打广告!!!!!!!!!!!!!!!!!!!!!!!!!:
先跟鸡哥打个广告 ,博客地址: https://me.csdn.net/weixin_47482194
写的博客很有水平的,上了几次官网推荐了。

1,正常的print()
2,在遇到FlinkSQL 代码里面有聚合算子的时候,会发现报错了。比如下面的代码:

Exception in thread "main" org.apache.flink.table.api.TableException: AppendStreamTableSink doesn't support consuming update and delete changes which is produced by node Rank(strategy=[UndefinedStrategy], rankType=[ROW_NUMBER], rankRange=[rankStart=1, rankEnd=1], partitionBy=[category], orderBy=[sales DESC], select=[category, sales])
at org.apache.flink.table.planner.plan.optimize.program.FlinkChangelogModeInferenceProgram$SatisfyModifyKindSetTraitVisitor.createNewNode(FlinkChangelogModeInferenceProgram.scala:355)
at org.apache.flink.table.planner.plan.optimize.program.FlinkChangelogModeInferenceProgram$SatisfyModifyKindSetTrai
这是因为Flink SQL不支持直接打印,推荐官网的方法:
public class DistinctTest {
private static final String PRINT_SINK_SQL = "create table sink_print ( \n" +
" sales BIGINT," +
" r_num BIGINT " +
") with ('connector' = 'print' )";
private static final String KAFKA_SQL = "CREATE TABLE t2 (\n" +
" user_id VARCHAR ," +
" item_id VARCHAR," +
" category_id VARCHAR," +
" behavior VARCHAR," +
" proctime TIMESTAMP(3)," +
" ts VARCHAR" +
") WITH (" +
" 'connector' = 'kafka'," +
" 'topic' = 'ods_kafka'," +
" 'properties.bootstrap.servers' = 'localhost:9092'," +
" 'properties.group.id' = 'test1'," +
" 'format' = 'json'," +
" 'scan.startup.mode' = 'earliest-offset'" +
")";
public static void main(String[] args) {
StreamExecutionEnvironment bsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(bsEnv, bsSettings);
bsEnv.enableCheckpointing(5000);
bsEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// tEnv.getConfig().getConfiguration().setBoolean("table.dynamic-table-options.enabled", true);
// 接收来自外部数据源的 DataStream
DataStream<Tuple4<String, String, String, Long>> ds = bsEnv.addSource(new SourceFunction<Tuple4<String, String, String, Long>>() {
@Override
public void run(SourceContext<Tuple4<String, String, String, Long>> out) throws Exception {
Random random = new Random();
while (true) {
int sale = random.nextInt(1000);
out.collect(new Tuple4<>("product_id", "category", "product_name", Long.valueOf(sale)));
Thread.sleep(100L);
}
}
@Override
public void cancel() {
}
});
// 把 DataStream 注册为表,表名是 “ShopSales”
tEnv.createTemporaryView("ShopSales", ds, "product_id, category, product_name, sales");
tEnv.createTemporaryView("aa", ds);
String topSql = "insert into sink_print SELECT * " +
"FROM (" +
" SELECT sales," +
" ROW_NUMBER() OVER (PARTITION BY category ORDER BY sales DESC) as row_num" +
" FROM ShopSales ) " +
"WHERE row_num = 1";
// Table table2 = tEnv.sqlQuery(topSql);
// tEnv.toRetractStream(table2, Row.class).print("########");
tEnv.executeSql(PRINT_SINK_SQL);
tEnv.executeSql(topSql) ;
try {
bsEnv.execute("aaaa");
} catch (Exception e) {
e.printStackTrace();
}
}
}
3,还有就是执行SQL生成table之后转出stream执行:
 注意结尾需要 env.execute();
注意结尾需要 env.execute();
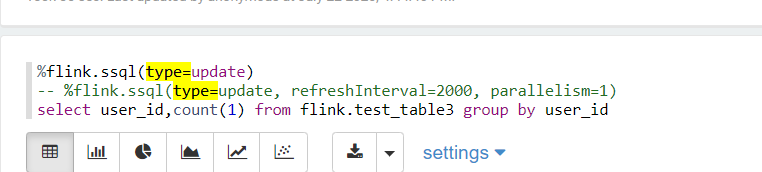
4,在zeppelin执行sql:
添加type =update