文章目录
一、 操作数据库
DDL:定义数据库对象:数据库,表,列等,关键字:create, drop,alter,show 等
-
操作数据库:CRUD
- 创建 create
-- 创建数据库 create database 数据库名称; -- 创建数据库,判断不存在,再创建: create database if not exists 数据库名称; -- 创建数据库,并指定字符集 create database 数据库名称 character set 字符集名; -- 练习: 创建db4数据库,判断是否存在,并制定字符集为gbk create database if not exists db4 character set gbk;- 查询 show
-- 查询所有数据库的名称: show databases; -- 查询某个数据库的字符集:查询某个数据库的创建语句 show create database 数据库名称; -- 查询当前正在使用的数据库名称 select database(); -- 查询当前数据库中所有表 SHOW TABLES; -- 查询表中所有字段的详细信息 SHOW COLUMNS FROM 表名;– 查询表中所有字段的详细信息
SHOW COLUMNS FROM 表名;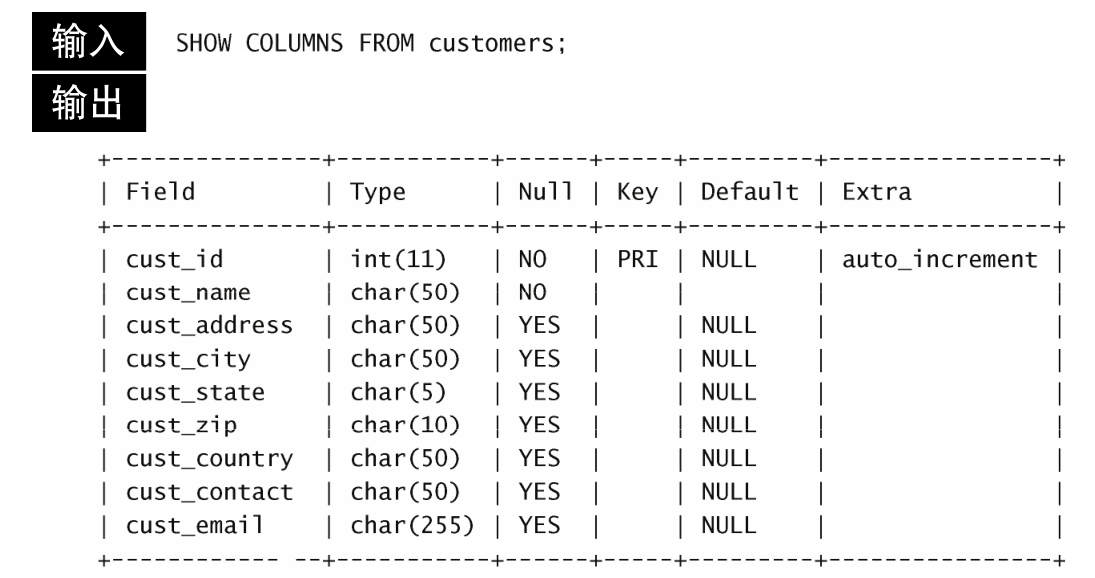

其他:
SHOW STATUS,用于显示广泛的服务器状态信息;SHOW CREATE DATABASE和SHOW CREATE TABLE,分别用来显示创建特定数据库或表的MySQL语句;SHOW GRANTS,用来显示授予用户(所有用户或特定用户)的安全权限;SHOW ERRORS和SHOW WARNINGS,用来显示服务器错误或警告消息。
- 修改 alter
-- 修改数据库的字符集 alter database 数据库名称 character set 字符集名称;- 删除 drop
-- 删除数据库 drop database 数据库名称; -- 判断数据库存在,存在再删除 drop database if exists 数据库名称;- 使用数据库 use
use 数据库名称;
二、操作表
1.创建表
语法:
create table 表名(
列名1 数据类型1,
列名2 数据类型2,
…
列名n 数据类型n
);
create table student(
id int,
name varchar(32),
age int ,
score double(4,1),
birthday date,
insert_time timestamp
);
数据类型:
> 1. int:整数类型
> 2. double:小数类型:score double(5,2)
> 3. date:日期,只包含年月日,yyyy-MM-dd
> 4. datetime:日期,包含年月日时分秒 yyyy-MM-dd HH:mm:ss
> 5. timestamp:时间戳类型 包含年月日时分秒 yyyy-MM-dd HH:mm:ss
> * 如果将来不给这个字段赋值,或赋值为null,则默认使用当前的系统时间,来自动赋值
>
> 6. varchar:字符串
> * name varchar(20):姓名最大20个字符
- zhangsan 8个字符 张三 2个字符
主键的注意事项
含义:非空且唯一。一张表只能有一个字段为主键,主键就是表中记录的唯一标识
在创建表时,添加主键约束
create table stu(
id int primary key,-- 给id添加主键约束
name varchar(20)
);
创建完表后,后添加主键
ALTER TABLE stu MODIFY id INT PRIMARY KEY;
删除主键
-- 错误 alter table stu modify id int ;
ALTER TABLE stu DROP PRIMARY KEY;

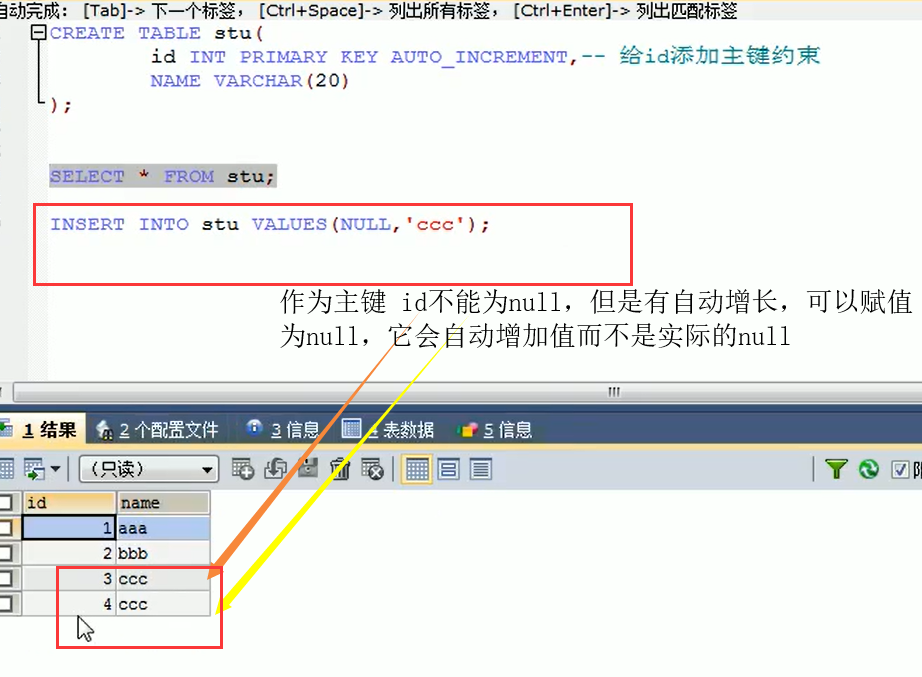
auto_increment 自增长的注意事项
概念:如果某一列是数值类型的,使用 auto_increment 可以来完成值得自动增长
在创建表时,添加主键约束,并且完成主键自增长
create table stu(
id int primary key auto_increment,-- 给id添加主键约束
name varchar(20)
);
alter table stu modify id int not null primary key auto_increment;
删除自动增长
ALTER TABLE stu MODIFY id INT;
添加自动增长
ALTER TABLE stu MODIFY id INT AUTO_INCREMENT;
使用该约束的为标识列。自动增长必须和主键搭配吗? 答:不一定
标识列自动增长必须是数值类型,也可以通过set auto_increment_increment = 3设置步长。


指定默认值
如果在插入行时没有给出值,MySQL允许指定此时使用的默认值。默认值用CREATE TABLE 语句的列定义中的DEFAULT关键字指定。
注意:
不允许函数 与大多数DBMS不一样,MySQL不允许使用函数作为默认值,它只支持常量。
使用默认值而不是 NULL 值 许多数据库开发人员使用默认值而不是 NULL 列,特别是对用于计算或数据分组的列更是如此。
引擎类型注意事项
你可能已经注意到,迄今为止使用的 CREATE TABLE 语句全都以ENGINE=InnoDB 语句结束。与其他DBMS一样,MySQL有一个具体管理和处理数据的内部引擎。
在你使用 CREATE TABLE 语句时,该引擎具体创建表,而在你使用 SELECT语句或进行其他数据库处理时,该引擎在内部处理你的请求。多数时候,此引擎都隐藏在DBMS内,不需要过多关注它。
但MySQL与其他DBMS不一样,它具有多种引擎。它打包多个引擎,这些引擎都隐藏在MySQL服务器内,全都能执行 CREATE TABLE 和 SELECT等命令。
为什么要发行多种引擎呢?因为它们具有各自不同的功能和特性,为不同的任务选择正确的引擎能获得良好的功能和灵活性。
当然,你完全可以忽略这些数据库引擎。如果省略 ENGINE= 语句,则使用默认引擎(很可能是 MyISAM ),多数SQL语句都会默认使用它。但并不是所有语句都默认使用它,这就是为什么 ENGINE= 语句很重要的原因(也就是为什么本书的样列表中使用两种引擎的原因)。
以下是几个需要知道的引擎:
- InnoDB 是一个可靠的事务处理引擎(参见第26章),它不支持全文本搜索;
- MEMORY 在功能等同于 MyISAM ,但由于数据存储在内存(不是磁盘)中,速度很快(特别适合于临时表);
- MyISAM 是一个性能极高的引擎,它支持全文本搜索(参见第18章),但不支持事务处理。
引擎类型可以混用。除 productnotes 表使用 MyISAM 外,本书中的样例表都使用 InnoDB 。原因是作者希望支持事务处理(因此,使用 InnoDB ),但也需要在 productnotes 中支持全文本搜索(因此,使用 MyISAM )。

那么,你应该使用哪个引擎?这有赖于你需要什么样的特性。 MyISAM由于其性能和特性可能是最受欢迎的引擎。但如果你不需要可靠的事务处理,可以使用其他引擎。
2. 复制表:
# 复制全表以及数据
create table 表名 like 被复制的表名;
# 复制表结构以及name=张三的数据
create table copy01
select id,name
form stu
where name=‘张三’;
# 仅复制表结构
create table copy01
select id,name
form stu
where 1=2;
3.查询表
-- 查询某个数据库中所有的表名称
show tables;
-- 查询表结构
desc 表名;
4. 修改表
修改表名
alter table 表名 rename to 新的表名;
alter table oldtable rename to newtable
修改表的字符集
alter table 表名 character set 字符集名称;
添加一列
alter table 表名 add 列名 数据类型;
alter table stu add phoneNum varchar(11);
删除一列
alter table stu drop 列名;
alter table stu drop column phoneNum;
修改列名称 类型
alter table 表名 change 列名 新列别 新数据类型;
alter table 表名 modify 列名 新数据类型;
为表添加外键
ALTER TABLE stu
add constraint fk_courseid foreign key (stu_courseid) references course(id);
5. 删除表
drop table 表名;
drop table if exists 表名 ;
复杂的表结构更改一般需要手动删除过程,它涉及以下步骤:
- 用新的列布局创建一个新表;
- 使用 INSERT SELECT 语句(关于这条语句的详细介绍,请参阅第19章)从旧表复制数据到新表。如果有必要,可使用转换函数和计算字段;
- 检验包含所需数据的新表;
- 重命名旧表(如果确定,可以删除它);
- 用旧表原来的名字重命名新表;
- 根据需要,重新创建触发器、存储过程、索引和外键。

三、 操作数据
- 表的数据进行增删改。关键字==:insert, delete, update== 等
1. 添加
- 添加一条数据
insert into 表名(列名1,列名2,...列名n) values(值1,值2,...值n);
INSERT INTO stu(id,NAME,age) VALUES(1,"张无忌",20);

- 添加多条数据


- 添加检索出的数据
INSERT 一般用来给表插入一个指定列值的行。但是, INSERT 还存在另一种形式,可以利用它将一条 SELECT 语句的结果插入表中。这就是所谓的 INSERT SELECT ,顾名思义,它是由一条 INSERT 语句和一条 SELECT语句组成的。
假如你想从另一表中拷贝客户列表数据到你的 customers 表。不需要检索一行,然后再将它用 INSERT 插入,可以如下进行:


INSERT SELECT 中 SELECT 语句可包含 WHERE 子句以过滤插入的数据。
这个例子把一个名为 custnew 的表中的数据导入 customers 表中。为了试验这个例子,应该首先创建和填充 custnew 表。 custnew 表的结构与附录B中描述的 customers表的相同。在填充 custnew 时,不应该使用已经在 customers中使用过的 cust_id 值(如果主键值重复,后续的 INSERT 操作将会失败)或仅省略这列值让MySQL在导入数据的过程中产生新值。
2. 删除
delete from 表名 [where 条件] -- 不要忘记where子句!
- 如果要删除整张表,有几种方式呢?
- delete from 表名; – 不推荐使用。有多少条记录就会执行多少次删除操作
TRUNCATE TABLE 表名; – 删除表语句:
推荐使用,效率更高 先删除表,然后再创建一张一样的空表。

下面是许多SQL程序员使用 UPDATE 或 DELETE 时所遵循的习惯。
除非确实打算更新和删除每一行,否则绝对不要使用不带 WHERE子句的 UPDATE 或 DELETE 语句。
保证每个表都有主键(如果忘记这个内容,请参阅第15章),尽可能
像 WHERE 子句那样使用它(可以指定各主键、多个值或值的范围)。在对 UPDATE 或 DELETE 语句使用 WHERE 子句前,应该先用 SELECT 进行测试,保证它过滤的是正确的记录,以防编写的 WHERE 子句不正确。
使用强制实施引用完整性的数据库(关于这个内容,请参阅第15章),这样MySQL将不允许删除具有与其他表相关联的数据的行。
2. 修改
- 修改单个字段的值
update 表名 set 列名1 = 值1, 列名2 = 值2,... [where 条件];
UPDATE stu SET age=117 WHERE id=10;
-- 注意 如果不加任何条件,则会将表中所有记录全部修改
- 修改多个字段的值
UPDATE stu
SET age=18,name=LIli,sex='女'
WHERE id=10;
IGNORE 关键字 如果用 UPDATE 语句更新多行,并且在更新这些行中的一行或多行时出一个现错误,则整个 UPDATE 操作被取消(错误发生前更新的所有行被恢复到它们原来的值)。为即使是发生错误,也继续进行更新,可使用 IGNORE 关键字,如下所示:
UPDATE IGNORE customers
在 UPDATE 语句中使用子查询 UPDATE 语句中可以使用子查询,使得能用 SELECT 语句检索出的数据更新列数据。关于子
查询及使用的更多内容,请参阅第14章。
四、 查询数据
1. 普通查询
select id from products;
select * from products;
正如所见, SELECT 返回所有匹配的行。但是,如果你不想要每个值每次都出现,怎么办?例如,假如你想得出 products 表中产品的所有供应商ID:但是要去除重复的数据,
-- 去除重复字段值
SELECT DISTINCT vend_id from products;


2. 分组查询 : group by

group by的使用练习
-- 3.分组查询: group by
-- 按照性别分组。分别查询男、女同学的平均分
SELECT sex , AVG(math) FROM student GROUP BY sex;
-- 按照性别分组。分别查询男、女同学的平均分,人数
SELECT sex , AVG(math),COUNT(id) FROM student GROUP BY sex;
-- 按照性别分组。分别查询男、女同学的平均分,人数 要求:数学分数低于70分的人,不参与分组
SELECT sex , AVG(math),COUNT(id) FROM student WHERE math > 70 GROUP BY sex;
-- 按照性别分组。分别查询男、女同学的平均分,人数 要求:分数低于70分的人,不参与分组,分组之后。人数要大于2个人
SELECT sex , AVG(math),COUNT(id) FROM student WHERE math > 70 GROUP BY sex HAVING COUNT(id)> 2;
#3、分组后筛选
#案例1:查询哪个部门的员工个数>5
SELECT department_id,COUNT(*)
FROM employees
GROUP BY department_id
HAVING COUNT(*)>5;
#案例2:查询每个工种有奖金的员工的工种编号和该工种最高工资,且要求的最高工资>12000
SELECT job_id,MAX(salary)
FROM employees
WHERE commission_pct IS NOT NULL
GROUP BY job_id
HAVING MAX(salary)>12000;
分组查询注意:
HAVING 和 WHERE 的差别
WHERE 在数据分组前进行过滤,
HAVING 在数据分组后进行过滤。这是一个重要的区别,
WHERE 排除的行不包括在分组中。
在具体使用 GROUP BY 子句前,需要知道一些重要的规定。
- GROUP BY 子句可以包含任意数目的列。这使得能对分组进行嵌套,为数据分组提供更细致的控制。
- 如果在 GROUP BY 子句中嵌套了分组,数据将在最后规定的分组上进行汇总。换句话说,在建立分组时,指定的所有列都一起计算(所以不能从个别的列取回数据)。
- GROUP BY 子句中列出的每个列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在 SELECT 中使用表达式,则必须在GROUP BY 子句中指定相同的表达式。不能使用别名。
- 除聚集计算语句外, SELECT 语句中的每个列都必须在 GROUP BY 子句中给出。
- 如果分组列中具有 NULL 值,则 NULL 将作为一个分组返回。如果列中有多行 NULL 值,它们将分为一组。
- GROUP BY 子句必须出现在 WHERE 子句之后, ORDER BY 子句之前。
3. 分页查询:limit
注意: limit 是一个MySQL"方言"
-- 语法:limit 开始的行号,每页行数;
-- 默认从第0行开始显示5行
SELECT * FROM student LIMIT 5;
-- 每页显示3条记录
SELECT * FROM student LIMIT 0,3; -- 第1页,从第0行开始显示3行
SELECT * FROM student LIMIT 3,3; -- 第2页,从第3行开始显示3行
SELECT * FROM student LIMIT 6,3; -- 第3页,从第6行开始显示3行
行 0 检索出来的第一行为行0而不是行1。因此, LIMIT 1, 1将检索出第二行而不是第一行。
在行数不够时 LIMIT 中指定要检索的行数为检索的最大行数。如果没有足够的行(例如,给出 LIMIT 10, 5 ,但只有13
行),MySQL将只返回它能返回的那么多行。

4. 排序查询:Order By



重要的是理解在按多个列排序时,排序完全按所规定的顺序进行。
换句话说,对于上述例子中的输出,仅在多个行具有相同的 prod_price
值时才对产品按 prod_name 进行排序。如果 prod_price 列中所有的值都是唯一的,则不会按 prod_name 排序。
指定排序方向
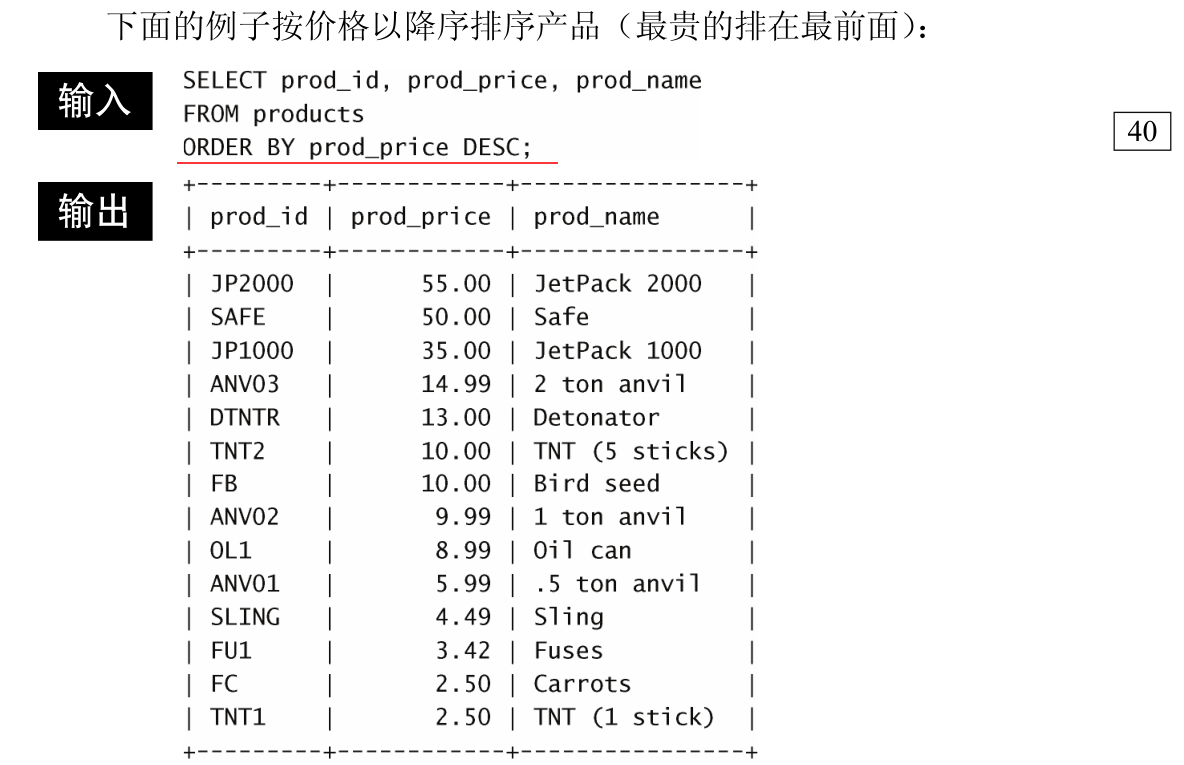
但是,如果打算用多个列排序怎么办?下面的例子以降序排序产品(最贵的在最前面),然后再对产品名排序:
其实是如果 价格相同,再以产品名排序。
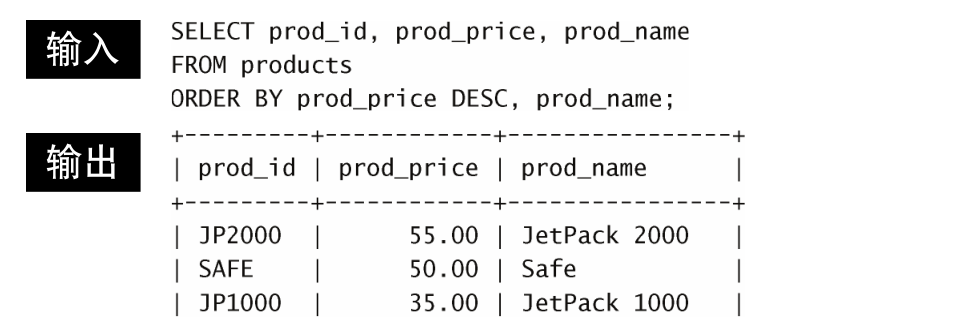
DESC 关键字只应用到直接位于其前面的列名。在上例中,只对prod_price 列指定 DESC ,对 prod_name 列不指定。因此,prod_price 列以降序排序,相同的价格下, prod_name 列仍然按默认的升序排序。
在多个列上降序排序 如果想在多个列上进行降序排序,必须对每个列指定 DESC*关键字。
区分大小写和排序顺序 在对文本性的数据进行排序时,A与a相同吗?a位于B之前还是位于Z之后?这些问题不是理论问题,其答案取决于数据库如何设置
答:默认,A被视为与a相同,这是MySQL和大多数数据库管理系统)的默认行为。但是也可以通过设置改变

注意:ORDER BY 子句的位置 必须保证它位于 FROM 子句之后。如果使用 LIMIT ,它必须位于 ORDER BY之后。
-- 1.排序查询:order by 分组后排序
SELECT * FROM stu ORDER BY math ASC,english ASC;
5. 过滤数据:where

where 子句、与order by子句的位置

where 子句中 AND 与OR 的计算优先级,And优先,所以必要时可以使用小括号
where ,… in
where ,… in ,in操作符的意义其实和 OR 是相同得
IN 在WHERE 子句中用来指定要匹配值的清单的关键字,功能与 OR相当 。

为什么要使用 IN 操作符?其优点具体如下。
- 在使用长的合法选项清单时, IN 操作符的语法更清楚且更直观。
- 在使用 IN 时,计算的 次序更容易管理(因为使用的操作符更少)。
- IN 操作符一般比 OR 操作符清单执行更快。
- IN 的最大优点是可以包含其他 SELECT 语句,使得能够更动态地建立 WHERE 子句。第14章将对此进行详细介绍。
-- 查询年龄不等于20岁
SELECT * FROM student WHERE age != 20;
SELECT * FROM student WHERE age <> 20;
-- 查询年龄大于等于20 小于等于30
SELECT * FROM student WHERE age >= 20 && age <=30;
SELECT * FROM student WHERE age >= 20 AND age <=30;
SELECT * FROM student WHERE age BETWEEN 20 AND 30;--闭区间[20,30]
-- 查询年龄22岁,18岁,25岁的信息
SELECT * FROM student WHERE age = 22 OR age = 18 OR age = 25
SELECT * FROM student WHERE age IN (22,18,25);
-- 查询英语成绩为null
SELECT * FROM student WHERE english = NULL; -- 语法不对的。null值不能使用 = (!=) 判断
SELECT * FROM student WHERE english IS NULL; --正确语法
SELECT * FROM student WHERE english IS NOT NULL; --正确语法
NOT ,经常用在 where 子句条件的取反中
MySQL中的NOT MySQL支持使用 NOT 对 IN 、 BETWEEN 和 EXISTS子句取反,这与多数其他 DBMS允许使用 NOT 对各种条件取反有很大的差别。
LIKE 与通配符
经常用在 where 子句后面,进行数据的模糊过滤
-- 查询姓马的有哪些? like
SELECT * FROM student WHERE NAME LIKE '马%';
-- 查询姓名第二个字是化的人
SELECT * FROM student WHERE NAME LIKE "_化%";
-- 查询姓名是3个字的人
SELECT * FROM student WHERE NAME LIKE '___';
-- 查询姓名中包含德的人
SELECT * FROM student WHERE NAME LIKE '%德%';

正如所见,MySQL的通配符很有用。但这种功能是有代价的:通配符搜索的处理一般要比前面讨论的其他搜索所花时间更长。这里给出一些使用通配符要记住的技巧。
- 不要过度使用通配符。如果其他操作符能达到相同的目的,应该使用其他操作符。
- 在确实需要使用通配符时,除非绝对有必要,否则不要把它们用
- 在搜索模式的开始处。把通配符置于搜索模式的开始处,搜索起来是最慢的。
五、where子句与正则表达式
关键字:regexp
正则表达式的作用是匹配文本,将一个模式(正则表达式)与一个文本串进行比较。其实这种比较与 where Lijke ’通配符‘的形式差不多,两种方式也都可以实现一样效果,但是正则表达式有更加丰富的功能、有的地方也是 LIKE+通配符做不到的。


| :进行OR匹配

[ ] : 集合匹配
匹配任何单一字符。但是,如果你只想匹配特定的字符,怎么办?
可通过指定一组用 [ 和 ] 括起来的字符来完成,如下所示:
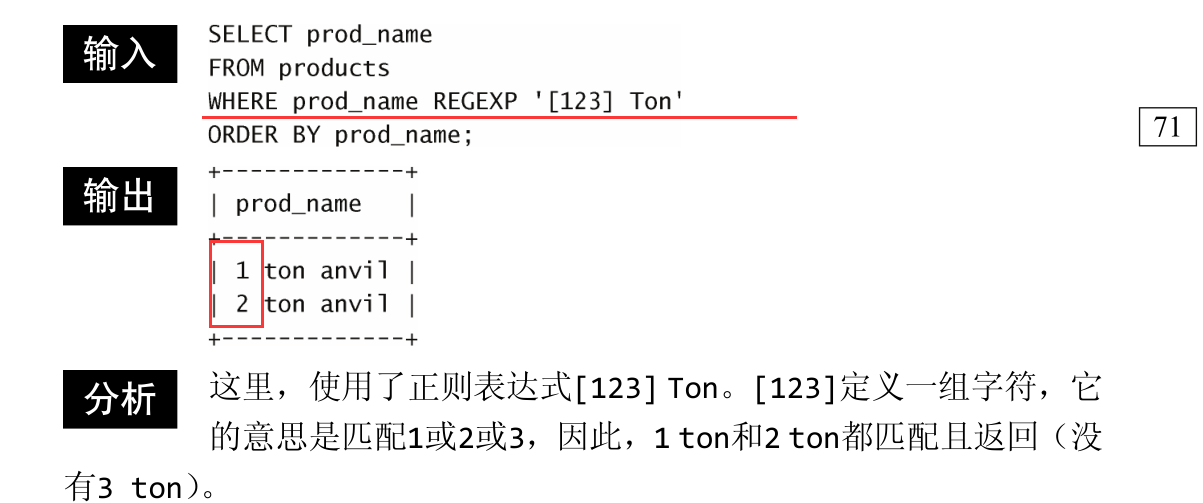
正如所见, [ ] 是另一种形式的 OR 语句。事实上,正则表达式[123]Ton为 [1|2|3]Ton 的缩写,也可以使用后者。但是,需要用 [ ] 来定义 OR 语句查找什么。为更好地理解这一点,请看下面的例子:
1|2|3 Ton 被认为是 1 or 2 or 3 Ton

where id regexp '100|200|300'
where id regexp '[0123456789]' -- 的集合将匹配数字0到9中的一个或多个
where id regexp '[0-9]'
where name regexp '[1-5] ton'
where email regexp '. ton' -- . 表示匹配任意一个值
where email regexp '\\.'
-- 匹配email列值中有 . 字符的数据,\\表示转义,因为 . 有特殊含义是可以匹配任意一个字符
\ \ : 转义字符

[:alnum:] 匹配字符类

[:alnum:] 任意字母和数字(同[a-zA-Z0-9])
[:alpha:] 任意字符(同[a-zA-Z])
[:blank:] 空格和制表(同[\\t])
[:cntrl:] ASCII控制字符(ASCII 0到31和127)
[:digit:] 任意数字(同[0-9])
[:graph:] 与[:print:]相同,但不包括空格
[:lower:] 任意小写字母(同[a-z])
[:print:] 任意可打印字符
[:punct:] 既不在[:alnum:]又不在[:cntrl:]中的任意字符
[:space:] 包括空格在内的任意空白字符(同[\\f\\n\\r\\t\\v])
[:upper:] 任意大写字母(同[A-Z])
[:xdigit:] 任意十六进制数字(同[a-fA-F0-9])
{ } :匹配多个



定位符
目前为止的所有例子都是匹配一个串中任意位置的文本。为了匹配特定位置的文本,需要使用表9-4列出的定位符


总结:


六、 数据约束
什么是约束:对表中的数据进行限定,保证数据的正确性、有效性和完整性。
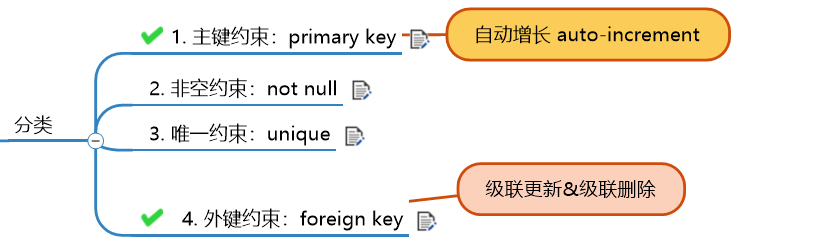
not null:非空约束
-- 创建表时添加约束
CREATE TABLE stu(
id INT,
NAME VARCHAR(20) NOT NULL -- name为非空
);
-- 创建表完后,添加非空约束
ALTER TABLE stu MODIFY NAME VARCHAR(20) NOT NULL;
-- 删除name的非空约束
ALTER TABLE stu MODIFY NAME VARCHAR(20);
unique:唯一约束
注意mysql中,唯一约束限定的列的值可以有多个null
-- 1.创建表时,添加唯一约束 ,表示值不重复
CREATE TABLE stu(
id INT,
phone_number VARCHAR(20) UNIQUE -- 添加了唯一约束
);
-- 2.删除唯一约束, 不能通过MODIFLY删除unique
-- drop index 删除索引的方式
ALTER TABLE stu DROP INDEX phone_number;
-- 3. 在创建表后,添加唯一约束
ALTER TABLE stu MODIFY phone_number VARCHAR(20) UNIQUE;
foreign key:外键约束
-
外键约束:foreign key,让表于表之间的联系关系,从而保证数据的正确性。
-- 1. 创建表时给列名指定外键约束 create table 表名( .... 外键列 constraint 外键名称 foreign key (主表列名称) references 外表名称(列名称) ); -- 2. 删除外键 ALTER TABLE student DROP foreign key fk_courseid; -- 3. 创建表之后,添加外键 ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名称) REFERENCES 主表名称(主表列名称); ALTER TABLE student ADD constraint fk_courseid FOREIGN KEY (stu_courseid) references course(course_id); -- 4. 级联更新:ON UPDATE CASCADE -- 5. 级联删除:ON DELETE CASCADE ALTER TABLE student ADD constraint fk_courseid FOREIGN KEY (stu_courseid) references course(course_id) ON UPDATE CASCADE;