Http服务器中包含了http协议、TCP/IP协议,同时该项目又包含了I/O复用技术、多进程多线程、线程池管理以及Linux gdb多线程多进程调试等一系列基本操作,所以通过该项目可以把以上的技术点一一掌握,博主也是本着这样的初心来进行本 HttpServe 的开发设计。
首先,亮出 github地址:https://github.com/GUOQIFU/GuoQi_HttpServe 传送门
首先,分为三大部分:1. Http 报文解析 2. epoll反应堆 3.线程池的设计
1. Http 报文解析
Http报文解析最主要着重在于http协议的请求报文解析,这一点可以基于 tinyhttpd 这一简便精炼的服务解析请求。其大概的流程就是:前期准备工作就是基于TCP/IP协议的 socket 编程基础工作。而后从http请求报文的方法,URL,版本号等字符串解析入手,得到相应的处理方式。当请求为服务器本地的静态文件时,直接发送文件至客户端,如果是动态cgi程序,则 fork 一个父子进程,通过管道处理其通信过程,最后把请求数据发送至客户端。
源码流程图解析,如下:很详细,配合源码很容易懂。流程图太长,字体有点小,但是可以放大慢慢看。
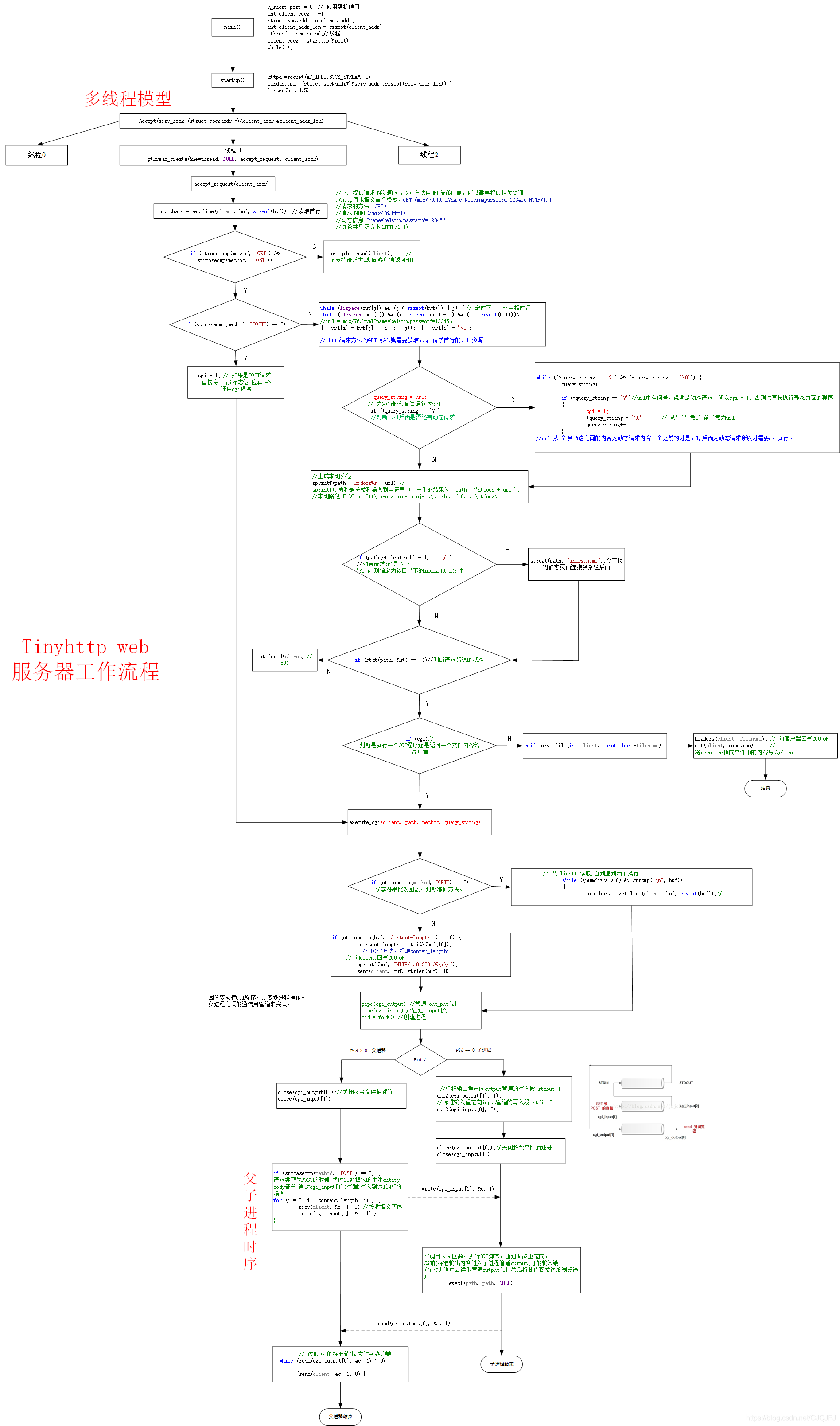
2. epoll反应堆
epoll I/O多路复用主要是为了提高服务器的并发量,在Linux下,2G内存、单核处理器,用 webbench 工具测试表明 tinyhttp能够支持单秒1300左右的并发量,而加载了 epoll 的 tinyhttp 的单秒并发量可以达到 4800 左右。
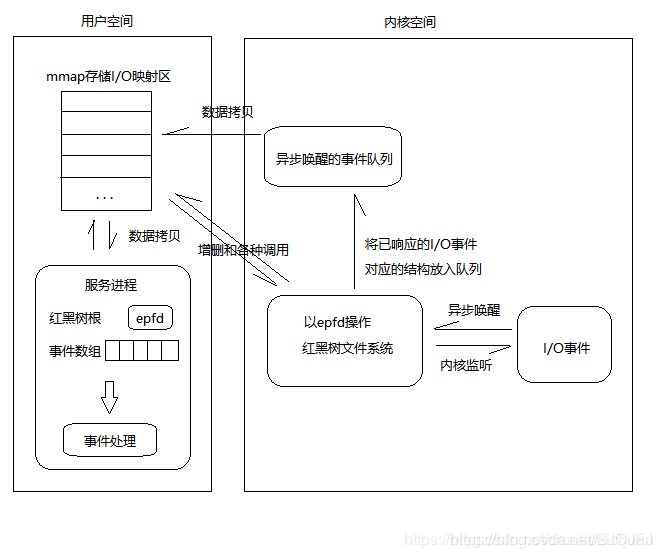
epoll 的文章太多了,这里只做简单介绍:epoll 主要有红黑树、存储响应事件的链表这两种结构。
epoll 利用搜索查询能力极强的红黑树结构存储客户端连接的文件描述符,并利用 epoll 结构体中的回调函数将有事件发生的文件描述符存放进响应数组,以便及时处理。这种反应堆模式又称为同步Reactor 模式,这种模式最大化的利用了内核资源,并将事务分离,著名的事件型驱动库Libevent就是该种模式的代表,其中的核心也是epoll反应堆。
我们在调用epoll_create时,内核除了帮我们在epoll文件系统里建了个file结点,在内核cache里建了个红黑树用于存储以后epoll_ctl传来的socket外,还会再建立一个rdllist双向链表,用于存储准备就绪的事件,当epoll_wait调用时,仅仅观察这个rdllist双向链表里有没有数据即可。有数据就返回,没有数据就sleep,等到timeout时间到后即使链表没数据也返回。所以,epoll_wait非常高效。所有添加到epoll中的事件都会与设备(如网卡)驱动程序建立回调关系,也就是说相应事件的发生时会调用这里的回调方法。这个回调方法在内核中叫做ep_poll_callback,它会把这样的事件放到上面的rdllist双向链表中。
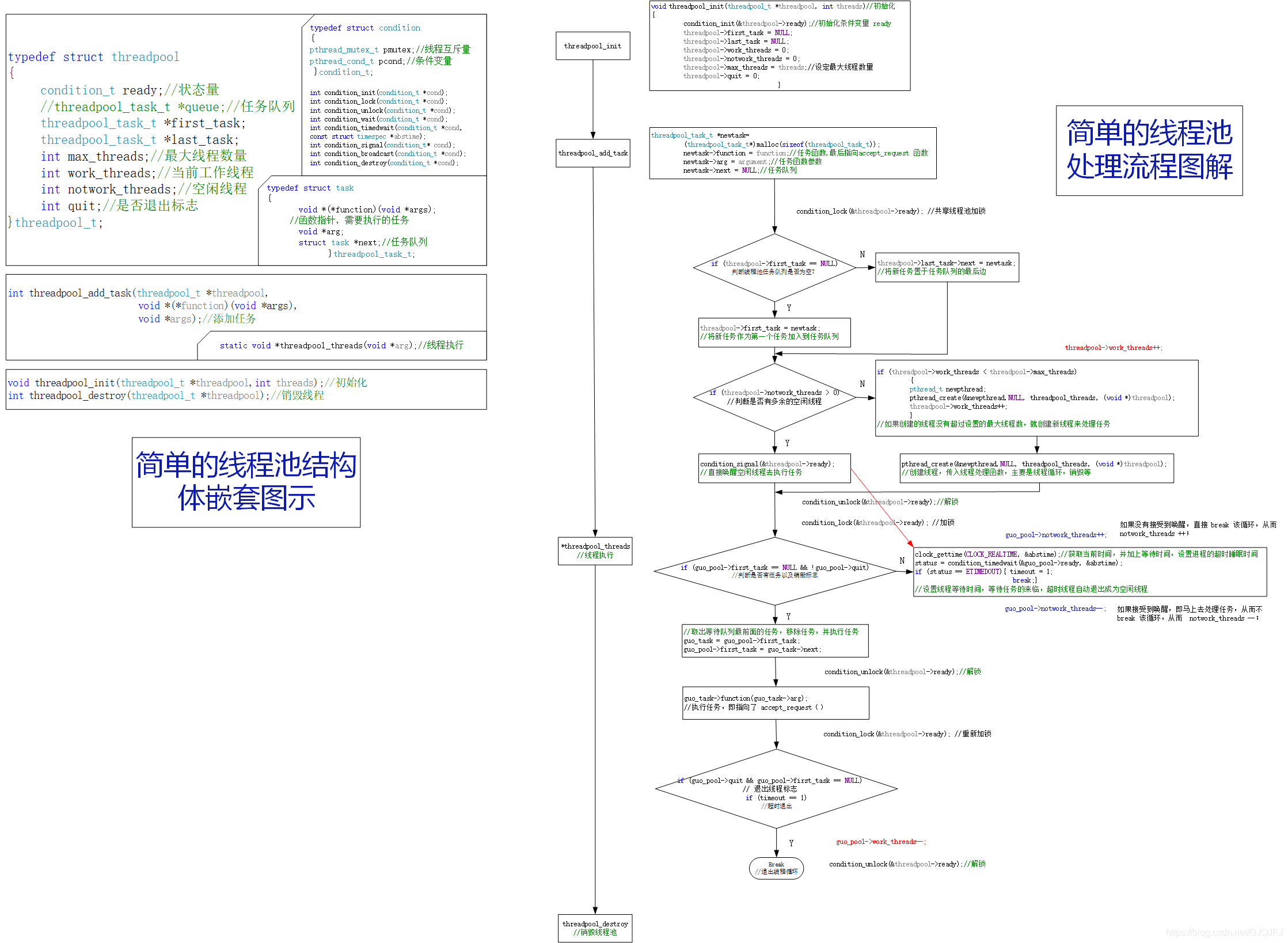
3.线程池的设计
线程池的核心也是 一个 任务队列 和 线程队列,外加线程互斥条件变量,这也是为了保证线程安全。同样,为了更好的理解线程的原理以及处理过程,准备了很清晰很明白的流程原理图,字有点小,还请大家放大仔细看。
最后:测试阶段
项目地址:https://github.com/GUOQIFU/GuoQi_HttpServe 任意门进入
本次对应的是对 tinyhttpd 服务进行更新迭代版本之间的性能对比,主要包括并发量、CPU利用率方面的比较,结果如下:
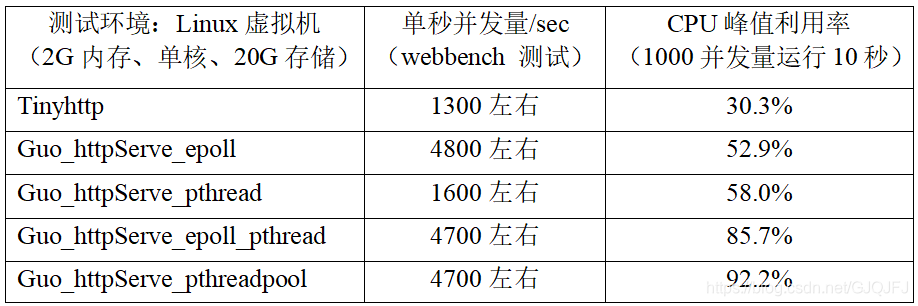
1.tinyhttp:

2.guo_HttpServe_epoll:

3.guo_HttpServe_pthread

3.guo_HttpServe_pthread + epoll:

4.guo_HttpServe_pthreadpool
