Paper Reading Note
URL:
https://cg.cs.tsinghua.edu.cn/papers/CVPR-2019-Drawing.pdf
TL;DR
CVPR2019一篇来自清华大学的文章,主要设计了一种GAN的结构APDrawingGAN,实现了利用GAN做人脸肖像画生成。
Motivation
肖像画不同于一般的轮廓,在保证人脸各部位特征的同时还需要具备一定的抽象美:
从左向右为原图 NPR模型 NPR加上下巴轮廓引导 APDrawingGAN
而SOTA的GAN方法在做这个任务时要么就会改变人脸部特征(1-4),要么会犯错(5-6):
Algorithm
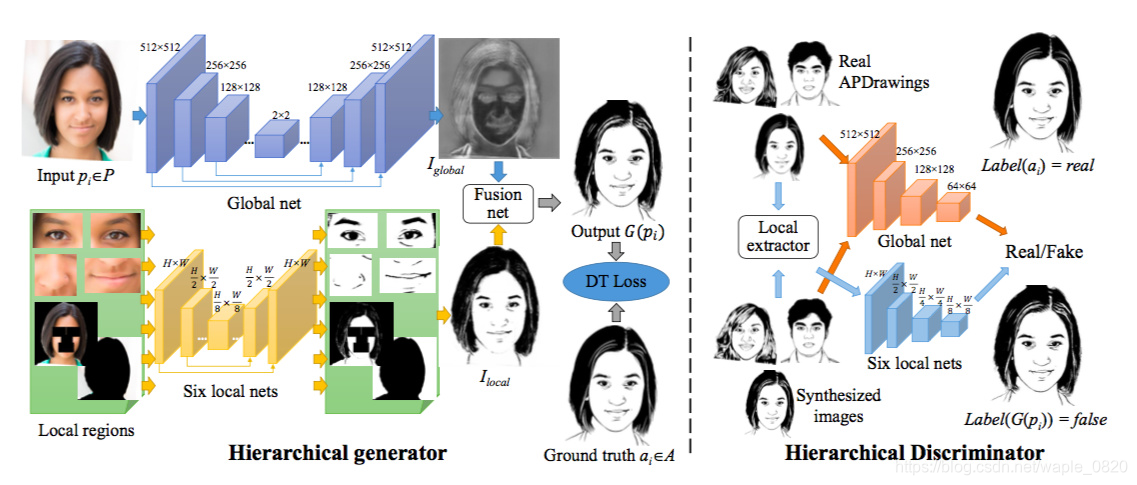
Generator部分
Generator采用的结构是global net+local net。global部分用的是一个8层*2的U-Net结构,用于提取图片的全局特征。local部分将左眼等六个local属性单独提取出来,用了3层*2和4层*2的U-Net,这里对每一个local feature都添加了一个L1的loss: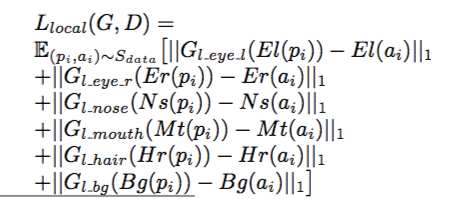
提取之后通过一个fusion net将二者结合,得到fake image。
计算这里的损失是本文的一个亮点。由于与以往的任务不同,本文的任务目标是黑色线条构成,因此如果计算pixel-wise的loss会有较大的误差。这里作者用了一个DT Loss: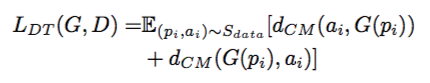
其中用于表示两张图的distance的函数: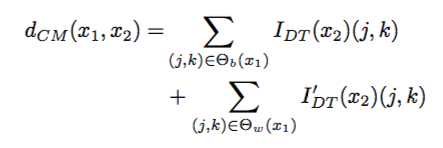
这里定义的意思就是对于每个pixel,去找离他最近的原图中pixel,计算之间的的距离。
Discriminator部分
与Gen部分类似,也分成了global和local部分,最后将两部分结合求一个true/fake损失。
Dataset
由于这个模型是需要pairs作为ground truth,且为了保证分布的一致性,作者雇佣了一个专业的画师画了140张图作为训练集(这里真的够吗?)。由于不需要label标签,作者在各个论文数据集中选取了6655张清晰人脸图像作为测试集。
Results
作者修改模型各部分参数的结果: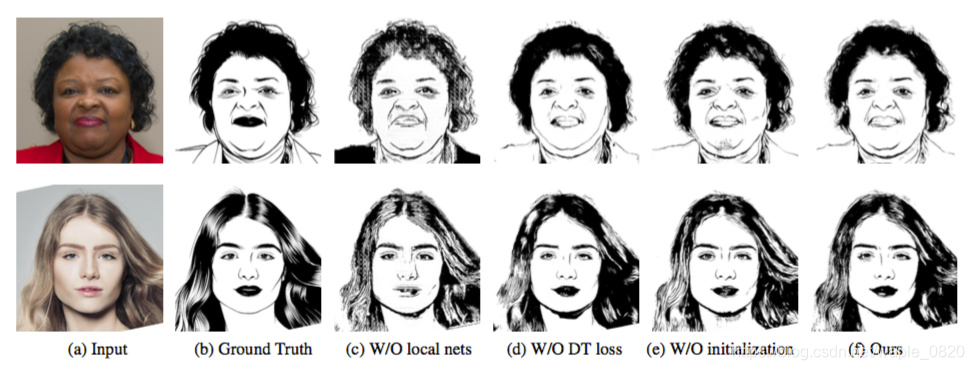
与SOTA方法对比: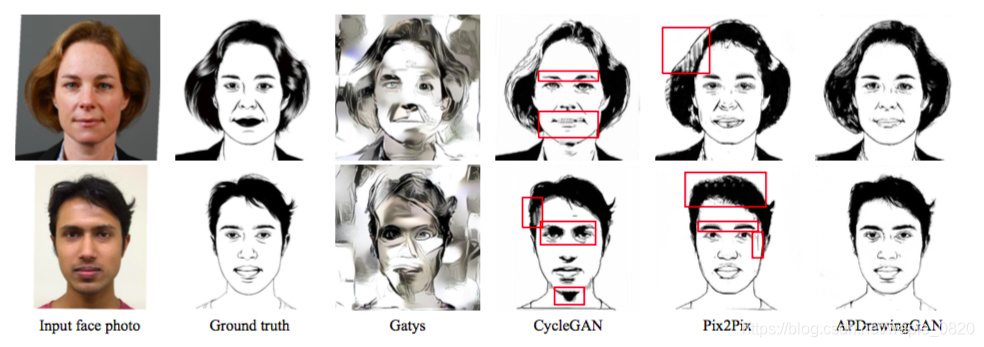
当然,目前没有SOTA的研究是针对这个任务的,所以这个对比的说服性不够,不过直观上看起来确实效果还可以。
Thoughts
本篇论文一个亮点在于提出了global和feature结合的Generator,能够看出在把握细节特征上也做的很出色。另一个亮点在于提出了针对于该任务的DT Loss,在线条构成的图上更适用。
Demo
作者做了一个小程序demo可以看效果。

