编写java文件:
项目驱动:
package com.hadoop.weblog;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* 该项目的 驱动类
* @author naixi
*
*/
public class WebLogDriver extends Configured implements Tool {
public static void main(String[] args) {
Configuration conf = new Configuration();
try {
int status = ToolRunner.run(conf, new WebLogDriver(), args);
System.exit(status);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public int run(String[] args) throws Exception {
Job job = Job.getInstance(this.getConf(),"baidu-test");
job.setJarByClass(WebLogDriver.class);
//input
Path inputPaths = new Path(args[0]);
FileInputFormat.setInputPaths(job, inputPaths);
//map
job.setMapperClass(WebLogMapper.class);
job.setMapOutputKeyClass(WebLogWritable.class);
job.setMapOutputValueClass(NullWritable.class);
//shuffle
//reduce
//我们在这里项目案例中 , 我们做的就是数据清洗 清洗一条输出一条 不需要聚合
job.setNumReduceTasks(0); //将reduce任务设置为0
//output
Path Paths = new Path(args[1]);
FileSystem fileSystem = FileSystem.get(this.getConf()); //实例化一个Hadoop的文件系统对象
if(fileSystem.exists(Paths)) { //如果这个文件夹存在就删除
fileSystem.delete(Paths,true); //使用递归删除该文件夹
}
FileOutputFormat.setOutputPath(job, Paths);
boolean flag = job.waitForCompletion(true);
return flag?0:1;
}
}
mapper类文件:
package com.hadoop.weblog;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* 该项目的数据Mapper类
* KEYIN
* , VALUEIN
* , KEYOUT
* , VALUEOUT
* @author naixi
*
*/
public class WebLogMapper extends Mapper<LongWritable, Text, WebLogWritable, NullWritable> {
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, WebLogWritable, NullWritable>.Context context)
throws IOException, InterruptedException {
String line = value.toString();
WebLogWritable web = WebLogWritableUtil.getWebLogWritable(line);
if(web.isFlag()) {
context.write(web, NullWritable.get());
}
}
}
搜索字段代码:
package com.hadoop.weblog;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
/**
* 专门针对(面向对象)的项目创建一个对象
* 搜索的关键字
* sessionid
* 思考如何让这个类成为Hadoop的类
* Int -》 IntWritable , null -》 NullWritable
* @author naixi
*
*/
public class WebLogWritable implements WritableComparable<WebLogWritable> {
private boolean flag = true; //标记变量 如果为脏数据 就把这个变量标记为false 就丢弃数据
private String keyWord;
private String sessionid;
public WebLogWritable() {
super();
// TODO Auto-generated constructor stub
}
public WebLogWritable(boolean flag, String keyWord, String sessionid) {
super();
this.flag = flag;
this.keyWord = keyWord;
this.sessionid = sessionid;
}
public boolean isFlag() {
return flag;
}
public void setFlag(boolean flag) {
this.flag = flag;
}
public String getKeyWord() {
return keyWord;
}
public void setKeyWord(String keyWord) {
this.keyWord = keyWord;
}
public String getSessionid() {
return sessionid;
}
public void setSessionid(String sessionid) {
this.sessionid = sessionid;
}
@Override
public String toString() {
return keyWord + "\t" + sessionid ;
/*
* java\tA13D054DFE841FB3FDDD2E79BB313C62
*/
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + (flag ? 1231 : 1237);
result = prime * result + ((keyWord == null) ? 0 : keyWord.hashCode());
result = prime * result + ((sessionid == null) ? 0 : sessionid.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
WebLogWritable other = (WebLogWritable) obj;
if (flag != other.flag)
return false;
if (keyWord == null) {
if (other.keyWord != null)
return false;
} else if (!keyWord.equals(other.keyWord))
return false;
if (sessionid == null) {
if (other.sessionid != null)
return false;
} else if (!sessionid.equals(other.sessionid))
return false;
return true;
}
/**
* 实现对象的持久化 -》 将内存中的对象 写成磁盘中的文件
*/
public void write(DataOutput out) throws IOException {
out.writeUTF(keyWord);
out.writeUTF(sessionid);
}
/**
* 实现持久化 -》 将磁盘中的文件读取为对象
*/
public void readFields(DataInput in) throws IOException {
//!!注意 读取的顺序必须和写入的顺序一致!!
this.keyWord=in.readUTF();
this.sessionid=in.readUTF();
}
/**
* 实现可比较
* 用这个方法来指定 两个对象的大小 可以在后期实现排序功能 等
*/
public int compareTo(WebLogWritable arg0) {
// 0 表示一样大 如果是 >0 表示这个比被比较的大 返回的是<0表示 比被比较的小
//return 0;
int com = this.keyWord.compareTo(arg0.keyWord);
if(com==0) { //两个都是Java 则会出现 返回0的情况 那么就继续比较sessionid
com = this.sessionid.compareTo(arg0.sessionid);
}
return com;
}
}
数据清洗:
package com.hadoop.weblog;
/**
* 工具类 用来对数据进行清洗
* 如果是脏数据 就设置flag=false
* @author naixi
*
*/
public class WebLogWritableUtil {
public static WebLogWritable getWebLogWritable(String line) {
/*
* String line从哪里来?
* 在Mapper里的VALUEIN
* 在这里对数据进行清洗和过滤
*/
WebLogWritable web = new WebLogWritable();
/*
* 0 192.168.194.1
* 1 -
* 2 -
* 3 [04/Aug/2019:14:59:29
* 4 +0800]
* 5 "GET
* 6 /Web01/?wd=hadoop
* 7 HTTP/1.1"
* 8 200
* 9 239
* 10 A13D054DFE841FB3FDDD2E79BB313C62
*/
String[] items = line.split(" ");
if(items.length>=11) {
//获取keyword
if(items[6].indexOf("=")>0) {
String keyWord = items[6].substring(items[6].indexOf("=")+1); //为什么要+1,我不要=
web.setKeyWord(keyWord);
}else {
web.setFlag(false);
}
//获取sessionid
if(items[10].length()<=0 | "-".equals(items[10])) {
web.setFlag(false);
}else {
String sessionid = items[10];
web.setSessionid(sessionid);
}
}else {
web.setFlag(false);
}
return web;
}
}
将上述四个java文件写好后 进行打包:

打开集群 方便后续 将java四个文件打包后上传到/opt/datas 中:

上传文件后 编写运行文件:

配置运行文件变量:

编写baiduhive.sql文件


新开一个窗口 登录:
创建数据库:

使用数据库:

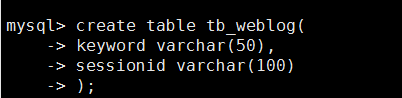
在数据库中建表:
回到第一个窗口 编写baidu.sqoop:


编写文件后 进行运行 输入 ./baidurun.sh
查明原因后 修改权限 再次运行:

在第二个窗口查询结果:
