%Cpu(s): 1.7 us, 1.0 sy, 0.0 ni, 96.9 id, 0.3 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 49049564 total, 343284 free, 46103464 used, 2602816 buff/cache
KiB Swap: 8191996 total, 652 free, 8191344 used. 966580 avail Mem可见CPU空闲96.9 ,负载也在1之下。内存有300M空闲
查看网卡空闲 :sar –n DEV 1 4
sar它有6个不同的开关:DEV | EDEV | NFS | NFSD | SOCK | ALL 。DEV显示网络接口信息,EDEV显示关于网络错误的统计数据,NFS统计活动的NFS客户端的信息,NFSD统计NFS服务器的信息,SOCK显示套 接字信息,ALL显示所有5个开关。它们可以单独或者一起使用。我们现在要用的就是-n DEV了,上面意思是每秒取值1次,取四次

- IFACE: LAN接口, 网络设备的名称。
- rxpck/s: 每秒钟接收的数据包 。
- txpck/s:每秒钟发送的数据包 。
- rxbyt/s:每秒钟接收的 字节数 。
- txbyt/s:每秒钟发送的字节数 。
- rxcmp/s: 每秒钟接收的压缩数据包。
- txcmp/s:每秒钟发送的压缩数据包 。
- rxmcst/s: 每秒钟接收的 多播数据包 。
*8%1024换算成Mb.对比网卡的上限。
iperf3是用来测量一个网络最大带宽的工具。可以安装后验证网卡是否达到了极限值。
或者watch工具。
磁盘IO:
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 12.00 0.00 105.00 0.00 0.75 14.63 7.04 67.03 0.00 67.03 1.67 17.50通常排除以上情况,还需要排查锁机制,线程阻塞。
六 迁移
通常先迁移producer,再consumer确认消费完之后,
更新配置,重新发布。