通常情况下,我们一般都会使用交叉验证来作为评估模型的标准,来选择我们最后的模型。但是在一些数据挖掘竞赛中,数据集一般分为训练集合测试集,国内比赛可能根据比赛阶段划分多个测试集,由于数据集采样和分布的原因导致训练集和线上测试集可能存在分布不一致的情况,这时候CV无法准确的评估模型在测试集上的效果,导致线上线下不统一,分数上不去。而缓解这一问题的黑科技,就是对抗验证Adversarial validation。(图片来自 Coggle数据科学公众号,见致谢。)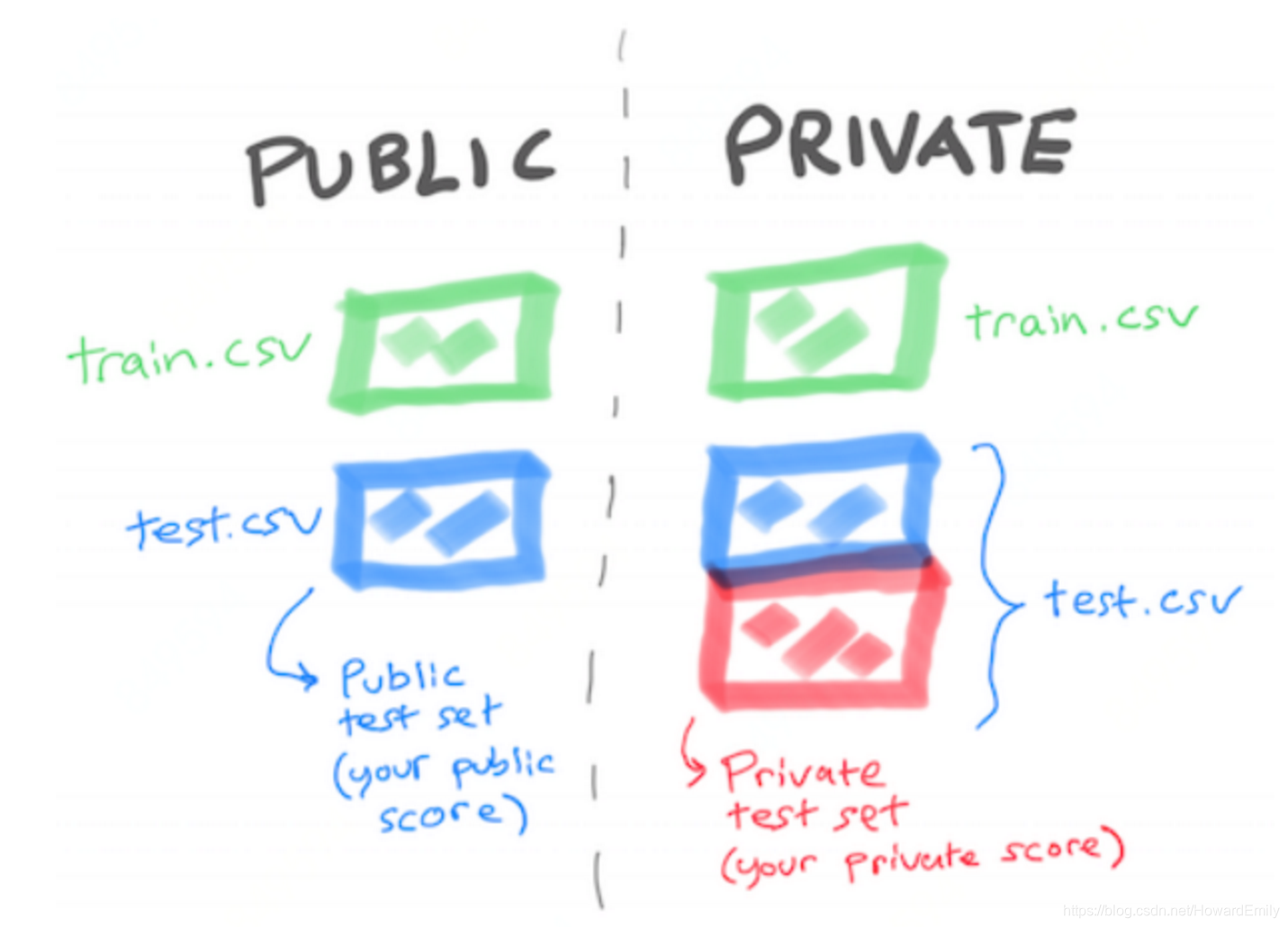
样本分布的变化
样本分布变化主要体现在训练集和测试集的数据分布存在差异。比如,在化妆品或者医美市场,男性的比例越来越多。基于过去的数据构建的模型,渐渐不适用于现在。
此时为什么交叉验证不适用?
比如我们现在要对淘宝用户的购买行为进行推荐或者预测。
我们的训练数据集中用户的年龄分布大概在18~25岁,而我们的测试集中主要是70岁以上的老人组成。这时我们的数据样本分布就发生了变化。(图片来自知乎刘秋言)
这时候使用交叉验证就无法准确评估模型的效果。因为交叉验证时每一