文章目录
1. 词频统计算法

通过上图可以看出,在执行词频统计算法时,会生成两个阶段(Stage)的MapReduce任务,最后是输出的单词个数,通过输出结果可以看出,从小到大排列输出。
2. 元操作符

Hive编译器将一个HQL转换为操作符,操作符Operator是Hive的最小的处理单元,每个操作符代表HDFS的一个操作或者一道MapReduce作业,所有的Operator都是hive定义的一个处理过程。比如:
SelectOperator:选择输出列
TableScanOperator:扫描hive表数据
LimitOperator:Limit语句
GroupByOperator:GroupBy语句
3. EXPLAIN详解
下面执行:
EXPLAIN SELECT word, count(1) AS count FROM
> (SELECT explode(split(line, ' ')) AS word FROM wordcount) wc
> GROUP BY word
> ORDER BY count;
输出结果:
一个Stage可以是一个MapReduce任务,也可以是一个抽样阶段,或者是一个合并的阶段,还可以是一个limit阶段,以及Hive所需要的其他某个任务的一个阶段。默认情况下,Hive会一次只执行一个stage阶段。
STAGE PLAN 部分比较冗长也比较复杂,stage-1和stage-2包含了这个job的大部分处理过程,而且都会触发一个MapReduce job。
TableScan以这个表(wordcount)作为输入,然后产生一个只有字段col0的输出(outputColumnNames),比如:[“Hello”,”World”,”Bye”,”World”]
UDTF Operator表生成函数,首先执行了explode函数,将数组中的每一个元素单独占用一行输出。
Group By Operator 与count(1)聚合函数联合使用,keys :col,按照列值进行分组,如果不指定,则只有一个分组;mode:hash,是按照hash映射分组。
Reduce Output Operator 输出结果给Reduce,sort order : + 正向排序,如果为 – 则为反向排序; key expressions: 键的表达式,value expressions :值的表达式
Reduce Operator Tree:
mode:mergepartial 合并各个部分聚合的结果,输出为_col0,_col1;File Output Operator 输出中间文件

Map Operator Tree:
Reduce Output Operator: key 是第二列,也就是最后计算的每个单词个数的列,进行正向排序,然后输出到Reduce,这个操作主要就是进行正向排序的,也就是执行ORDER BY语句
Reduce Operator Tree:
expressions:VALUE,KEY 选取要输出的列,又反转了过来,然后outputColumnNames:_col0,_col1进行输出
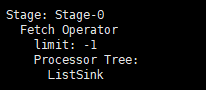
由于这个job没有LIMIT语句,因此Stage-0阶段是一个没有任何操作的阶段,Fetch Operator 客户端获取数据;limit : -1 不限定。