文章目录
QuerySet的方法
相对应的模型数据
from django.db import models
class Student(models.Model):
"""学生表"""
name = models.CharField(max_length=100)
gender = models.SmallIntegerField()
class Meta:
db_table = 'student'
class Course(models.Model):
"""课程表"""
name = models.CharField(max_length=100)
teacher = models.ForeignKey("Teacher", on_delete=models.SET_NULL, null=True)
class Meta:
db_table = 'course'
class Score(models.Model):
"""分数表"""
student = models.ForeignKey("Student", on_delete=models.CASCADE)
course = models.ForeignKey("Course", on_delete=models.CASCADE)
number = models.FloatField()
class Meta:
db_table = 'score'
class Teacher(models.Model):
"""老师表"""
name = models.CharField(max_length=100)
class Meta:
db_table = 'teacher'
相对应的运行SQL文件数据集
数据集下载地址(对应SQL:orm_homework.sql):https://github.com/Senven-J/mysql_data/tree/master
QuerySet API
我们通常做查询操作的时候,都是通过模型名字.objects的方式进行操作。其实模型名字.objects是一个django.db.models.manager.Manager对象,而Manager这个类是一个“空壳”的类,他本身是没有任何的属性和方法的。他的方法全部都是通过Python动态添加的方式,从QuerySet类中拷贝过来的。
def query_set(request):
s = Student.objects
print(s)
# <class 'django.db.models.manager.Manager'>
# objects对应的是一个manager.
# 导入模型之后会发现这个模型中什么也没有写,而是继承了一个类
# 他的方法都是通过动态添加的方式进行绑定
print(type(s))
return HttpResponse('首页')
QuerySet 方法
filter
将满足的条件提取出来
exclude
排除满足条件的数据,返回一个新的QuerySet
def exclude_views(request):
"""exclude : 排除满足条件的数据
filter : 过滤条件中的数据
"""
# Student.objects.exclude('')
# 提取姓名中不含有三的名字
students = Student.objects.exclude(name__contains='三')
# exclude 对应着是SQL语句中的NOT
print(students.query) # SELECT `student`.`id`, `student`.`name`, `student`.`gender` FROM `student` WHERE NOT (`student`.`name` LIKE BINARY %三%)
for student in students:
print(student.name)
# 提取姓名中包含有三的名字
# students = Student.objects.filter(name__contains='三')
# for student in students:
# print(student.pk, student.name)
# print(type(students)) # <class 'django.db.models.query.QuerySet'>
return HttpResponse('exclude')
annotate
给QuerySet中的每个对象都添加一个使用查询表达式(聚合函数、F表达式、Q表达式、Func表达式)
def count_views(request):
for result in results:
print(result.name, result.avg)
print(connection.queries)
return HttpResponse('聚合函数')
order_by
def order_by_views(request):
"""order_by : 按指定的查询顺序排序"""
# 查询表中的数据,让数据从小到大排序
# 传入的是一个字段
# 默认情况下是从小到大的顺序排序,当想从大到小的时候,可以采取在字段前面使用一个负号
# scores = Score.objects.order_by('-number')
# scores = Score.objects.order_by('number')
# 假设一组数据中存在了相同的值的话,可以采取多个字段进行排序
# scores = Grade.objects.order_by('number', '-id')
scores = Score.objects.order_by('student__name')
for score in scores:
print(score.number, score.course.name)
# 打印的一个顺序为这样,当我想采用id的值从大到小的顺序的时候,可以这么做
"""
当为number时 当为number和-id时
1 100 4 100
4 100 1 100
2 101 2 101
3 102 3 102
"""
# for score in scores:
# print(score.id, score.number)
return HttpResponse('order_by')
values
def values_views(request):
"""values : 用来指定在提取数据出来,需要提取哪些字段。默认情况下会把表中所有的字段全部都提取出来
可以使用values来进行指定。
为什么要使用values,因为在使用ORM对数据进行查询的时候,ORM是对每一个字段进行查询
会造成查询的一个效率,所以才会出现了values
"""
stu = Student.objects.values('name')
print(stu)
# print(type(stu)) # <class 'django.db.models.query.QuerySet'>
print(stu.query)
# print(stu.gender)
return HttpResponse('values_views')
values_list
def values_list_views(request):
"""vuales_list:类似于values,但返回的类型为元组类型"""
stu = Student.objects.values_list('name', 'gender')
for s in stu:
print(type(s)) # <class 'tuple'> 返回的类型为元组类型,所以采用元组取值的方式进行取值
print(s)
return HttpResponse('values_list')
update
def update_views(request):
"""update : 更新"""
# 把teacher这个表中的老师好修改成刘老师
# 第一步:先筛选出老师好
# 第二步:在进行更新
tea = Teacher.objects.filter(name='老师好').update(name='刘老师')
print(tea)
print(type(tea))
return HttpResponse('update')
create
def create_views(request):
"""create : 代表着创建一条数据"""
# 之前所学的提交数据的形式。
# t = Teacher(name='Small-J')
# 当创建好数据的时候,我们需要提交数据
# t.save()
# 采用create,采用create的好处就是缩短了代码量,两行的代码缩短成为一行代码
t = Teacher.objects.create(name='老师好')
return HttpResponse('create')
get_or _create
def get_or_create_views(request):
"""get_or_create:根据某个条件进行查询,如果找到了那么就返回数据
如果不存在的,那么就创建数据
"""
# 如果数据存在则返回布尔类型False
# data = Teacher.objects.get_or_create(name='黄老师')
# print(data) # (<Teacher: Teacher object (1)>, False)
# print(type(data)) # <class 'tuple'>
# 如果数据不存在的话,在数据库层面会有对应的数据创建,返回的布尔类型为True
# 这个方法的返回值是一个元组形式,第一个参数为对象,第二个参数为布尔类型
data = Teacher.objects.get_or_create(name='钟老师')
print(data) # (<Teacher: Teacher object (6)>, True)
print(type(data)) # <class 'tuple'>
return HttpResponse('create')
exists
def exists_views(request):
"""exists:判断某个条件的数据是否存在"""
# 当不使用exists的情况的时候,判断数据是否存在
# tea = Teacher.objects.filter(name__contains='黄老师')
# tea = Teacher.objects.filter(name__in=['黄老师'])
# tea = Teacher.objects.filter(name='黄老师')
# tea = Teacher.objects.filter(name='黄老师').count()
# print(tea) # <QuerySet [<Teacher: Teacher object (1)>]>
# print(type(tea)) # <class 'django.db.models.query.QuerySet'>
# if tea:
# print('数据存在')
# 当使用exists的情况,使用exists的时候效率会更高
if Teacher.objects.filter(name='黄老师').exists():
print(True)
# 返回的类型为布尔类型
print(type(Teacher.objects.filter(name='黄老师').exists())) # <class 'bool'>
#
return HttpResponse('exists')
切片操作
def slicer_up(request):
"""切片操作,有时候我们只需要一部分数据"""
# 左闭右开的形式
tea = Teacher.objects.all()[1:3]
# print(tea)
print(tea.query) # SELECT `teacher`.`id`, `teacher`.`name` FROM `teacher` LIMIT 2 OFFSET 1
for t in tea:
print(t.name, t.id)
return HttpResponse('切片操作')
将QuerySet转移为SQL去执行
生成一个QuerySet对象并不会马上转换为SQL语句去执行
from django.db import connection
books = Book.objects.all()
print(connection.queries)
ORM模型练习
ORM模型
from django.db import models
class Student(models.Model):
"""学生表"""
name = models.CharField(max_length=100)
gender = models.SmallIntegerField()
class Meta:
db_table = 'student'
class Course(models.Model):
"""课程表"""
name = models.CharField(max_length=100)
teacher = models.ForeignKey("Teacher", on_delete=models.SET_NULL, null=True)
class Meta:
db_table = 'course'
class Score(models.Model):
"""分数表"""
student = models.ForeignKey("Student", on_delete=models.CASCADE)
course = models.ForeignKey("Course", on_delete=models.CASCADE)
number = models.FloatField()
class Meta:
db_table = 'score'
class Teacher(models.Model):
"""老师表"""
name = models.CharField(max_length=100)
class Meta:
db_table = 'teacher
ORM模型关系图
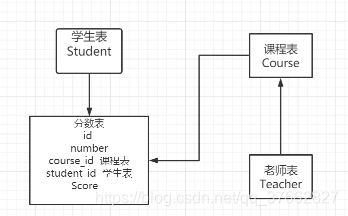
使用之前学到过的操作实现下面的查询操作
有同学的id、姓名、选课的数量、总成绩;
3.查询姓“李”的老师的个数;
4.查询没学过“李老师”课的同学的id、姓名;
5.查询学过课程id为1和2的所有同学的id、姓名;
6.查询课程成绩小于60分的同学的id和姓名;
7.查询没有学全所有课的同学的id、姓名;
8.查询所有学生的姓名、平均分,并且按照平均分从高到低排序;
9.查询各科成绩的最高和最低分,以如下形式显示:课程ID,课程名称,最高分,最低分;
10.统计总共有多少女生,多少男生;
11.将“黄老师”的每一门课程都在原来的基础之上加5分;
12.查询两门以上不及格的同学的id、姓名、以及不及格课程数;
13.查询每门课的选课人数;
from django.shortcuts import render
from django.http import HttpResponse
from .models import Student, Score, Teacher, Course
from django.db.models import Avg, Count, Sum, Q, Max, Min, F
def first_word(request):
# 1.查询平均成绩大于60分的同学的id和平均成绩;
"""
思路分析:
先是使用了annotate对学生进行分组,定义一个字段叫score_avg,在使用Avg聚合函数对关联的分数表进行反向引用
引用该对应定义的分数模型小写模式,通过双下划线取字段在过滤平均成绩大于60分同学,使用values进行过滤取id和平均成绩
{'id': 1, 'score_avg': 83.33333333333333}
{'id': 3, 'score_avg': 91.0}
{'id': 4, 'score_avg': 64.75}
"""
students = Student.objects.annotate(score_avg=Avg('score__number')).filter(score_avg__gt=60).values('id',
'score_avg')
for student in students:
print(student)
return HttpResponse('成功')
def two_word(request):
# 2.查询所有同学的id、姓名、选课的数量、总成绩;
"""
思路分析:
当题目说到查询所有同学的时候,第一时间想到使用的是Studens这个模型,然后通过Count来进行反向引用关联模型中的分数表对应的课程表字段在把相对应的数据赋值给course_count,当谈到总成绩的时候,第一时间想到的是使用Sum聚合函数进行求值并赋值给score_sum在通过values这个QuerySet方法对相对应的字段进行取值
{'id': 1, 'name': '张三', 'course_count': 3, 'score_sum': 250.0}
{'id': 2, 'name': '李四', 'course_count': 4, 'score_sum': 178.0}
{'id': 3, 'name': '王五', 'course_count': 4, 'score_sum': 364.0}
{'id': 4, 'name': '赵六', 'course_count': 4, 'score_sum': 259.0}
"""
students = Student.objects.annotate(course_count=Count('score__course'), score_sum=Sum('score__number')).values(
'id', 'name', 'course_count', 'score_sum')
for student in students:
print(student)
return HttpResponse('成功')
def three_word(request):
# 3.查询姓“李”的老师的个数;
"""
思路分析:查询老师的个数可通过Teacher来进行操作,在通过filter过滤掉相对应的字段
startswith:代表着开头第一个字段的
endswith:代表着筛选最后一个字段的
count:统计个数
1
"""
teacher_number = Teacher.objects.filter(name__startswith='李').count()
print(teacher_number)
return HttpResponse('成功')
def four_word(request):
# 4.查询没学过“李老师”课的同学的id、姓名;
"""
思路分析:查询没有学过李老师课的同学,引用的是Student来进行操作,在通过exclude来进行排除满足条件的数据,
引用score分数表中的关联的course模型中的teacher模型中的name字段来进行取值,在通过values进行筛选字段
{'id': 1, 'name': '张三'}
"""
students = Student.objects.exclude(score__course__teacher__name='李老师').values('id', 'name')
for student in students:
print(student)
return HttpResponse('成功')
def five_word(request):
# 5.查询学过课程id为1和2的所有同学的id、姓名;
"""
思路分析:查询同学使用的为student这个字段,然后使用filter进行过滤,在通过反向引用分数表中的course_id课程表字段,
在通过ORM中的查询操作中的in来筛选出id为1,2。通过values筛选id,name
{'id': 1, 'name': '张三'}
{'id': 1, 'name': '张三'}
{'id': 2, 'name': '李四'}
{'id': 2, 'name': '李四'}
{'id': 3, 'name': '王五'}
{'id': 3, 'name': '王五'}
{'id': 4, 'name': '赵六'}
{'id': 4, 'name': '赵六'}
"""
students = Student.objects.filter(score__course_id__in=[1, 2]).values('id', 'name')
for student in students:
print(student)
return HttpResponse('成功')
def six_word(request):
# 6.查询课程成绩小于60分的同学的id和姓名;
"""
思路分析:查询同学使用的为student这个字段,然后使用filter进行过滤,在通过反向引用分数表中的score__number__lt中小于60的分数,再通过values筛选id,name。
{'id': 2, 'name': '李四'}
{'id': 2, 'name': '李四'}
{'id': 2, 'name': '李四'}
{'id': 4, 'name': '赵六'}
{'id': 4, 'name': '赵六'}
"""
students = Student.objects.filter(score__number__lt=60).values('id', 'name')
for student in students:
print(student)
return HttpResponse('成功')
def seven_word(request):
# 7.查询没有学全所有课的同学的id、姓名;
"""
思路分析:查询学生使用的是Student这个模型,对应的使用annotate这个QuerySet这个方法来进行使用聚合函数Count,这里为什么要使用annotate这个方法呢?因为这个带有数据库层面的group up这个参数,先是通过Count聚合函数来统计出对应学生的学的课程的次数。这里注意:为什么在Count中可以使用filter过滤呢?因为Count实例化参数中有这个方法,在通过过滤把之前定义的num字段做相对应的查询判断,过滤出不符合要求的数据,在通过values进行筛选字段
{'id': 1, 'name': '张三'}
"""
students = Student.objects.annotate(num=Count('score__course')).filter(num__lt=Course.objects.count()).values('id', 'name')
for student in students:
print(student)
return HttpResponse('成功')
def eight_word(request):
# 8.查询所有学生的姓名、平均分,并且按照平均分从高到低排序;
"""
思路分析:查询学生使用Student,通过annotate中的聚合函数Avg方法来求出平均值并赋值给avg,order_by为数值排序,默认情况下从小到大,在前面加上负号代表从大到小,values过滤
{'name': '王五', 'avg': 91.0}
{'name': '张三', 'avg': 83.33333333333333}
{'name': '赵六', 'avg': 64.75}
{'name': '李四', 'avg': 44.5}
"""
students = Student.objects.annotate(avg=Avg('score__number')).order_by('-avg').values('name', 'avg')
for student in students:
print(student)
return HttpResponse('成功')
def night_word(request):
# 9.查询各科成绩的最高和最低分,以如下形式显示:课程ID,课程名称,最高分,最低分;
"""
思路分析:查询形式为id,课程名称,所以想到使用的是Course课程表,通过annotate方法使用聚合函数max,min求最大最小值来进行求相对应的字段
{'id': 1, 'name': 'Python', 'score_max': 104.0, 'score_min': 40.0}
{'id': 2, 'name': '前端', 'score_max': 90.0, 'score_min': 40.0}
{'id': 3, 'name': 'Java', 'score_max': 94.0, 'score_min': 62.0}
{'id': 4, 'name': '安卓', 'score_max': 90.0, 'score_min': 34.0}
"""
students = Course.objects.annotate(score_max=Max('score__number'), score_min=Min('score__number')).values('id', 'name', 'score_max', 'score_min')
for student in students:
print(student)
return HttpResponse('成功')
def ten_word(request):
# 10.统计总共有多少女生,多少男生;
"""
思路分析:使用filter过滤进行统计男生女生统计
男孩 2, 女孩 2
"""
boy = Student.objects.filter(gender=1).count()
girl = Student.objects.filter(gender=2).count()
print('男孩 %s, 女孩 %s' % (boy, girl))
return HttpResponse('成功')
def eleven_word(request):
# 11.将“黄老师”的每一门课程都在原来的基础之上加5分;
"""
思路分析:使用filter筛选黄老师的,在通过update进行更新F表达式进行加分选项
"""
result = Score.objects.filter(course__teacher__name='黄老师').update(number=F('number')+5)
return HttpResponse('成功')
def twelve_word(request):
# 12.查询两门以上不及格的同学的id、姓名、以及不及格课程数;
"""
思路分析: 题目中需要使用到分组就需要使用到annotate这个方法,在通过Count这个方法进行求课程的数量,在通过filter进行筛选出相对应的在进行values
{'id': 2, 'name': '李四', 'score_fail': 3}
"""
students = Student.objects.annotate(score_fail=Count('score__number', filter=Q(score__number__lt=60))).filter(score_fail__gt=2).values('id', 'name', 'score_fail')
for student in students:
print(student)
return HttpResponse('成功')
def thirteen_word(request):
# 13.查询每门课的选课人数;
"""
思路分析:通过annotate进行分组,通过聚合函数Count来进行求次数,通过反向引用score来获取相对应的学生表
Python 4
前端 4
Java 4
安卓 3
"""
nums = Course.objects.annotate(course_num=Count('score__student'))
for num in nums:
print(num.name, num.course_num)
return HttpResponse('成功')
urls.py
# @Time : 2020/7/7 21:42
# @Author : Small-J
from django.urls import path
from .import views
urlpatterns = [
path('', views.first_word),
path('two/', views.two_word),
path('three/', views.three_word),
path('four/', views.four_word),
path('five/', views.five_word),
path('six/', views.six_word),
path('senven/', views.seven_word),
path('eight/', views.eight_word),
path('night/', views.night_word),
path('ten/', views.ten_word),
path('eleven/', views.eleven_word),
path('twelve/', views.twelve_word),
path('thirteen/', views.thirteen_word)
]
ORM迁移模型
迁移命令
-
makemigrations: 将模型生成迁移脚本。模型所在的app,必须放在settings.py中的INSTALLED_APPS。这个命令有以下几个常用选项:-
app_label: 后面可以跟一个或者多个app,那么就只会针对这几个app生成迁移脚本。如果没有任何的app_lable,那么会检查INSTALLED_APPS中所有的app下的模型,针对每一个app生成响应的迁移脚本。-
# 只会迁移front这个app python manage.py makemigrations front
-
-
--name: 给这个迁移脚本指定一个名字-
# 给对应的迁移脚本自定义名字,注意名字没有.py python manage.py makemigrations --name remove_a_b_demo python manage.py makemigrations front --name remove_a_b_demo
-
-
--empty:生成一个空的迁移脚本。如果你想要写自己的迁移脚本,可以使用这个命令来实现一个空的文件,自己写迁移脚本文件。-
# 指定front这个app生成一个空的迁移脚本 python manage.py makemigrations front --empty
-
-
-
migrate: 将新生成的迁移脚本。映射到数据库中。创建新的表或者修改表的结构。以下一些常用的选项:-
app_lable: 将某个app下的迁移脚本映射到数据库中,如果没有指定,那么会将所有在INSTALLED_APPS中的app下的模型都映射到数据库中。-
# 指定某app生成迁移脚本 python manage.py migrate front
-
-
app_label migrationname: 将某个app下指定名字的migration文件映射到数据库中-
# 指定生成front这个app的对应0003之前的迁移脚本文件 python manage.py migrate front 0003_article_title
-
-
--fake: 可以将指定的迁移脚本名字添加到数据库中。但是并不会把迁移脚本转换为SQL语句,修改数据库中的表 -
--fake-initial: 将第一次生成的迁移文件版本号记录在数据库中。但并不会真正的执行迁移脚本。
-
-
showmigrations: 查看某个app下的迁移文件。但是后面没有app,那么将查看INSTALLED_APPS中所有的迁移文件python manage.py showmigtations [app名字] -
sqlmigrate: 查看某个迁移文件在映射到数据库中的时候,转换的SQL语句python manage.py sqlmigrate article 0001_inital
migration中迁移版本和数据库中的迁移版本对不上怎么办?
- 找到哪里不一致,然后使用
python manage.py --fake [版本名字],将这个版本标记为已经映射。 - 删除指定app下
migrations和数据库表django_migrations中和这个app相关的版本号,然后将模型中字段和数据库中的字段保持一致,再使用命令python manage.py makemigrations重新生成一个初始化的迁移脚本,之后再使用命令python manage.py migrate --fake-inital来将这个初始化的迁移脚本标记为已经映射。再修改就没有问题了。
根据已有的表自动生成模型
数据集下载地址 (对应SQL:old_db_demo.sql):https://github.com/Senven-J/mysql_data/tree/master
在实际开发中,有些时候可能数据库已经存在了。如果我们用Django来开发一个网站,读取的是之前已经存在的数据库中的数据,那么该如何将模型与数据库中的表映射呢?根据旧的数据库生成对应的ORM模型,需要以下几个步骤:
Django给我们提供了一个**inspectdb的命令,可以非常方便的将已经存在的表,自动的生成模型。想要使用inspectdb**自动将表生成模型。首先需要在settings.py中配置好数据库相关信息。不然就找不到数据库。
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'table_orm_demo',
'USER': 'root',
'PASSWORD': 'root',
'HOST': '127.0.0.1',
'PORT': 3306
}
}
执行命令python manage.py inspectdb
# This is an auto-generated Django model module.
# You'll have to do the following manually to clean this up:
# * Rearrange models' order
# * Make sure each model has one field with primary_key=True
# * Make sure each ForeignKey has `on_delete` set to the desired behavior.
# * Remove `managed = False` lines if you wish to allow Django to create, modify, and delete the table
# Feel free to rename the models, but don't rename db_table values or field names.
from django.db import models
class Article(models.Model):
title = models.CharField(max_length=100, blank=True, null=True)
content = models.TextField(blank=True, null=True)
author = models.ForeignKey('User', models.DO_NOTHING, blank=True, null=True)
class Meta:
managed = False
db_table = 'article'
class ArticleTag(models.Model):
article = models.ForeignKey(Article, models.DO_NOTHING, primary_key=True)
tag = models.ForeignKey('Tag', models.DO_NOTHING)
class Meta:
managed = False
db_table = 'article_tag'
unique_together = (('article', 'tag'),)
class Tag(models.Model):
name = models.CharField(max_length=100, blank=True, null=True)
class Meta:
managed = False
db_table = 'tag'
class User(models.Model):
username = models.CharField(max_length=100, blank=True, null=True)
password = models.CharField(max_length=100, blank=True, null=True)
class Meta:
managed = False
db_table = 'user'
将模型进行重定向到model.py — python manage.py inspectdb > front/models.py
修正模型
为什么要修正模型?----》新生成的ORM模型有些地方可能不太适合使用。比如模型的名字,表之间的关系等等
- 模型名:自动生成的模型,是根据表的名字生成的,可能不是你想要的。这时候模型的名字你可以改成任何你想要的。
- 模型所属app:根据自己的需要,将相应的模型放在对应的app中。放在同一个app中也是没有任何问题的。只是不方便管理。
- 模型外键引用:将所有使用ForeignKey的地方,模型引用都改成字符串。这样不会产生模型顺序的问题。另外,如果引用的模型已经移动到其他的app中了,那么还要加上这个app的前缀。
- 让Django管理模型:将Meta下的managed=False删掉,如果保留这个,那么以后这个模型有任何的修改,使用migrate都不会映射到数据库中。
- 当有多对多的时候,应该也要修正模型。将中间表注视了,然后使用ManyToManyField来实现多对多。并且,使用ManyToManyField生成的中间表的名字可能和数据库中那个中间表的名字不一致,这时候肯定就不能正常连接了。那么可以通过db_table来指定中间表的名字。
front/models.py
from django.db import models
class User(models.Model):
username = models.CharField(max_length=100, blank=True, null=True)
password = models.CharField(max_length=100, blank=True, null=True)
class Meta:
db_table = 'user'
article/models.py
from django.db import models
class Article(models.Model):
title = models.CharField(max_length=100, blank=True, null=True)
content = models.TextField(blank=True, null=True)
# 对应frontapp的user模型
author = models.ForeignKey('front.User', models.DO_NOTHING, blank=True, null=True)
# ManyToManyField 多对多关系
# to-->指定哪一个表
# db_table ->指定那个表名
tage = models.ManyToManyField('Tag', db_table='article_tag')
class Meta:
db_table = 'article'
# class ArticleTag(models.Model):
# article = models.ForeignKey(Article, models.DO_NOTHING, primary_key=True)
# tag = models.ForeignKey('Tag', models.DO_NOTHING)
#
# class Meta:
# db_table = 'article_tag'
# unique_together = (('article', 'tag'),)
class Tag(models.Model):
name = models.CharField(max_length=100, blank=True, null=True)
class Meta:
db_table = 'tag'
- 执行命令
python manage.py makemigrations生成初始化的迁移脚本。 - 方便后面通过ORM来管理表。这时候还需要执行命令
python manage.dpy migrate --fake-initial,使用--fake-initial会重新的生成一个迁移脚本文件。因为如果不使用–fake-initial,那么会将迁移脚本会映射到数据库中。 - 这时候迁移脚本会新创建表,而这个表之前是已经存在了的,所以肯定会报错。
- 此时我们只要将这个0001-initial的状态修改为已经映射,而不真正执行映射,下次再migrate的时候,就会忽略他。