文章目录
一、自增自减运算符
面试题:
public class Test01 {
public static void main(String[] args) {
int i = 1;
i = i++;
int j = i++;
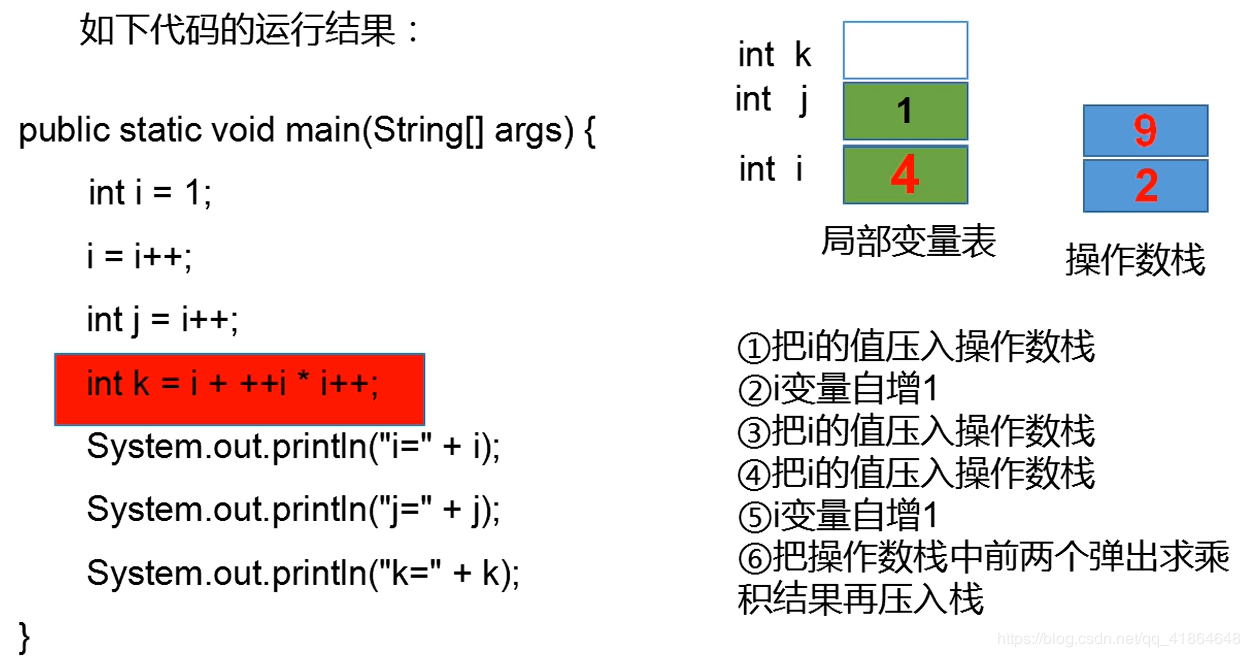
int k = i + ++i * i++;
System.out.println(i);// 4
System.out.println(j);// 1
System.out.println(k);// 11
}
}
1.1 基础自增举例
//再看一个基础得例子
int i = 1;
i = i++;
//这里变量i还是等于1的
int j = i++;
System.out.println(i);// 2
System.out.println(j);// 1
参考博文 https://blog.csdn.net/qq_37937537/article/details/79931157
涉及到操作数栈与局部变量值的区别
粗略理解:
首先看 i= i++; 的操作
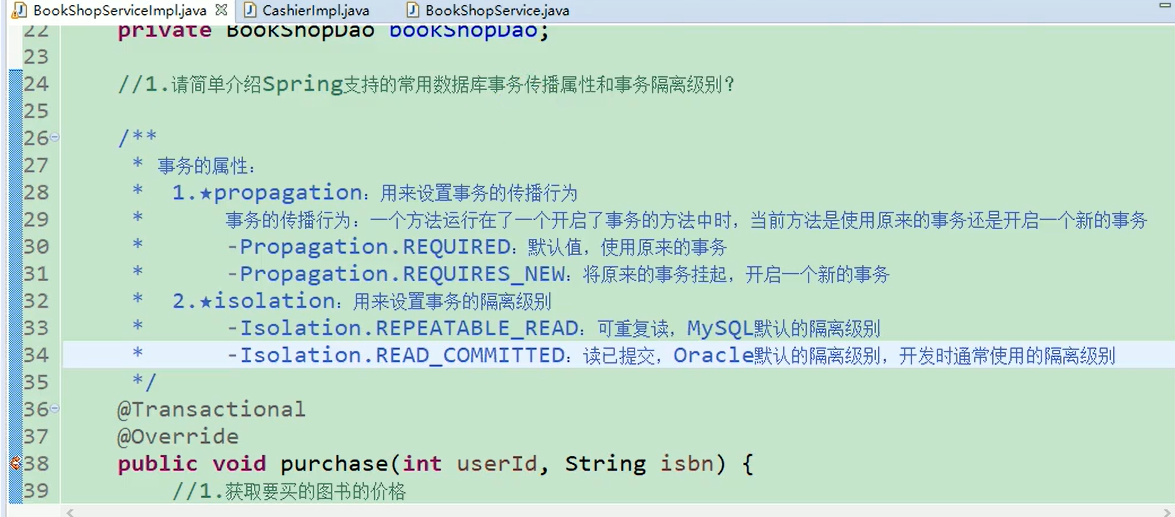
要清楚这个语句的步骤,第一步是先算右边的 i++ ,第二步将右边的结果赋值给变量 i
那么 i ++ 的结果大家都知道,还是 1 。
那么这个结果赋值给变量 i ,i 仍然 等于 1 .
原理详解:
明确一个知识点:自增运算是在局部变量表中进行,赋值语句是将操作数栈的结果取出。
为什么 i++ 叫做“先赋值后运算”?
(1)i ++ 时,先将 i 的值压入操作数栈。
(2)随后 i 进行自增操作,局部变量表中值自增为 2
(3)最后执行赋值操作,将操作数栈 中的结果,赋值给变量 i,仍然是 1扫描二维码关注公众号,回复: 11492894 查看本文章
字节码逐条分析:
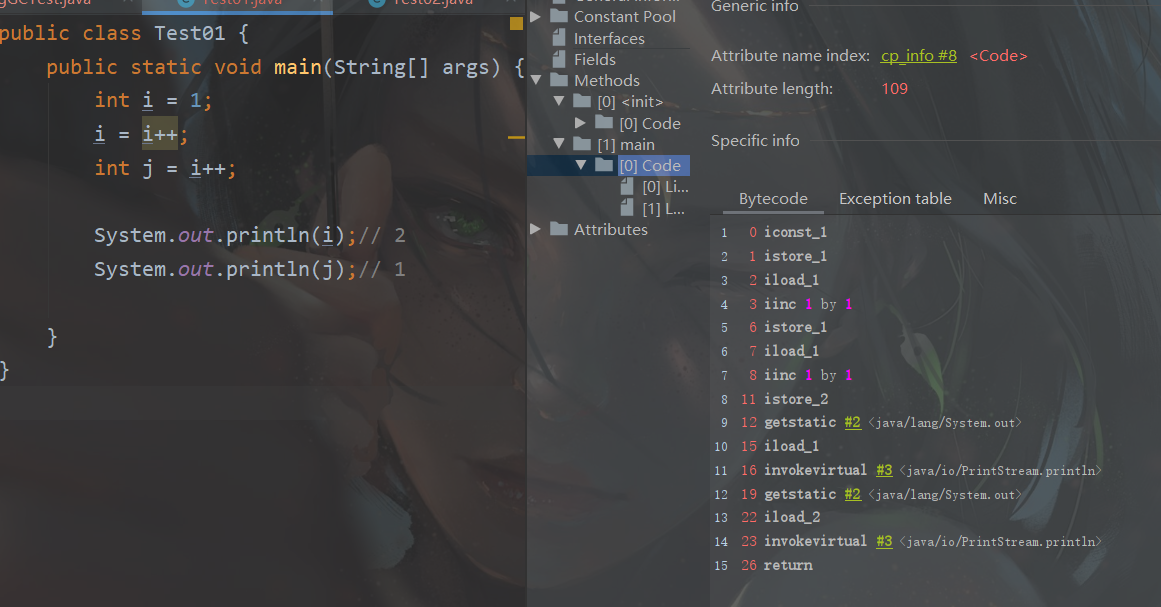
0 iconst_1 //常量值1
1 istore_1 //将常量值1存储到局部变量表--变量1
2 iload_1 //取变量1到操作数栈
3 iinc 1 by 1 //自增,在局部变量表
6 istore_1 //操作完毕,将操作数栈的栈顶值取出,赋给局部变量表对应变量。也就是将值1又赋给变量1
7 iload_1 //加载变量1到操作数栈
8 iinc 1 by 1 //局部变量自增 i变2
11 istore_2 //操作完毕,操作数栈顶值1赋给变量j(变量2),所以变量j值为1
12 getstatic #2 <java/lang/System.out>
15 iload_1
16 invokevirtual #3 <java/io/PrintStream.println>
19 getstatic #2 <java/lang/System.out>
22 iload_2
23 invokevirtual #3 <java/io/PrintStream.println>
26 return
1.2 面试题举例

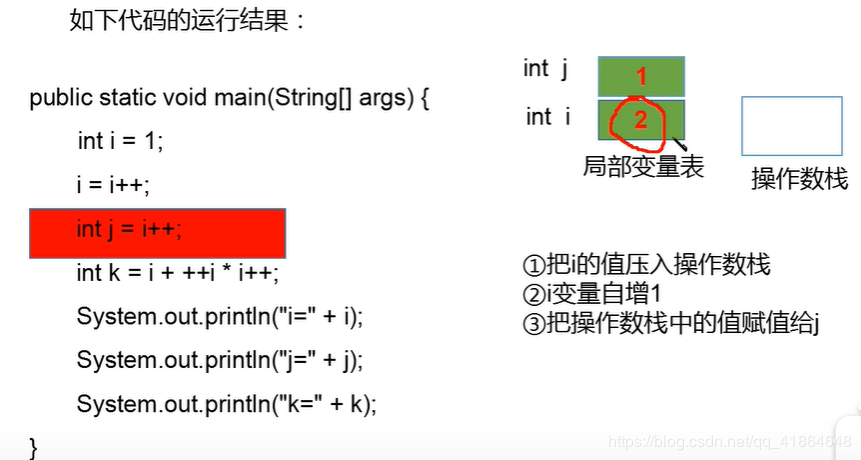
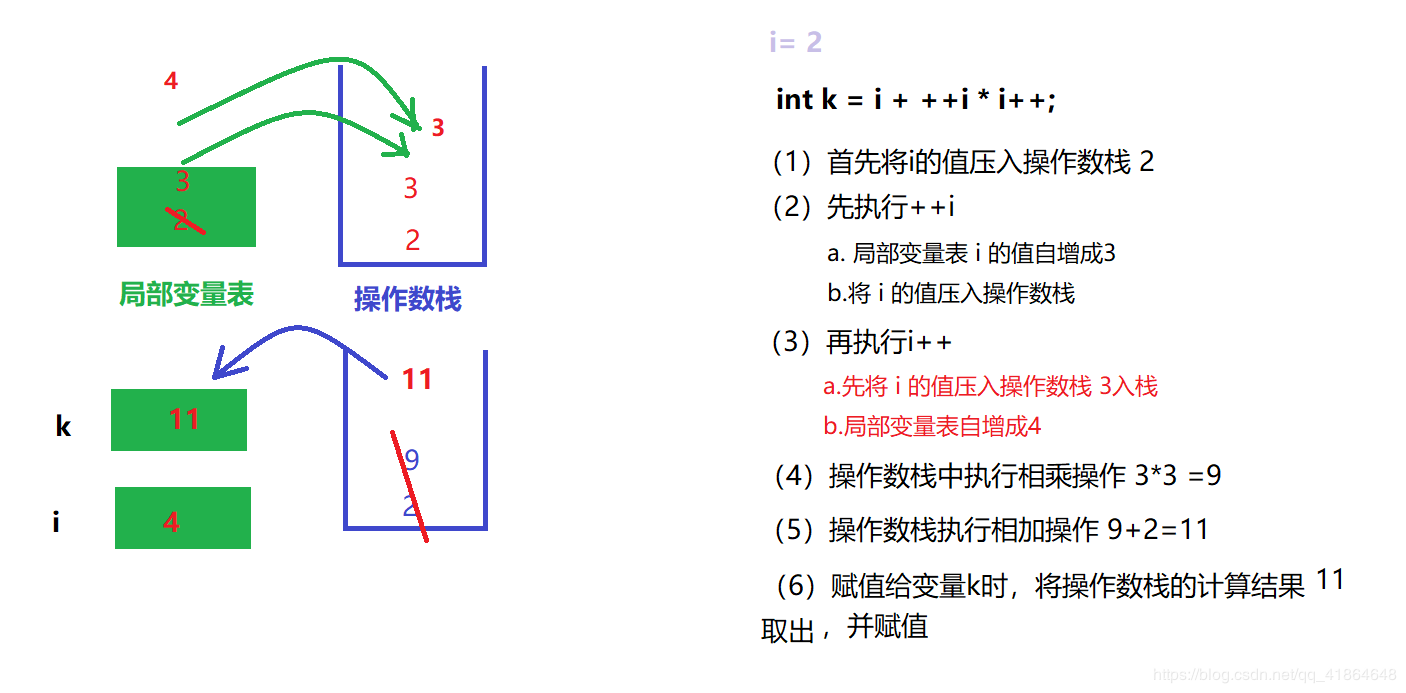
对于K的求值,这里说一下我的粗暴理解
i ++ 是先将操作数压入操作数栈当中,然后局部变量表自增,最后从操作数栈取出赋值给变量 i。
++ i 是先在局部变量表 i 自增,再将 i 的值压入操作数栈,最后执行赋值操作取操作数栈的值赋值给变量 i。
所以对比发现这个区别就是 将 i 的值压入操作数栈 和 局部变量中自增 的顺序,决定了这两个东西最后结果的差异。你明白他俩到底哪里不一样才会出现不同结果了吗?
下面看一个我瞎画得图解:


柴林燕老师得PPT讲解:
字节码分析
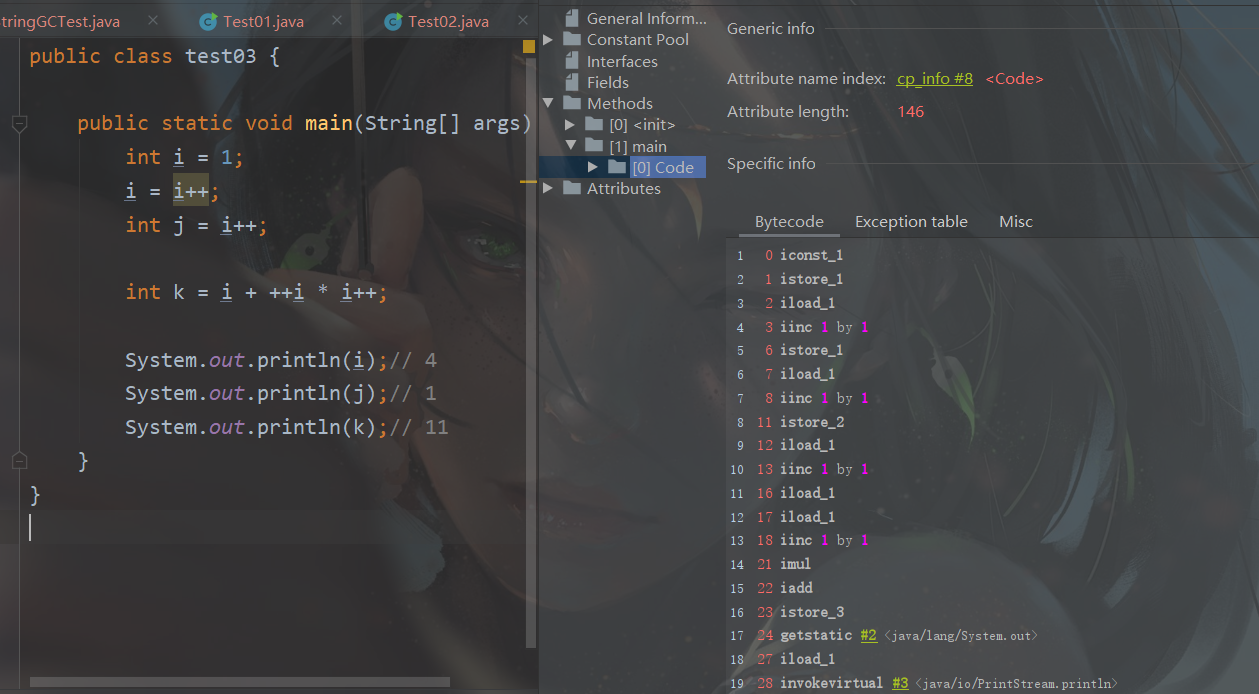
0 iconst_1
1 istore_1
2 iload_1
3 iinc 1 by 1
6 istore_1
7 iload_1
8 iinc 1 by 1
11 istore_2
12 iload_1
13 iinc 1 by 1
16 iload_1
17 iload_1
18 iinc 1 by 1
21 imul
22 iadd
23 istore_3
24 getstatic #2 <java/lang/System.out>
27 iload_1
28 invokevirtual #3 <java/io/PrintStream.println>
31 getstatic #2 <java/lang/System.out>
34 iload_2
35 invokevirtual #3 <java/io/PrintStream.println>
38 getstatic #2 <java/lang/System.out>
41 iload_3
42 invokevirtual #3 <java/io/PrintStream.println>
45 return
二、单例设计模式
2.1 概念
单例设计模式,即某个类在整个系统中只能有一个实例对象可被获取和使用的代码模式。
例如:代表JVM运行环境的Runtime类
Singleton:在Java中即指单例设计模式,它是软件开发中最常用的设计模式之一。
单例:唯一实例
要点:单例设计模式的要求
- 一是某个类只能有一个实例;
- 构造器私有化
- 二是它必须自行创建这个实例;
- 含有一个该类的静态变量来保存这个唯一的实例
- 三是它必须自行向整个系统提供这个实例;
- 对外提供获取该实例对象的方式:
(1)直接暴露(2)用静态变量的get方法获取
- 对外提供获取该实例对象的方式:
几种常见形式:
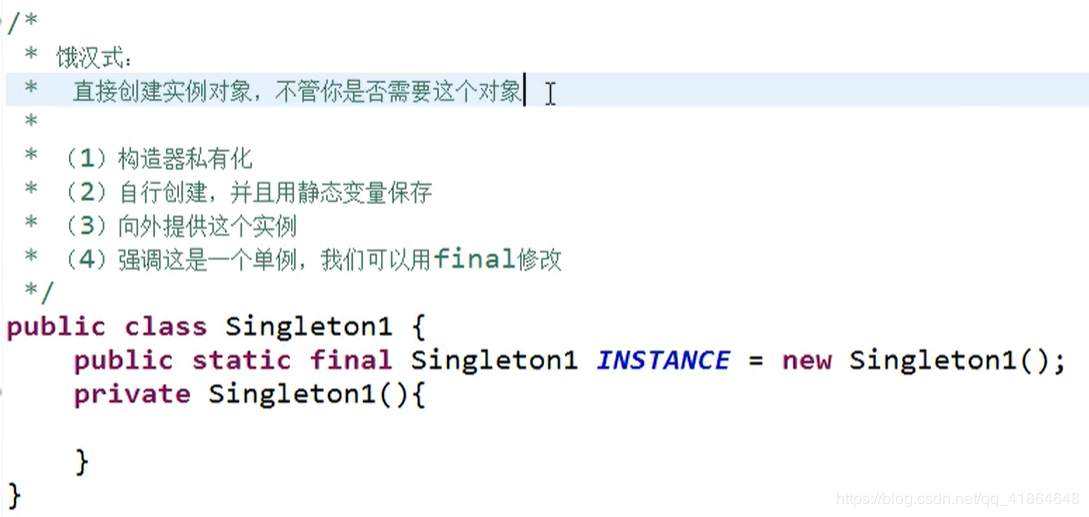
- 饿汉式:类初始化时直接创建对象,不存在线程安全问题
- 直接实例化饿汉式(简洁直观)
- 枚举式(最简洁)
- 静态代码块饿汉式(适合复杂实例化)
- 懒汉式:延迟创建对象
- 线程不安全(适用于单线程)
- 线程安全(适用于多线程)
- 静态内部类形式(适用于多线程)
ps. 饿汉式:特点就是在类初始化的时候就直接new出实例了,不管你后期需不需要。这样创建的单例对象,会随着类的加载而创建,随着类的回收而销毁。基本和应用程序的声明周期一样长。
2.2 饿汉式方式一:静态变量中初始化
2.3 饿汉式方式二:枚举类型
 ### 2.4 饿汉式方式三:静态代码块中实例化
### 2.4 饿汉式方式三:静态代码块中实例化
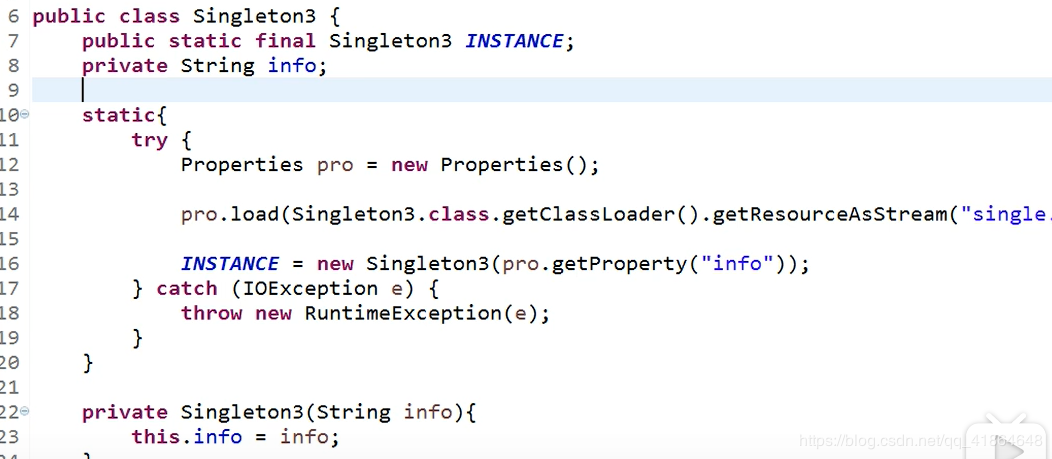
再补充加深一下印象:
饿汉式单例在类加载初始化时就创建好一个静态的对象供外部使用,除非系统重启,这个对象不会改变,所以本身就是线程安全的。
Singleton通过将构造方法限定为private避免了类在外部被实例化,在同一个虚拟机范围内,Singleton的唯一实例只能通过getInstance()方法访问。
(事实上,通过Java反射机制是能够实例化构造方法为private的类的,那基本上会使所有的Java单例实现失效。反射会破坏封装性,此问题在此处不做讨论,姑且闭着眼就认为反射机制不存在。)
// 饿汉式单例 public class Singleton1 { // 私有构造 private Singleton1() {} private static Singleton1 single = new Singleton1(); // 静态工厂方法 public static Singleton1 getInstance() { return single; } }
懒汉式:不会立马初始化,类需要向外面提供一个可以获取实例的方法(暴露自己),让外部决定什么时候初始化
2.5 懒加载方式一: 简单提供一个get方法将实例提供出去

// 懒汉式单例
public class Singleton2 {
// 私有构造
private Singleton2() {}
private static Singleton2 single = null;
public static Singleton2 getInstance() {
if(single == null){
single = new Singleton2();
}
return single;
}
}
问题:出现线程安全问题,下面的代码可能会new 出两个不同的实例,就打破了单例模式的设计理念。
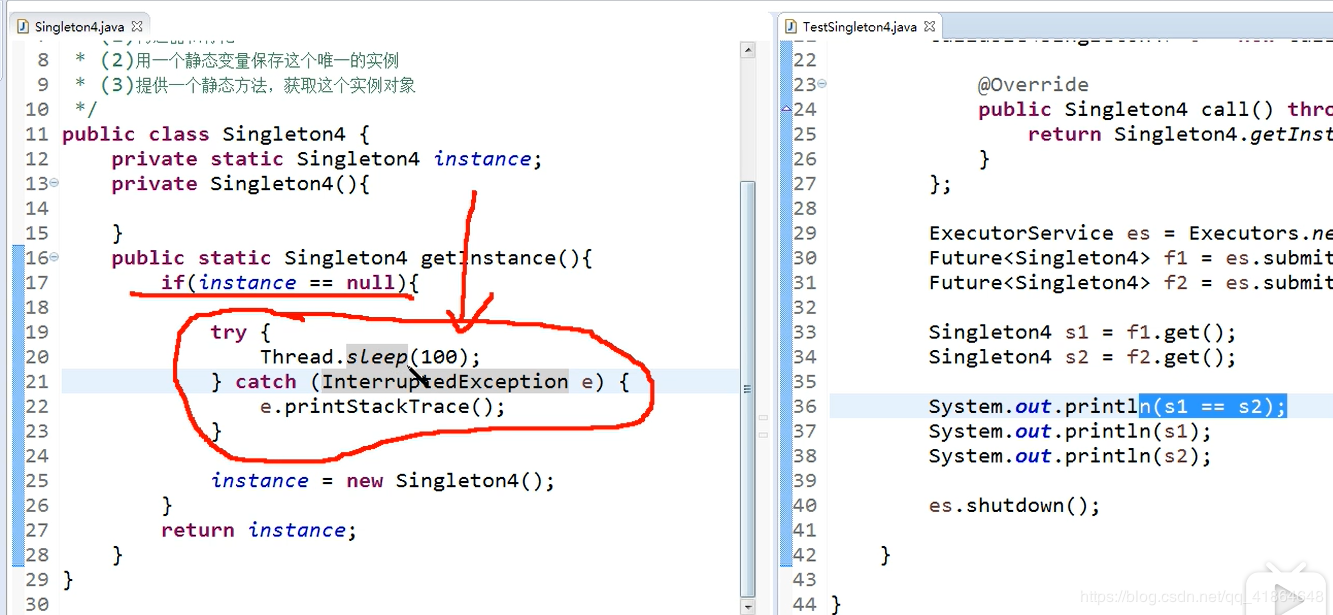
public class SingleTon {
private static SingleTon INSTANCE;
private SingleTon() {
}
public static SingleTon getInstance(){
if (INSTANCE == null){
try {
Thread.sleep(3000);
}catch (Exception e){
e.printStackTrace();
}
INSTANCE = new SingleTon();
}
return INSTANCE;
}
}
public class SingleTonTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Callable<SingleTon> callable = new Callable<SingleTon>() {
@Override
public SingleTon call() throws Exception {
return SingleTon.getInstance();
}
};
ExecutorService es = Executors.newFixedThreadPool(2);
Future<SingleTon> f1 = es.submit(callable);
Future<SingleTon> f2 = es.submit(callable);
es.shutdown();//停止执行
SingleTon s1 = f1.get();//获取线程执行的结果
SingleTon s2 = f2.get();
System.out.println(s1 == s2);//false 或true 随机出现
}
}
2.6 懒加载方式二:使用同步代码块解决线程安全问题
ps. 但是使用的线程安全的模式也会在一定程度上降低效率性噢
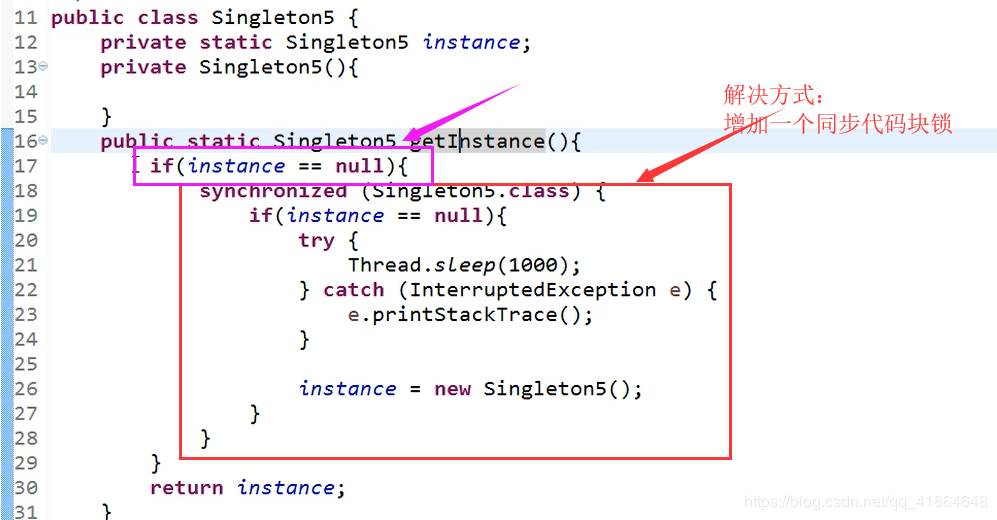
public class SingLetOnDemo {
private static SingLetOnDemo instance=null;
private SingLetOnDemo(){
System.out.println(Thread.currentThread().getName()+"构造方法执行");
}
//DCL 双重检索
public static SingLetOnDemo getInstance(){
if (instance==null){
synchronized (SingLetOnDemo.class){
if (instance==null){
instance=new SingLetOnDemo();
}
}
}
return instance;
}
public static void main(String[] args) {
SingLetOnDemo instance1 = getInstance();
SingLetOnDemo instance2 = getInstance();
System.out.println(instance1==instance2);
}
}
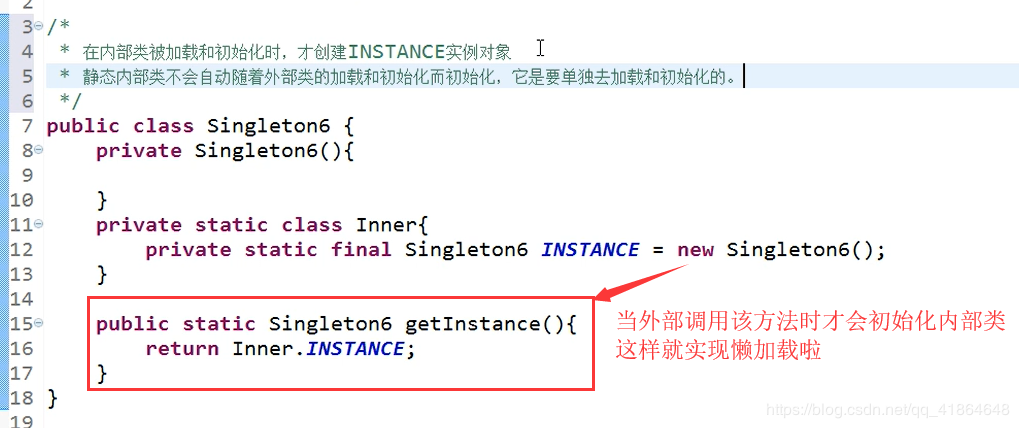
2.7 懒加载方式三:静态内部类中初始化实例
三、类初始化与实例初始化
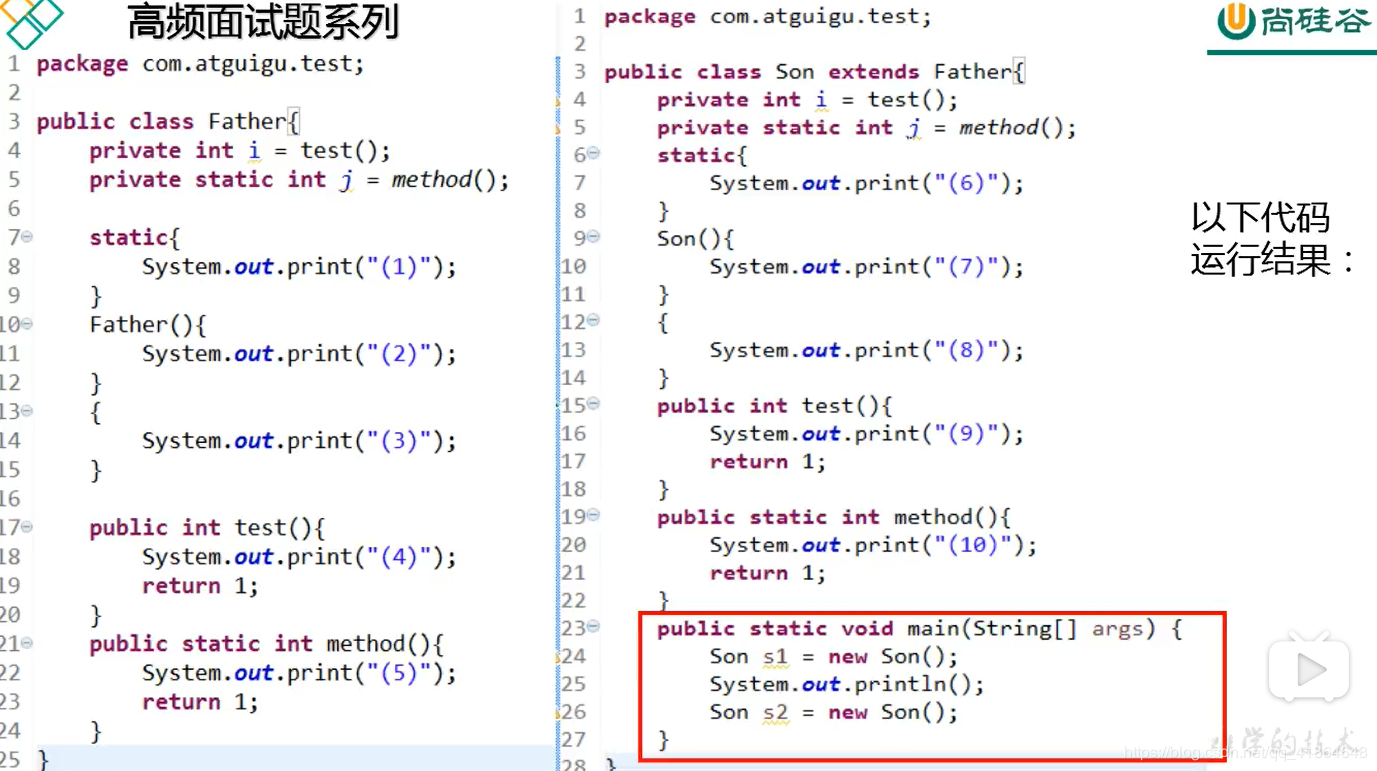
考点:
• 类初始化过程
①一个类要创建实例需要先加载并初始化该类
- main方法所在的类需要先加载和初始化
②一个子类要初始化需要先初始化父类
③一个类初始化就是执行 <clinit>()方法
<clinit>()方法由静态类变量显示赋值代码 和 静态代码块组成- 类变量显示赋值代码和静态代码块代码从上到下顺序执行
<clinit>()方法只执行一次
• 实例初始化过程
①实例初始化就是执行<init>()方法
- ()方法可能重载有多个,有几个构造器就有几个
<init>方法 <init>()方法由非静态实例变量显示赋值代码和非静态代码块、对应构造器代码组成- 非静态实例变量显示赋值代码和非静态代码块代码从上到下顺序执行,而对应构造器的代码最后执行
- 每次创建实例对象,调用对应构造器,执行的就是对应的
<init>方法 <init>方法的首行是super()或super(实参列表),即对应父类的<init>方法
• 方法的重写
①哪些方法不可以被重写
- final方法
- 静态方法
- private等子类中不可见方法
你还记得JVM中的非虚方法吗?
- 如果方法在编译期就确定了具体的调用版本,这个版本在运行时是不可变的,这样的方法就叫做非虚方法
- 静态方法、私有方法、final方法、实例构造器、父类方法都是非虚方法
- 其他方法称为虚方法
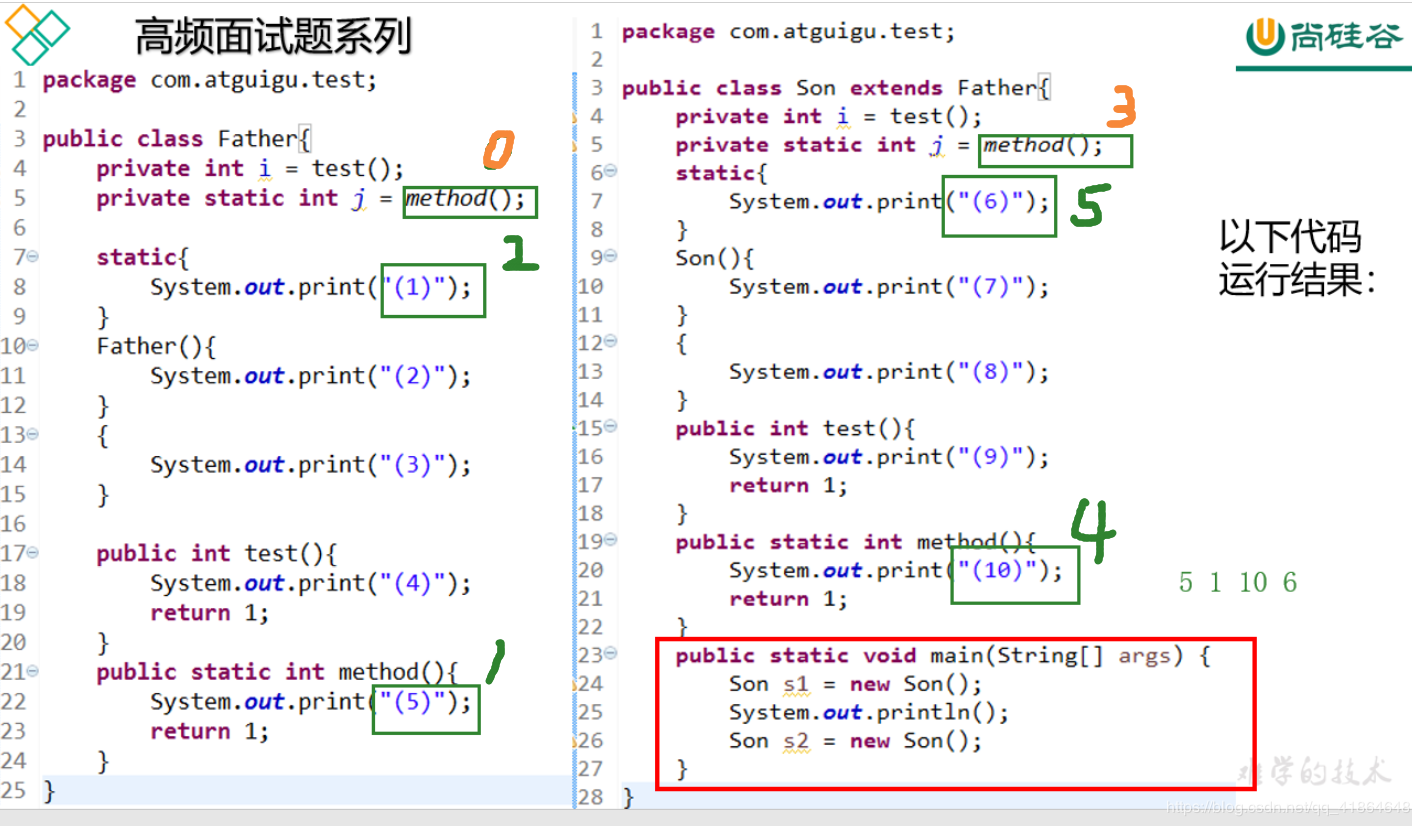
结果:
(5)(1)(10)(6)
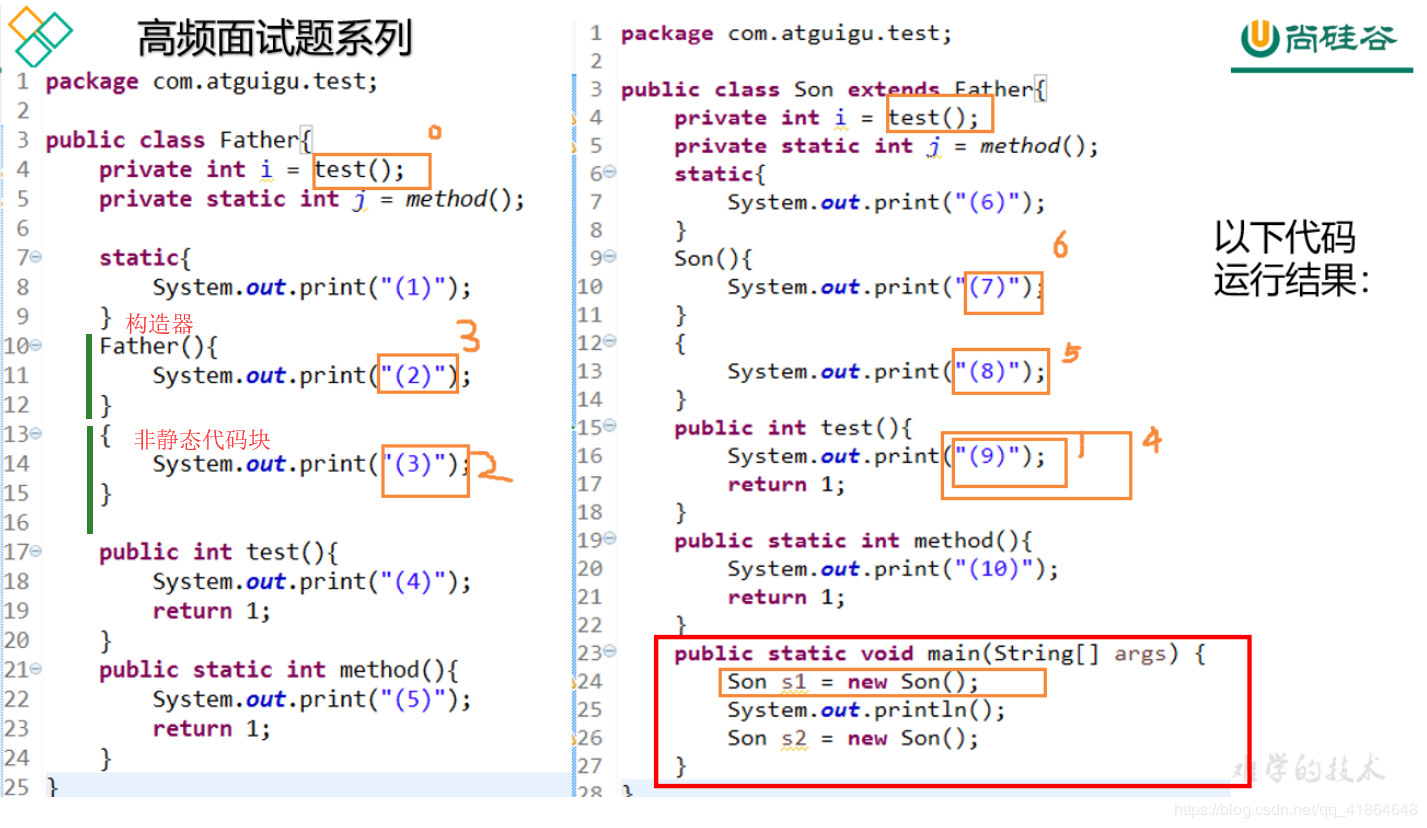
(9)(3)(2)(9)(8)(7)
(9)(3)(2)(9)(8)(7)
(5)(1)(10)(6)分析:首先是类初始化的规则
- 先执行main方法所在的类,由于再Son类继承自Father类,则必须先到父类里执行一次类初始化。
- 进行类的初始化。
- 从上到下顺序执行,静态变量和静态代码块
(9)(3)(2)(9)(8)(7)分析:其次是实例化过程规则
- 实例化Son对象的过程,
- 实例化过程
<init>是找非静态变量和非静态代码块 顺序执行,最后执行构造器. - 本题Son继承自父类,会调用super方法实例化父类。所以先到父类中执行对象实例化过程。
-
在father类中第一个非静态变量调用了test()方法,而在子类中也有一个同名的test()重写过的方法,由于重写,则本次test()实际执行的是子类里的test:9
-
然后顺序执行father类中的非静态代码块,打印:3
-
最后是father的构造器,打印:2
-
父类完毕
-
- 子类实例化过程
- Son类中第一个非静态成员调用了test() 方法打印:9
- 按顺序执行非静态代码块:打印:8
- 最后执行Son类的构造器:打印、7
- 子类完毕
四、方法的参数传递机制
规则描述:
一:形参是基本数据类型
- 传递数据值
二:实参是引用类型
- 传递地址值
- 特殊类型:Strng类、包装类的不可变性
如上图,change方法和main方法在栈中变量的值和地址,包装类都是引用的相同地址,值类型的局部变量是不同的但是因为值传递拷贝了对方的数据值。
如果在 change方法中改变局部变量会怎么样?
(1)j += 1;改变 j 变量,只会使得chage方法区中的 j 变量修改值,变量 j 和变量 i 并没有关系。所以 main 方法区的变量 i 是丝毫不影响的。
(2)s += "world";,String类的不可变性,使用+=的赋值,会在常量池中创建“world”字符串,然后 “hello”和“world”拼接,在常量池中组成一个新的字符串“helloworld”,再次赋值给 s 变量时,只是将新的引用地址赋值给变量s,也就是说,这个语句执行完后 变量 s 的指向地址就变了,而且仅仅是 chage() 方法区的 变量s变了,原来的实参没有参与,对main方法区的变量 str是丝毫不影响的。
(3)n += 1;改变包装类和字符串的原理类似,首先在堆内存中开辟新的空间存201这个新数值,然后 变量 n 引用新地址。这都是在change方法局部变量,对main的变量num丝毫不影响。
(4)a[0] += 1;改变的是数组中某个元素的值,它和上面不一样。首先它会根据地址在堆内存找到这个数组,然后将堆内存中的第一个元素的值直接改为 +1,这个过程这个数组的地址没变,元素的索引位置都没变。由于 change方法局部变量 a 和 main方法局部变量 arr,引用的还是这个数组,(从根儿上元素值就变了)所以起到了一变全变的效果。
(5)m.a += 1;改变的是自定义类实例 m中的成员变量int a = 1 ;的值。它和(4)原理是一样的,m就像是那个存储集合,a是其中一个元素。一变都变。
五、成员变量与局部变量
考点:
- 就近原则
- 变量分类:
- 成员变量:类变量、实例变量
- 局部变量
- 非静态代码块的执行
- 方法的调用规则:调用一次执行一次
局部变量与成员变量的区别:
①声明的位置
- 局部变量:方法体{}中,形参,代码块{}中
- 成员变量:类中方法外
- 类变量:有static修饰
- 实例变量:没有static修饰
②修饰符
- 局部变量:final
- 成员变量:public、protected、private、final、static、volatile、transient
③值存储的位置
- 局部变量:栈(未发生逃逸,会进行栈上分配与标量替换)
- 实例变量:堆
- 类变量:方法区

④作用域
- 局部变量:从声明处开始,到所属的}结束
- 实例变量:在当前类中“this.”(有时this.可以缺省),在其他类中“对象名.”访问
- 类变量:在当前类中“类名.”(有时类名.可以省略),在其他类中“类名.”或“对象名.”访问
⑤生命周期
- 局部变量:每一个线程,每一次调用执行都是新的生命周期
- 实例变量:随着对象的创建而初始化,随着对象的被回收而消亡,每一个对象的实例变量是独立的
- 类变量:随着类的初始化而初始化,随着类的卸载而消亡,该类的所有对象的类变量是共享的
下面看一个栗子:
public class Exams
{
static int s;//类变量
int i;//成员变量,实例变量
int j;//成员变量,实例变量
{
int i = 1;//局部变量
i++;//这里的i是就近的局部变量i(第7行)
j++;//这里的j是就近的成员变量j(第5行)
s++;//这里的s是就近的类变量s(第3行)
}
public void test(int j){
j++;//局部变量,这里的j是就近的j(形参j)
i++;//这里的i是this.i是成员变量(第4行)
s++;//这里的s是成员变量s(第3行)
}
public static void main(String[] args) {
Exams obj1 = new Exams();
Exams obj2 = new Exams();
obj1.test(10);
obj1.test(20);
obj2.test(20);
System.out.println("obj1: "+ obj1.i +","+ obj1.j +","+ obj1.s);//obj1: 2,1,5
System.out.println("obj2: "+ obj2.i +","+ obj2.j +","+ obj2.s);//obj2: 1,1,5
}
}
步骤分析:
Exams obj1 = new Exams();
(1)首先看 obj1 的实例化,首先执行
<init>().(非静态变量和非静态代码块),这个方法在栈中开辟新空间。
int i = 1; i++;这里的 i 是init方法区里的另一个变量,做加加操作也是在这个方法区里进行的,和外面的 i 都没有半毛钱关系。- j++; 这个 j 因为就近原则可就是成员变量里那个如假包换的 j 了,做加加操作修改的是堆内存里成员变量 j 噢!
- s++; 这个 s 也因为就近原则,它就是类变量s,这俩是同一个人~所以是类变量那个s加加了
- 到这执行完非静态代码块,obj1.i 不变= 0,obj1.j 加一=1,s 加一=1
obj1.test(10);
(2) obj1.test(10)
- 进入test() 方法区开工啦
j++变量 j 这里是形参 j ,和obj1的成员变量那个j差了十万八千里呢!而且传入的参数是10,这个j是11了。i++;这个i因为就近原则是成员变量 i ,所以obj1.i 变1了s++;这个s也是成员变量s,所以s变成2了- 总结:执行完test()方法,obj1.i 加一=1,obj1.j 不变=1,s加一=2
由此可见,这个输出结果和 test()
那个传入参数没有半点关系。老师视频里这个例子代码,obj1对象调用了两次test()方法,所以obj1,根据增量在test()方法中 i会+1,j不变,s+1
Exams obj2 = new Exams();
(3)再次实例化一个对象,obj2实例化时会开辟自己的
<init>()方法区,并拥有自己独有的成员变量 i,j
。但是注意类变量 s,它是属于这个类的,s还是那个s
- 实例化obj2对象,执行上面相同步骤 obj2.i 不变= 0,obj2.j 加一=1,s 加一=3
- obj2.test(20) ,步骤一样,obj2.i 加一=1,obj2.j不变=1,s加一=4
所以最后结果是
obj1 : 1 1 4
obj2:1 1 4
视频里obj1调用两次test方法,那一步多执行一次,根据增量自己推算一下结果吧,推算对了就说明你已经懂了。
结果是:
obj1: 2 1 5
obj2: 1 1 5

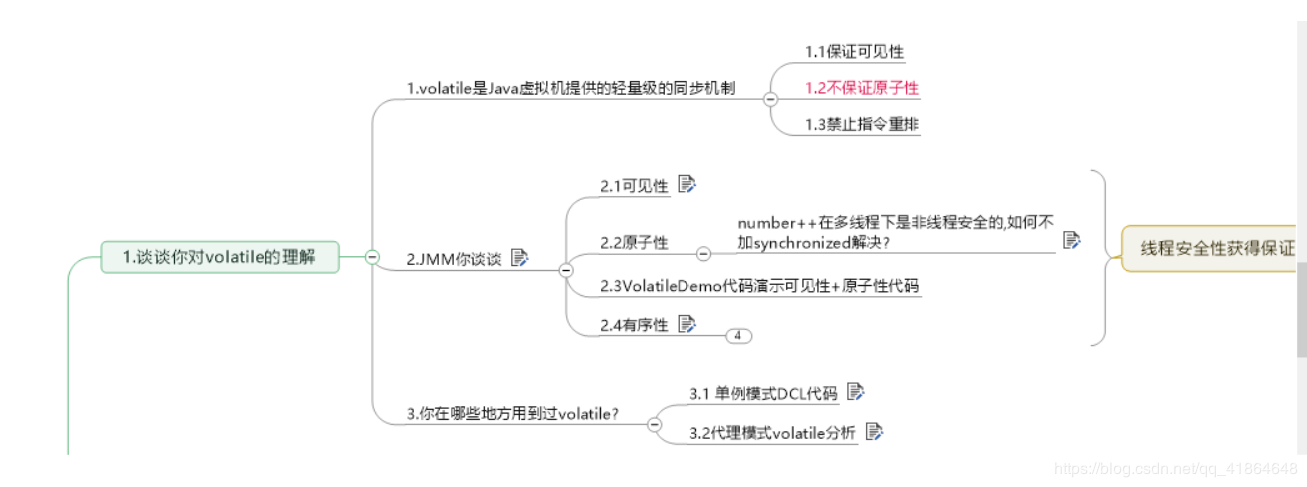
六、volatile特性
- 保证可见性
- 不保证原子性
- 禁止指令重排
什么是可见性:
内存的可见性是指线程之间的可见性,一个线程的修改状态对另外一个线程是可见的,用通俗的话说,就是假如一个线程A修改一个共享变量flag之后,则线程B去读取,一定能读取到最新修改的flag。
导致不可见得原因:
- 1、cache机制导致内存不可见 线程在运行的过程中会把主内存的数据拷贝一份到线程内部cache中,也就是working memory。这个时候多个线程访问同一个变量,其实就是访问自己的内部cache。
- 2、除了cache的原因,重排序后的指令在多线程执行时也有可能导致内存不可见,由于指令顺序的调整,线程A读取某个变量的时候线程B可能还没有进行写入操作呢,虽然代码顺序上写操作是在前面的。
保证可见性:
一个说法是使用 volatile的变量 依然会被读到 cache中,只不过当B线程修改了flag之后,会将flag写回主内存,同时会通过信号机制通知到 A线程 去同步内存中flag的值。
什么是指令重排?
但是指令重排只会保证串行语义的执行一致性(单线程) 并不会关心多线程间的语义一致性。
6.1 JMM内存模型
JMM(Java内存模型Java Memory Model,简称JMM)本身是一种抽象的概念 并不真实存在,它描述的是一组规则或规范通过规范定制了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式.
JMM关于同步规定:
- 1.线程解锁前,必须把共享变量的值刷新回主内存
- 2.线程加锁前,必须读取主内存的最新值到自己的工作内存
- 3.加锁解锁是同一把锁
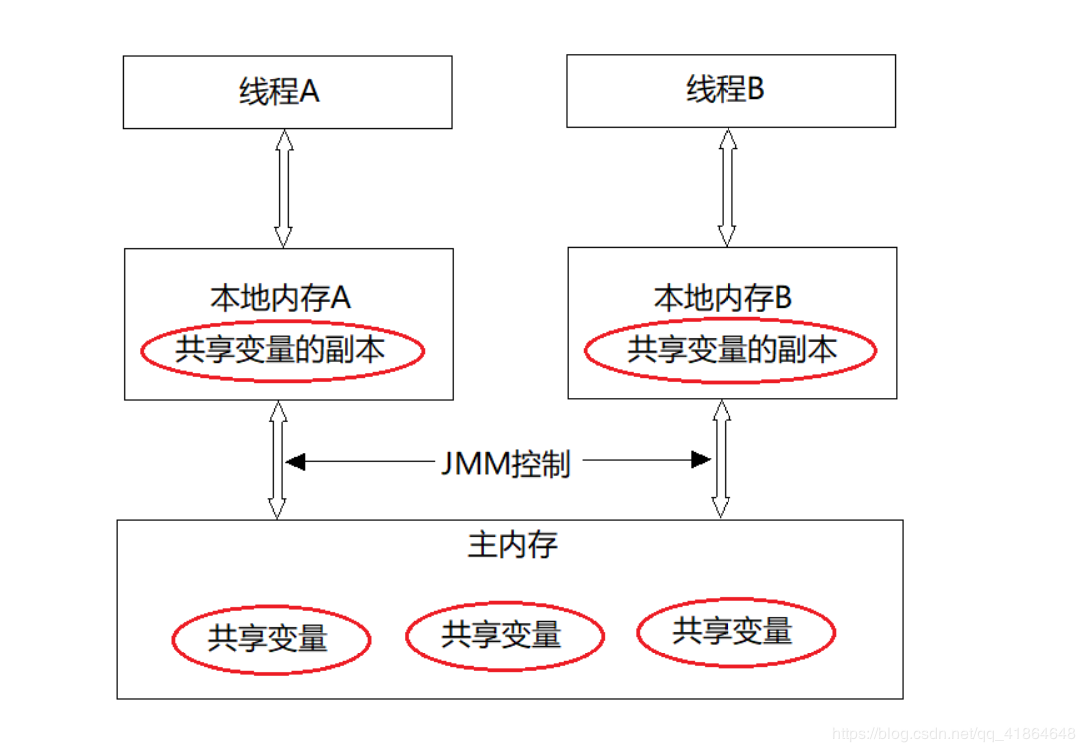
由于JVM运行程序的实体是线程,而每个线程创建时JVM都会为其创建一个工作内存(有些地方成为栈空间),工作内存是每个线程的私有数据区域,而Java内存模型中规定所有变量都存储在主内存,主内存是共享内存区域,所有线程都可访问,
但线程对变量的操作(读取赋值等)必须在工作内存中进行,首先要将变量从主内存拷贝到自己的工作空间,然后对变量进行操作,操作完成再将变量写回主内存,不能直接操作主内存中的变量,各个线程中的工作内存储存着主内存中的变量副本拷贝,因此不同的线程无法访问对方的工作内存
.因此线程间的通讯(传值) 必须通过主内存来完成,其简要访问过程如下图:
在哪些地方需要用volatile?
- 单例设计模式的DCL双重检索机制
回顾上个标题的单例设计模式,在懒加载时为了解决多线程问题,而使用同步代码块的方法,和这里加 volatile 的目的是一样的,因为 volatile 保证了可见性。
private static volatile SingletonDemo instance=null;
七、JVM垃圾回收机制
八、SSM面试题
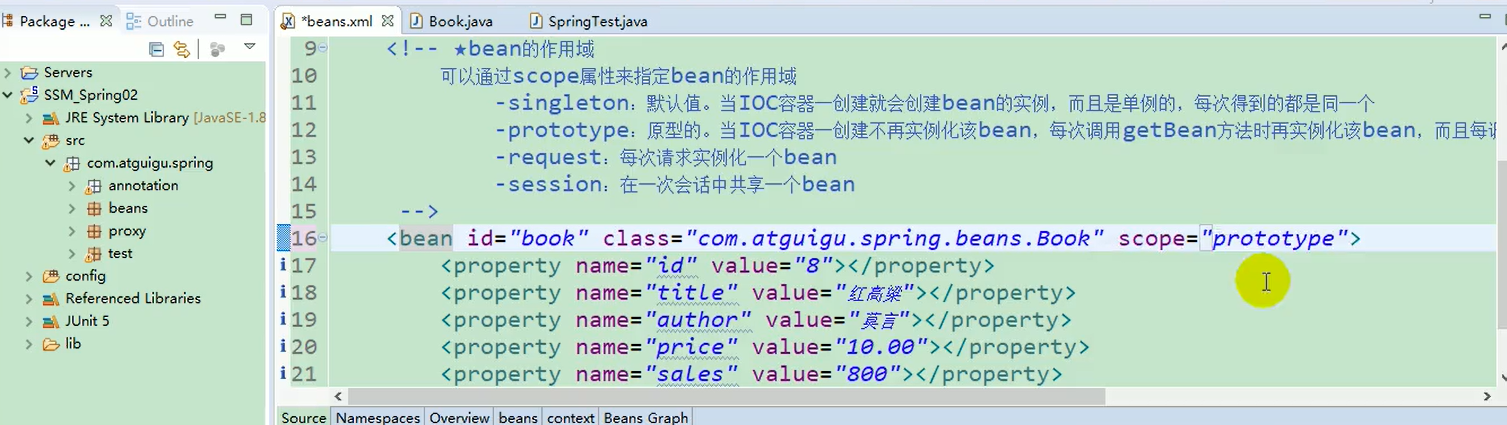
8.1 Spring中Bean的作用域


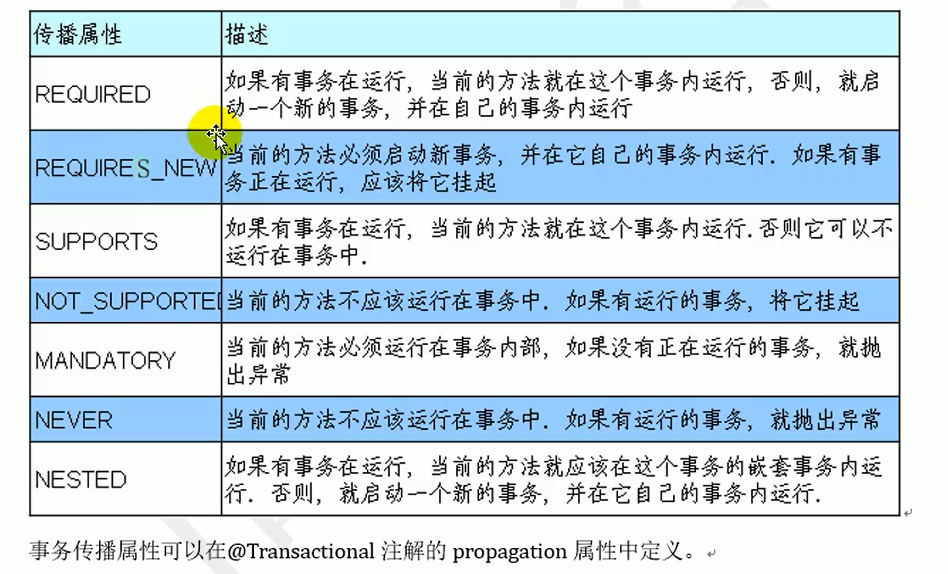
8.2 事务的传播属性与事务的隔离级别