day17
一.循环导入问题
循环导入问题指的是在一个模块加载,导入的过程中导入另外一个模块
而在另外一个模块中又返回来导入第一个模块中的名字,由于第一个模块尚未加载完毕,所以引用失败,抛出异常
# 循环导入:
run.py导入m1模块
m1模块导入m2模块
m2模块导入m1模块
# 循环导入问题:
# m1模块中的代码
print('正在导入m1')
from m2 import y # ==>
x='m1'
# m2模块中的代码
print('正在导入m2')
from m1 import x
y='m2'
# run.py中的代码
x=1
import m1
print(m1.x)
print(m1.y)
# 运行run.py输出的内容
正在导入m1
正在导入m2
# ImportError: cannot import name 'x' from partially initialized module 'm1' (most likely due to a circular import) (E:\A作业\m1.py)
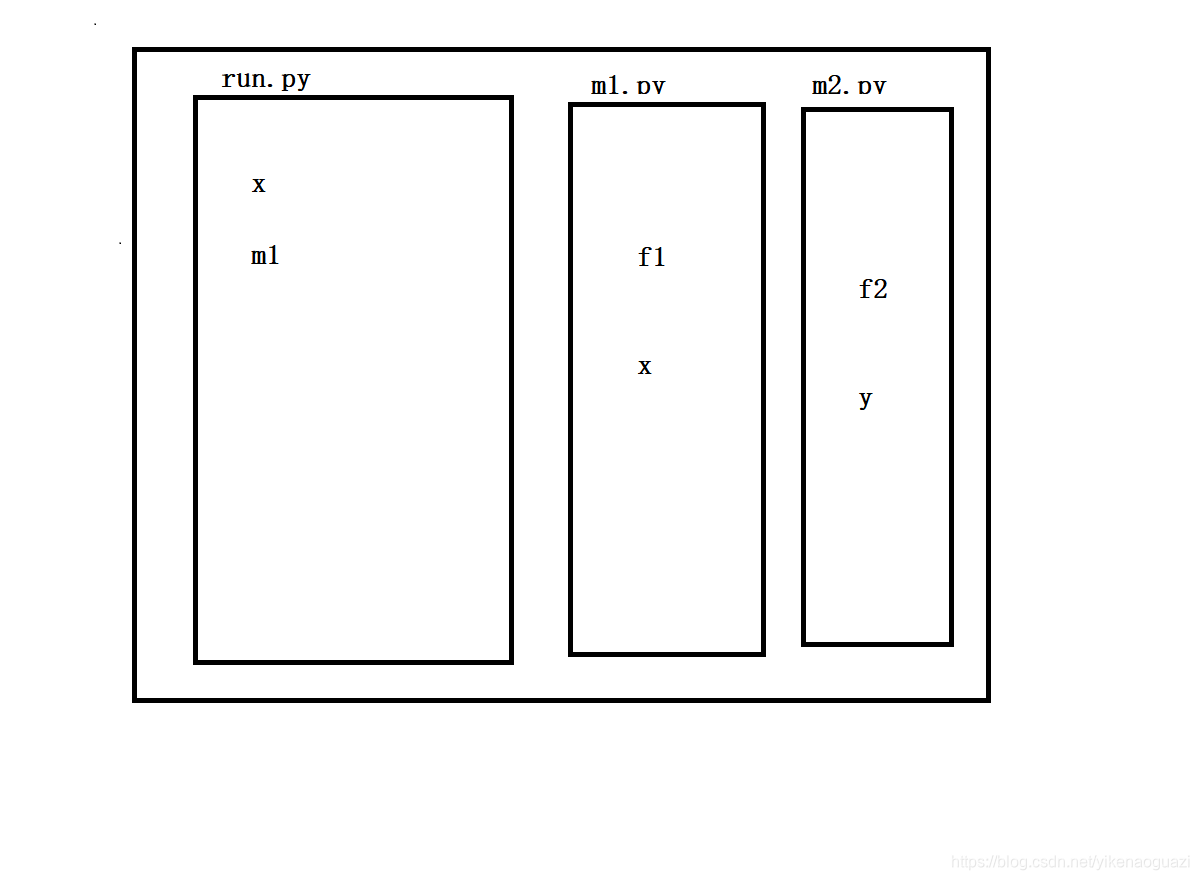
在这种情况下运行run.py,由于x,y这两个变量名在导入模块之后,所以还未来得及加载到名称空间中,所以引用失败,会抛出异常.
解决方案:
1.导入语句放到最后,保证在导入时,所有名字都已经加载过(不推荐)
2.导入语句放到函数中,只有在调用函数时才会执行其内部代码
方案1:
# m1.py
print('正在导入m1')
x='m1'
from m2 import y
print(x,y)
# m2.py
print('正在导入m2')
y='m2'
from m1 import x
print(x,y)
# run.py
x=1
import m1
print(m1.x)
print(m1.y)
import m2
# 运行结果:
正在导入m1
正在导入m2
m1 m2
m1 m2
m1
m2
方案2:
# m1.py
print('正在导入m1')
def f1():
from m2 import y
print(x,y)
x='m1'
# m2.py
print('正在导入m2')
def f2():
from m1 import x
print(x,y)
y='m2'
# run.py
x=1
# import m1
# print(m1.x)
# print(m1.y)
# m1.f1()
import m2
m2.f2()
# 运行结果:
正在导入m2
正在导入m1
m1 m2
总结:涉及到循环导入问题,可以将导入语句放到要使用此模块的函数内
二.区分python文件的2种用途
1.被当做程序运行(直接运行):直接右键运行该python文件
为了区别同一个文件的不同用途,每个py文件都内置了__name__变量,该变量在py文件被当做脚本执行时赋值为’main’,在py文件被当做模块导入时赋值为模块名
2.被当做模块运行:作为模块,被import导入到其他文件中
作为自定义模块的开发者,可以在文件末尾基于__name__在不同应用场景下值的不同来控制文件执行不同的逻辑
# spam.py
def f1():
print('spam.f1')
def f2():
print('spam.f2')
# print(__name__) # 当文件被当作脚本直接执行时,__name__值为"__main__"
# print(__name__) # 当文件被当作模块导入时,__name__值为"模块名"
# 作用:用来控制.py文件在不同的应用场景下执行不同的逻辑
if __name__ == '__main__':
print("文件被当作脚本执行时要做的事情")
f1()
f2()
三.模块的搜索路径与查找优先级
(1)先从内存中已经导入的模块里找
举个栗子:
import spam # 内存中已经有spam了
spam.read1()
import time
time.sleep(10) # 在等待的10s时间内快速删除spam模块
print('='*15)
import spam
spam.read1()
# 首次运行结果:还未删除spam模块
from the spam.py
spam模块:
# 运行结果解析:
# 虽然已经删除spam模块,但是spam模块在第一次导入时已经加载到内存中,所以第二次导入会从内存中查找,找到之后正常运行
# 重新运行结果:已删除spam模块
Traceback (most recent call last):
File "E:/A作业/测试.py", line 16, in <module>
import spam
ModuleNotFoundError: No module named 'spam'
# 运行结果解析:
# 重新运行程序意味着上次的执行先关闭了,程序关闭,内存中的东西都会释放,在内存中的spam模块被释放掉,在硬盘中存储的spam模块被删除,找不到此模块,抛出异常
(2)然后再查找内置的模块
# 查看已经加载到内存中的模块
# import sys
# print(sys.modules)
#sys.modules是一个全局字典,该字典是python启动后就加载在内存中。每当程序员导入新的模块,sys.modules都将记录这些模块。
# 查找当前执行文件所在的文件夹
import logging
print(logging)
# import sys
# python中查找模块的环境变量
# print(sys.path) # 会输出python搜索模块的路径列表.其中第一个文件夹是当前执行文件所在的文件夹
(3)最后去sys.path列表中存放的多个文件夹里依次检索
sys.path使用场景:
在实际开发中,默认包含了当前目录为搜索路径,所以,当前目录下的模块和子模块均可以正常访问。但是若一个模块需要import平级的不同目录的模块,或者上级目录里面的模块,就可以通过修改path来实现
在模块里面修改sys.path值,这种方法修改的sys.path作用域只是当前进程,进程结束后就失效了
示例1:
import sys
print(sys.path)
sys.path.append(r'E:\A作业\aaa\bbb')
import ccc
ccc.f1()
示例2:
import sys
print(sys.path)
import aaa.bbb.ccc as c
c.f1()
from aaa.bbb import ccc
ccc.f1()
os.path.dirname(path):返回文件路径
import os
print(__file__) # D:\python全栈15期\day17\ATM\conf\settings.py
# 拼接文件路径
BASE_DIR=os.path.dirname(os.path.dirname(__file__)) # D:\python全栈15期\day17\ATM\
log_path = os.path.join(BASE_DIR,'log','access.log')
四.软件开发目录规范
• core/: 存放业务逻辑相关代码
-- core.py
• api/: 存放接口文件,接口主要用于为业务逻辑提供数据操作。
-- api.py
• db/: 存放操作数据库相关文件,主要用于与数据库交互
-- db_handle.py
• lib/: 存放程序中常用的自定义模块
-- common.py
• conf/: 存放配置文件
-- settings.py
• run.py: 程序的启动文件,一般放在项目的根目录下,因为在运行时会默认将运行文件所在的文件夹作为sys.path的第一个路径,这样就省去了处理环境变量的步骤
• setup.py: 安装、部署、打包的脚本。
• requirements.txt: 存放软件依赖的外部Python包列表。
• README: 项目说明文件
README.cmd的主要内容:
1、软件定位,软件的基本功能;
2、运行代码的方法: 安装环境、启动命令等;
3、简要的使用说明;
4、代码目录结构说明,更详细点可以说明软件的基本原理;
5、常见问题说明。