那么有没有一种添加和删除数据的效率很高的数据结构呢?这就是下面我们要介绍的链表了。这是一种全新的数据结构,需要用到指针。链表是用一个个结点组成的。
下面就要开始使用指针了。如果读者还没有弄明白指针的知识,或者就不想用指针,那就可以跳过这一小节。在下一节中,我们将使用数组模拟链表。
我们先来看看结点的声明和组成:
声明结点的结构体:它由具体数据和指向下一个结点的指针组成。
struct Node{
int num; //具体数据
struct Node * next; //指向下一个结点的指针
};
获得变量有两种方式,分别是普通结构体变量和指针变量:
struct Node head; //普通的结构体变量:头结点
struct Node * temp;//指向结构体的指针变量
我们在head后面添加新节点。添加结点有三种方式:
1、在链表的指定位置插入新节点
void insertNodeAt(int index, int n)
{
//向操作系统申请一段内存空间,并强制转化成node的指针
struct Node * node = (struct Node *)(malloc(sizeof(struct Node)));
node->num = n; //为node结点赋值
node->next = NULL; //为node结点赋值
struct Node * currentNode; //当前结点的指针
currentNode = &head; //当前结点的指针指向head结点
struct Node * temp; //临时结点的指针
for(int i = 0; i < index - 1; i++) //遍历到index的父节点
{
currentNode = currentNode->next;
}
//这时,currentNode是index的父节点
node->next = currentNode->next;
currentNode->next = node; //更换currentNode的next结点。也就是插入操作
head.num++;//head结点的num表示这个链表一共有几个结点
}
2、在链表的头部 (紧挨着head的位置) 添加新节点
void insertNodeAtFirst(int n)
{
insertNodeAt(1, n);
}
2、在链表最后插入结点
void appendNode(int n)//在尾部添加结点
{
int size = head.num;
insertNodeAt(size + 1, n);
}
链表中删除结点也有三种,分别是:
1、删除指定index的结点:
void removeNode(int index) //删除指定index的结点
{
struct Node * currentNode; //当前结点的指针
struct Node * temp; //结点的临时指针
currentNode = &head; //当前结点的指针指向head结点
for(int i = 0; i < index - 1; i++) //遍历到index的父节点
{
currentNode = currentNode->next;
}
//这时,currentNode是index的父节点
//用temp指向要删除的index结点
temp = currentNode->next;
currentNode->next = currentNode->next->next; //删除index的结点
free(temp); //要回收内存
head.num--; //head结点的num表示这个链表一共有几个结点
}
2、删除第一个结点
void removeFirstNode()
{
removeNode(1);
}
3、删除最后一个结点
void removeLastNode()
{
int size = head.num;
removeNode(size);
}
获得结点的数据也有三种:
1、获得指定位置的结点的数据
int getNum(int index)
{
struct Node * currentNode; //当前结点的指针
currentNode = &head; //当前结点的指针指向head结点
//历,找到index结点
for(int i = 0; i < index; i++)
{
currentNode = currentNode->next;
if(currentNode == NULL) //防止出错
{
return -1; //出错时返回-1
}
}
return currentNode->num; //返回指定位置的结点的数据
}
2、获得第一个结点的数据
int getFirstNum()
{
return getNum(1);
}
3、获得最后一个结点的数据
int getLastNum()
{
int size = head.num;
return getNum(num);
}
设置index位置的结点的数据也有三种方式。这里只编写设置指定位置的结点的数据。其余两种请读者自行完成 (设置第一个结点的数据和最后一个结点的数据)。可以看到,设置结点的数据与获得结点的数据的代码极其相似。
1、设置指定位置的结点的数据
void setNum(int index, int n)
{
struct Node * currentNode; //当前结点的指针
currentNode = &head; //当前结点的指针指向head结点
//遍历,找到index结点
for(int i = 0; i < index; i++)
{
currentNode = currentNode->next;
if(currentNode == NULL)
{
return;
}
}
currentNode->num = n; //设置index结点的数据
}
下面是遍历整个数组的代码:
void traverse() //遍历
{
struct Node *currentNode; //当前结点的指针
currentNode = head.next; //当前结点的指针指向head结点的下一个结点
while(currentNode != NULL) //遍历
{
printf("%d, ", currentNode->num); //输出结点信息
currentNode = currentNode->next; //跳转到下一个结点
}
printf("\r\n");
}
最后,记得删除所有的指针,释放内存
void release()
{
struct Node * temp; //结点的临时指针
while(head.next != NULL) //当head结点的next不为NULL时循环
{
temp = head.next; //用temp记录head结点的子节点
head.next = head.next->next; //删除head结点的子节点
free(temp); //回收内存
}
}
总体的代码如下:
#include <stdio.h>
#include <stdlib.h>
//声明结点的结构体
struct Node{
int num; //具体数据
struct Node * next; //指向下一个结点的指针
};
struct Node head; //普通的结构体变量:头结点
void insertNodeAt(int index, int n) //在链表的指定位置插入新节点
{
//向操作系统申请一段内存空间,并强制转化成node的指针
struct Node * node = (struct Node *)(malloc(sizeof(struct Node)));
node->num = n; //为node结点赋值
node->next = NULL; //为node结点赋值
struct Node * currentNode; //当前结点的指针
currentNode = &head; //当前结点的指针指向head结点
struct Node * temp; //临时结点的指针
for(int i = 0; i < index - 1; i++) //遍历到index的父节点
{
currentNode = currentNode->next;
}
//这时,currentNode是index的父节点
node->next = currentNode->next;
currentNode->next = node; //更换currentNode的next结点。也就是插入操作
head.num++;//head结点的num表示这个链表一共有几个结点
}
void insertNodeAtFirst(int n) //在头部插入结点
{
insertNodeAt(1, n);
}
void appendNode(int n)//在尾部添加结点
{
int size = head.num;
insertNodeAt(size + 1, n);
}
void removeNode(int index) //删除指定index的结点
{
struct Node * currentNode; //当前结点的指针
struct Node * temp; //结点的临时指针
currentNode = &head; //当前结点的指针指向head结点
for(int i = 0; i < index - 1; i++) //遍历到index的父节点
{
currentNode = currentNode->next;
}
//这时,currentNode是index的父节点
//用temp指向要删除的index结点
temp = currentNode->next;
currentNode->next = currentNode->next->next; //删除index的结点
free(temp); //要回收内存
head.num--; //head结点的num表示这个链表一共有几个结点
}
void removeFirstNode() //删除第一个结点
{
removeNode(1);
}
void removeLastNode() //删除最后一个结点
{
int size = head.num;
removeNode(size);
}
int getNum(int index) //获得指定位置的结点的数据
{
struct Node * currentNode; //当前结点的指针
currentNode = &head; //当前结点的指针指向head结点
//遍历,找到index结点
for(int i = 0; i < index; i++)
{
currentNode = currentNode->next;
if(currentNode == NULL) //防止出错
{
return -1; //出错时返回-1
}
}
return currentNode->num; //返回指定位置的结点的数据
}
int getFirstNum() //获得第一个结点的数据
{
return getNum(1);
}
int getLastNum() //获得最后一个结点的数据
{
int size = head.num;
return getNum(size);
}
void setNum(int index, int n) //设置index位置的结点的数据
{
struct Node * currentNode; //当前结点的指针
currentNode = &head; //当前结点的指针指向head结点
//遍历,找到index结点
for(int i = 0; i < index; i++)
{
currentNode = currentNode->next;
if(currentNode == NULL)
{
return;
}
}
currentNode->num = n; //设置index结点的数据
}
void traverse() //遍历
{
struct Node *currentNode; //当前结点的指针
currentNode = head.next; //当前结点的指针指向head结点的下一个结点
while(currentNode != NULL) //遍历
{
printf("%d, ", currentNode->num); //输出结点信息
currentNode = currentNode->next; //跳转到下一个结点
}
printf("\r\n");
}
void release() //释放内存
{
struct Node * temp; //结点的临时指针
while(head.next != NULL) //当head结点的next不为NULL时循环
{
temp = head.next; //用temp记录head结点的子节点
head.next = head.next->next; //删除head结点的子节点
free(temp); //回收内存
}
}
int main()
{
insertNodeAtFirst(1);
insertNodeAtFirst(2);
insertNodeAtFirst(3);
appendNode(12);
appendNode(13);
appendNode(14);
printf("插入6个结点之后:");
traverse();
removeFirstNode(); //删除第一个结点
printf("\r\n删除第一个结点之后:");
traverse();
removeNode(2);
printf("\r\n删除第二个结点之后:");
traverse();
removeLastNode();
printf("\r\n删除最后一个结点之后:");
traverse();
printf("\r\n得到第一个结点,数据是:%d\r\n", getFirstNum());
printf("\r\n得到第%d个结点,数据是:%d\r\n", 3, getNum(3));
printf("\r\n得到最后一个结点,数据是:%d\r\n", getLastNum());
printf("\r\n在3号位置插入一个结点之后:");
insertNodeAt(3, 8);
traverse();
printf("\r\n把2号位置的结点的数据修改为100:");
setNum(2, 100);
traverse();
release(); //回收内存
printf("\r\nHello\r\n");
return 0;
}
代码运行结果如下:

总体来说,在链表中要找到一个结点是不容易的,时间复杂度为O(N)。虽然链表的添加、删除操作很容易,时间复杂度为O(1),但是两者结合之后却发现,要在链表中先花费O(N)找到一个结点,然后再用O(1)删除/修改/添加一个结点。跟数组相比,似乎并没有什么优势啊。
其实不能完整这么想,用数组最大的问题是没办法修改数组大小,所以只能一开始就申请很大的内存空间来保证程序有足够多的空间。这样势必会浪费很多空间。另外一个问题,数组的内存空间是连续的,这样就必须要先找到一个连续空间才能把这些空间分配给数组。而链表不一样,每次需要一个链表的时候就可以添加一小块内存给程序,而且这些小块的内存不需要连续,这样就可以更好的使用零碎的内存了。另外,对于之后要学习的二叉树、邻接表等内容,就很难绕开链表了。
简单的单向链表就到这里了,链表的形式还有几种,比如循环链表、双向链表、循环双向链表等。这些内容就交给有兴趣的读者自己完成吧。对于本书来说,简单的单向链表就足够用了。
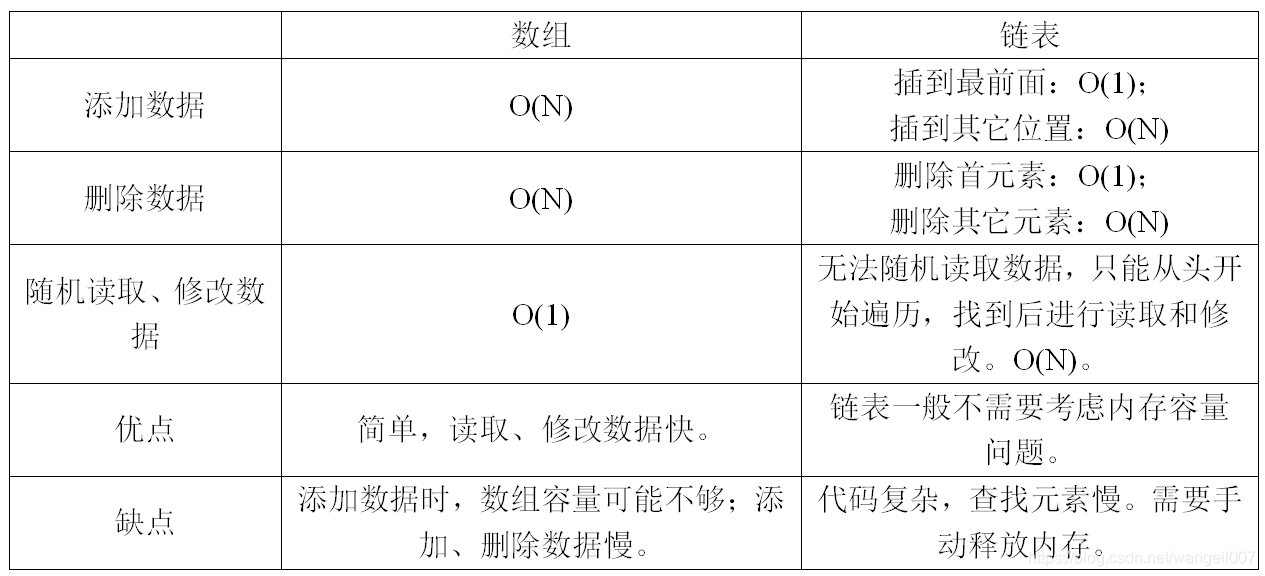
数组和链表的对比如下:
 下一节讲队列。
下一节讲队列。