文章目录
一、Integer
参考原文:https://www.cnblogs.com/helloworld2048/p/10853845.html
构造方法
- public Integer(int value)
- public Integer(String s) 数字字符串转换成integer
基本进制转换
静态方法
-
Integer.toBinaryString(int i)
-
Integer.toOctalString(int i)
-
Integer.toHexString(int i)
-
public static String toString(100, 8);//将100转换为八进制 public static int parseInt("100", 2);//将100字符串转换为二进制int型
JDK5新特性:自动拆装箱
装箱 :Integer.valueOf(int x)
拆箱 :ii.intValue()
public class IntegerDemo {
public static void main(String[] args) {
Integer i = 100; //自动装箱
i += 200; //自动拆箱、再自动装箱
System.out.println("i : " + i);
//通过反编译后的代码
Integer i = Integer.valueOf(100); //由此可见,自动装箱的步骤是调用了 valueOf方法
i = Integer.valueOf(i.intValue() + 200);
System.out.println(new StringBuilder("i : ").append(i).toString());
}
}
valueOf()方法的陷阱
我们知道,Integer类的自动装箱原理是因为该过程 调用了 valueOf() 方法,来看一下 valueOf() 的源码
/**
* 当参数中的基本类型i在 -128~127 范围内时,使用的是缓存区中的实例
* 超出范围的一律 new 构建新对象
*/
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
其实,除了 Integer类型,其他的整数类型都有valueOf 方法,也都有一个自己的范围内缓冲区。
其他类型的缓存范围为:
- Integer类型有缓存-128-127的对象。缓存上限可以通过配置jvm更改
- Byte,Short,Long类型有缓存(-128-127)
- Character缓存0-127
- Boolean缓存TRUE、FALSE
尤其需要特别注意的是,只有valueOf方法构造对象时会用到缓存,new方法等不会使用缓存!
其他浮点型包装类valueOf方法没有用到缓存。
Double i1 = Double.valueOf(0.1);
Double i2 = Double.valueOf(0.1);
System.out.println(i1 == i2); //false, valueOf方法内部实际上也是new
System.out.println(Integer.valueOf(1) ==Integer.valueOf(1)); //true
System.out.println(Integer.valueOf(999) ==Integer.valueOf(999)); //false
Integer i4 = Integer.valueOf(1);//手动装箱
Integer i5 =1;//自动装箱
System.out.println(i4 == i5); //true
Integer i7 = Integer.valueOf(999);
Integer i8 = 999;
System.out.println(i7 == i8); //false
Integer与int的区别
- Integer是int的包装类,int 则是java的一种基本数据类型
- 2、Integer变量必须实例化后才能使用,而int变量不需要
- 3、Integer实际是对象的引用,当new一个Integer时,实际上是生成一个指针指向此对象;而int 则是直接存储数据值
- 4、Integer的默认值是null,int的默认值是0
类型转换法则
以下静态方法
- Integer.parseInt(String s) 将字符串转换为int
- Xxx.yyyValue( ) 手动拆箱
- Xxx.valueOf(yyy) 手动装箱
public static int parseInt(String s) throws NumberFormatException {
return parseInt(s,10);
}
建议避免无意中的装箱、拆箱行为,尤其是在性能敏感的场合,创建 10 万个 Java 对象和 10 万个整数的开销可不是一个数量级的,不管是内存使用还是处理速度,光是对象头的空间占用就已经是数量级的差距了。
提升:AtomicInteger线程安全版
Java自带的线程安全的基本类型包括:
- AtomicInteger,
- AtomicLong,
- AtomicBoolean,
- AtomicIntegerArray,
- AtomicLongArray等
AtomicInteger类中有有一个变量valueOffset,用来描述AtomicInteger类中value的内存位置 。
当需要变量的值改变的时候,先通过get()得到valueOffset位置的值,也即当前value的值.给该值进行增加,并赋给next
compareAndSet()比较之前取到的value的值当前有没有改变,若没有改变的话,就将next的值赋给value,倘若和之前的值相比的话发生变化的话,则重新一次循环,直到存取成功,通过这样的方式能够保证该变量是线程安全的
value使用了volatile关键字,使得多个线程可以共享变量,使用volatile将使得VM优化失去作用,在线程数特别大时,效率会较低。
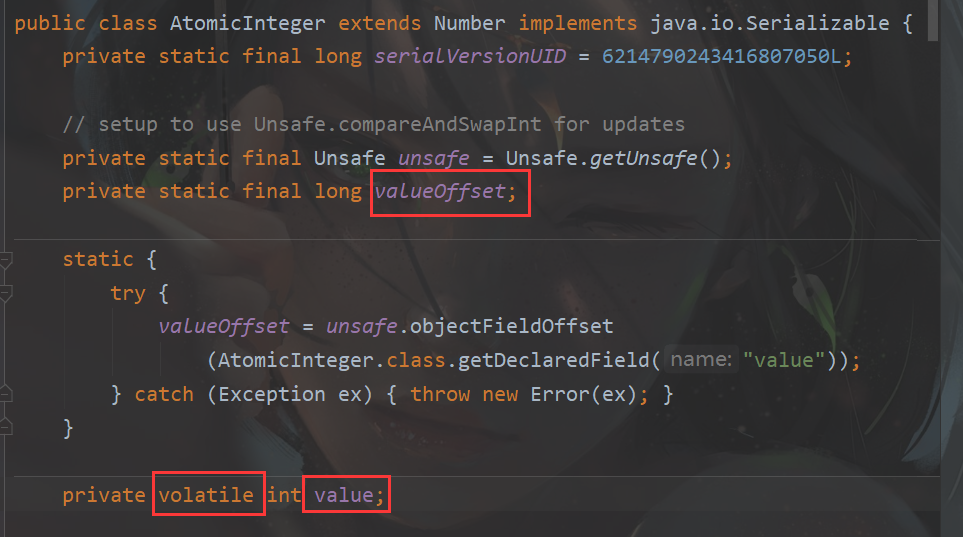
// AtomicInteger使用了volatile关键字进行修饰,使得该类可以满足线程安全。
private static AtomicInteger atomicInteger = new AtomicInteger(1);
static Integer count1 = Integer.valueOf(0);
private void startThread1() {
for (int i = 0;i < 200; i++){
new Thread(new Runnable() {
@Override
public void run() {
for (int k = 0; k < 50; k++){
// getAndIncrement: 先获得值,再自增1,返回值为自增前的值
count1 = atomicInteger.getAndIncrement();
}
}
}).start();
}
// 休眠10秒,以确保线程都已启动
try {
Thread.sleep(1000*10);
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
Log.e("打印日志----",count1+"");
}
}
//期望输出10000,最后输出的是10000
二、Character包装类
一些常用方法
- public static boolean isUpperCase(char ch)
- public static boolean isLowerCase(char ch)
- public static boolean isDigit(char ch)
- public static char toUpperCase(char ch)
- public static char toLowerCase(char ch)
- boolean isLetter(char ch) //判断指定字符是否为字母。
- boolean isWhitespace(char ch)//判断指定字符是否为空白字符。
简单应用:统计字符串中大小写及数字出现的次数
/**
* 统计字符串中的大写字母、小写字母、数字的个数
*/
public class String2character {
public static void main(String[] args) {
int bigCount = 0;
int smallCount = 0;
int numberCount = 0;
Scanner sc = new Scanner(System.in);
System.out.println("请输入内容:");
String line = sc.nextLine();
char[] chars = line.toCharArray();
for (int i = 0; i < chars.length ;i++){
if (Character.isUpperCase(chars[i])){
bigCount ++;
}else if (Character.isLowerCase(chars[i])){
smallCount ++;
}else if (Character.isDigit(chars[i])){
numberCount ++;
}
}
System.out.println("大写字母 " + bigCount);
System.out.println("小写字母 " + smallCount);
System.out.println("数字字母 " + numberCount);
}
}
三、Float包装类精度问题
01、原始类型的 float
第一题是这样的,代码如下
public class FloatPrimitiveTest {
public static void main(String[] args) {
float a = 1.0f - 0.9f;
float b = 0.9f - 0.8f;
if (a == b) {
System.out.println("true");
} else {
System.out.println("false");
}
}
}
// true or false?
false
float a = 1.0f - 0.9f;
System.out.println(a); // 0.100000024
float b = 0.9f - 0.8f;
System.out.println(b); // 0.099999964
加上两条打印语句后,我明白了,原来发生了精度问题。
Java 语言支持两种基本的浮点类型:float 和 double ,以及与它们对应的包装类 Float 和 Double 。它们都依据 IEEE 754 标准,该标准用科学记数法以底数为 2 的小数来表示浮点数。
但浮点运算很少是精确的。虽然一些数字可以精确地表示为二进制小数,比如说 0.5,它等于 2-1;但有些数字则不能精确的表示,比如说 0.1。因此,浮点运算可能会导致舍入误差,产生的结果接近但并不完全等于我们希望的精确结果。
Java 对于任意一个浮点字面量,最终都舍入到所能表示的最靠近的那个浮点值,遇到该值离左右两个能表示的浮点值距离相等时,默认采用偶数优先的原则——这就是为什么我们会看到两个都以 4 结尾的浮点值的原因。
02、包装器类型 Float
再来看第二题,代码如下:
public class FloatWrapperTest {
public static void main(String[] args) {
Float a = Float.valueOf(1.0f - 0.9f);
Float b = Float.valueOf(0.9f - 0.8f);
if (a.equals(b)) {
System.out.println("true");
} else {
System.out.println("false");
}
}
}
// true or false?
Float a = Float.valueOf(1.0f - 0.9f);
System.out.println(a); // 0.100000024
Float b = Float.valueOf(0.9f - 0.8f);
System.out.println(b); // 0.099999964
加上两条打印语句后,我明白了,原来包装器并不会解决精度的问题。
从下面的源码可以看得出来,包装器 Float 的确没有对精度做任何处理,况且 equals 方法的内部仍然使用了 == 进行判断。
private final float value;
//构造器
public Float(float value) {
this.value = value;
}
public static Float valueOf(float f) {
return new Float(f);
}
public boolean equals(Object obj) {
return (obj instanceof Float)&& (floatToIntBits(((Float)obj).value) == floatToIntBits(value));
}
03.再来一个小数精度问题:double传参给BigDecimal
BigDecimal a = new BigDecimal(0.1);
System.out.println(a); // 0.1000000000000000055511151231257827021181583404541015625
BigDecimal b = new BigDecimal("0.1");
System.out.println(b); // 0.1
Java在java.math包中提供的API类BigDecimal,用来对超过16位有效位的数进行精确的运算。双精度浮点型变量double可以处理16位有效数,但在实际应用中,可能需要对更大或者更小的数进行运算和处理。
Java之BigDecimal详解 : https://blog.csdn.net/P_FastrackJava/article/details/104671241
a 和 b 的唯一区别就在于 a 在调用 BigDecimal 构造方法赋值的时候传入了浮点数,而 b 传入了字符串
解释:使用 double 传参的时候会产生不可预期的结果,比如说 0.1 实际的值是
解释:使用字符串传参的时候会产生预期的结果,比如说 new BigDecimal(“0.1”) 的实际结果就是 0.1。
解释:如果必须将一个 double 作为参数传递给 BigDecimal 的话,建议传递该 double 值匹配的字符串值。方式有两种:
double a = 0.1;
System.out.println(new BigDecimal(String.valueOf(a))); // 0.1
System.out.println(BigDecimal.valueOf(a)); // 0.1
第一种,使用 String.valueOf() 把 double 转为字符串。
第二种,使用 valueOf() 方法,该方法内部会调用 Double.toString() 将 double 转为字符串,源码如下:
public static BigDecimal valueOf(double val) {
// Reminder: a zero double returns '0.0', so we cannot fastpath
// to use the constant ZERO. This might be important enough to
// justify a factory approach, a cache, or a few private
// constants, later.
return new BigDecimal(Double.toString(val));
}