写在开头:今天主要写一下MapReduce在日志流量统计方面的实践,数据结构比较简单,主要是一个使用思路。
学习内容安排
今天我们将对用户使用流量数据进行分析,同样按照上一节的MapReduce计算流程来编写代码。在进行代码编写前我们首先来看一下数据的样子,以下数据均为虚构的,
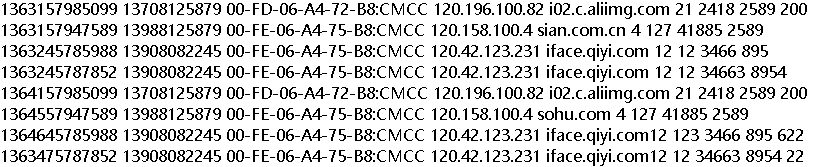
在上面的数据中可以看到第一列不太清楚是啥,第二列是手机号,第三四五列是访问的信息方面,后面的倒数第三与导数第二的数据就是本文今天最关注的上行流量与下行流量。今天的任务就是分别展示上下行流量并计算总流量。
MapReduce之流量统计
这个问题与昨天的问题有一个不同之处在于,词频统计在Map输出是以键值对的形式输出,<text,次数>,而在此处需要的不是次数,而是对应值相加,而且一个Key对应的上下行流量两个值,也就是在键值对中需要储存电话号码、上行流量、下行流量三个值,这个就是今天的重点。为了解决这个问题需要重新构造一个对象来储存上下行流量,代码如下,
定义流量类FlowBean
package FlowSum;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class FlowBean implements Writable{
String mobile;
long up;
long down;
long sum;
public FlowBean(){}
public FlowBean(String mobile, long up, long down) {
this.mobile = mobile;
this.up = up;
this.down = down;
this.sum = up + down;
}
public String getMobile() {
return mobile;
}
public void setMobile(String mobile) {
this.mobile = mobile;
}
public long getUp() {
return up;
}
public void setUp(long up) {
this.up = up;
}
public long getDown() {
return down;
}
public void setDown(long down) {
this.down = down;
}
public long getSum() {
return sum;
}
public void setSum(long sum) {
this.sum = sum;
}
public String toString(){
return " " + up + ":" +down + ":" +sum;
}
@Override
public void write(DataOutput out) throws IOException {
//hadoop字符可以传递,对象需要实现序列化和反序列化这样才能读和写
out.writeUTF(mobile);
out.writeLong(up);
out.writeLong(down);
out.writeLong(sum);
}
@Override
public void readFields(DataInput in) throws IOException {
//序列化
mobile = in.readUTF();
up = in.readLong();
down = in.readLong();
sum = in.readLong();
}
}
在代码最下端实现的两个类表示的是将数据进行序列化与反序列化,这样才能进行读写操作,至于为什么要序列化与反序列化,可以点击查看这篇文章的解释,序列化与反序列化。FlowBean类用于定义键值对中值的类型。
Map函数编写
那在本文中我们不直接从本地上传到HDFS文件,而是先用SecureFX将本地文件上传到Linux里,然后通过copyFromLocal类似语句将Linux文件上传到HDFS里,对于编写Map仍然是按行读取数据,输出的时候就是电话号码,加上刚刚定义的FlowBean函数,
package FlowSum;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class FlowMapper extends Mapper<LongWritable, Text, Text, FlowBean>{
//序列号,1行,输出电话号码,输出携带很多值的对象
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split(" ");
String mobile = fields[1];
long up = Long.parseLong(fields[6]);
long down = Long.parseLong(fields[7]);
context.write(new Text(mobile), new FlowBean(mobile, up, down));
}
}
Reduce函数编写
在Reduce函数里就需要将传回来的FlowBean类中的上下行流量进行加和计算,
package FlowSum;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class FlowReducer extends Reducer<Text, FlowBean, Text, FlowBean>{
//传过来的是什么,再要传出去的两个键值对是什么
@Override
//框架传递过来的是一组数据<13808124758, {FlowBean,FlowBean....}>;就调用一次reduce(),根据需求遍历Bean,进行累加求和。
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
long up_sum = 0;
long down_sum = 0;
for (FlowBean value : values) {
up_sum = up_sum + value.getUp();
down_sum = down_sum + value.getDown();
}
context.write(key, new FlowBean(key.toString(), up_sum, down_sum));
}
}
作业函数编辑
最后通过作业的调度,完成计算并进行输出,与上一节相似,这里的flowoutput一定要先确认是否存在,如果存在就要把这个文件删除,因为这个文件是软件运行自动生成的,要把之前的删掉。
package FlowSum;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.log4j.BasicConfigurator;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FlowRunner {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
BasicConfigurator.configure();
Configuration con = new Configuration();
Job job = Job.getInstance(con);
job.setJarByClass(FlowRunner.class);
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://192.168.0.23:9000/user/root/flowinput"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.0.23:9000/user/root/flowoutput"));
job.waitForCompletion(true);
}
}
结果展示
可以看到各个用户在浏览上的上下行和总流量
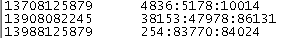 *****
*****
结语
这两天都主要展示的是一些简单的MapReduce的应用,但可能考虑到后面使用的并不是很多,具体的更新结合情况再说吧,后面可能还是主要在数据科学实战和机器学习上。
谢谢阅读
参考
1.序列化与反序列化