导语
pandas不是像list和numpy一样传统的索引,它需要df.函数()来连接
传统的方式适用于单独选取dataframe行或者列。
导入数据:
1 #导入pandas和numpy库 2 import pandas as pd 3 import numpy as np 4 from pandas import Series,DataFrame 5 test=pd.read_excel("/Users/yaozhilin/Downloads/exercise.xlsx",sep="t") 6 test.head(5)#显示前五行
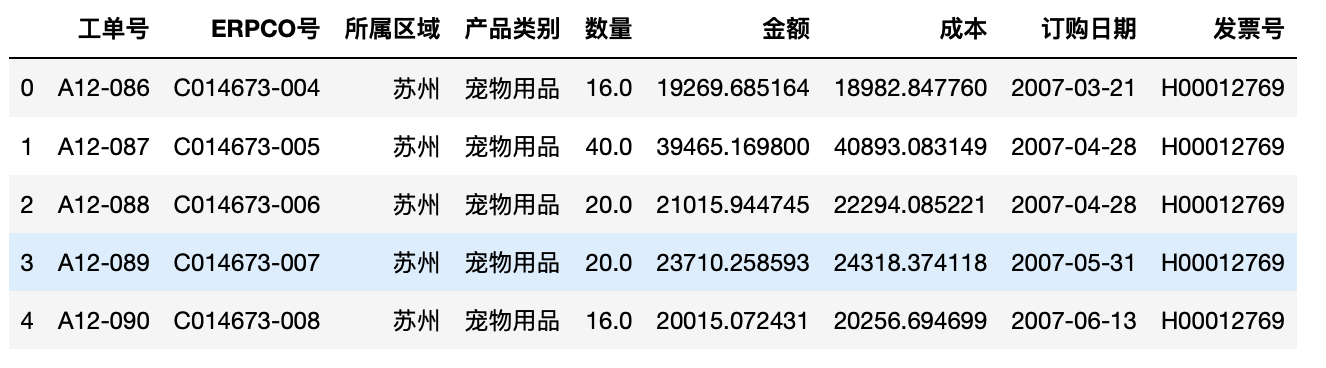
单独选取行或者列
1 test[:2]#选取行

1 test["工单号"].head(3)
0 A12-086 1 A12-087 2 A12-088 Name: 工单号, dtype: object
•loc
基于标签索引
1、行与列的list或者切片选取(.loc[:,[]]或.loc[[],:]等)
2、行的布尔值筛选与列的list或者切片选取进行条件筛选
注:因为基于标签索引,所以索引结果为前闭后闭
~行和列的切片或者[]组合选取
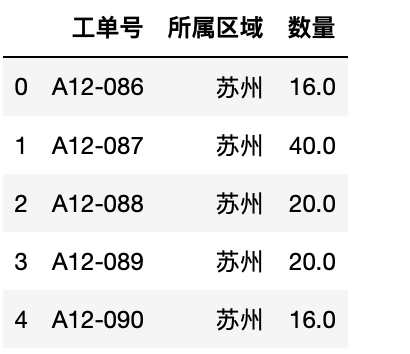
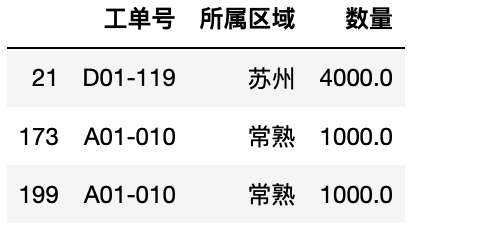
1 test.loc[:4,["工单号","所属区域","数量"]]#行-切片,列-list
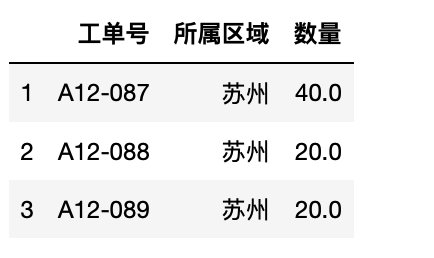
1 test.loc[[1,2,3],["工单号","所属区域","数量"]]#行-list,列-list
~行的布尔值筛选与列的list或者切片选取进行条件筛选
1 test.loc[test["数量"]>=800,["工单号","所属区域","数量"]]#行-布尔值,列-list
•iloc
iloc:基于位置索引 是传统的前闭后开
正常索引与loc一样行和列可以随意切片或者是[]的形式
1 test.iloc[0:3,0:3]

布尔值索引筛选过滤:
因为loc是直接将标签和筛选值连在一起可以直接筛选,而iloc是基于位置的筛选不能直接识别筛选值
1 test["数量"].values#变为数组获取值的位置
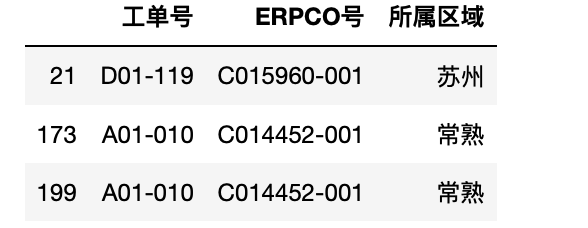
1 test.iloc[test["数量"].values>=800,0:3]
多重索引
构建多重索引:
~set_index、reset_index原表数据构建
test.set_index( keys,drop=True,append=False, inplace=False,verify_integrity=False)
drop表示设置为新索引的列是否保存在原数据
append表示旧的索引是否保存
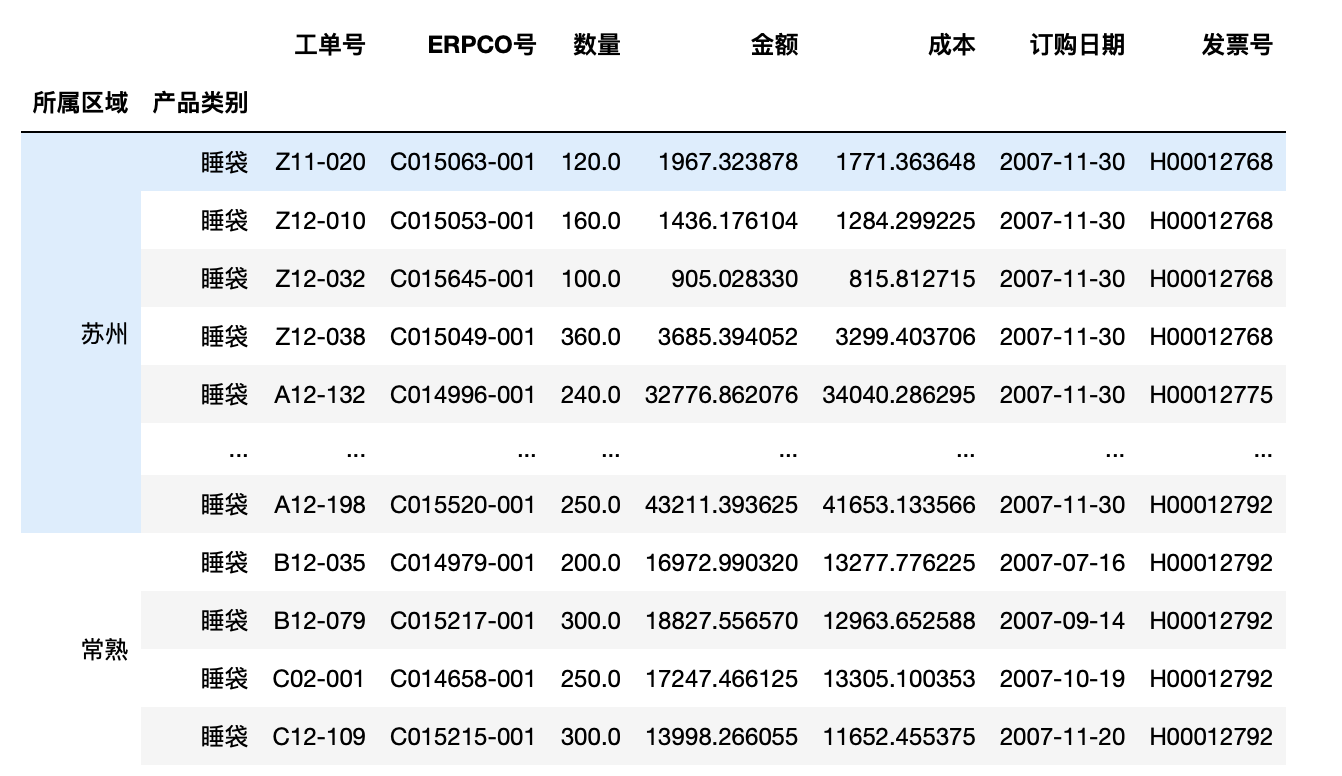
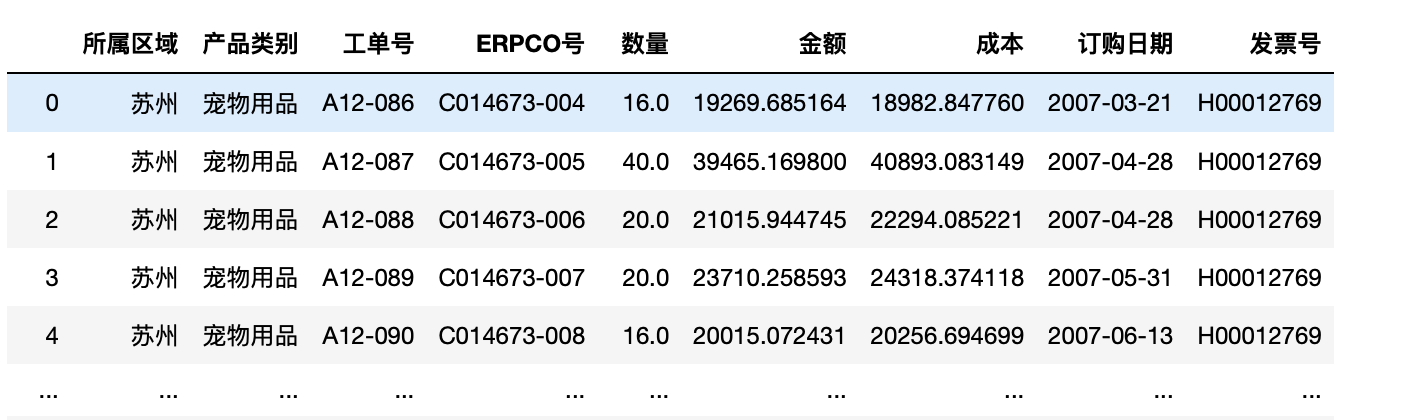
1 test.set_index(["所属区域","产品类别"],drop=True,append=True,inplace=True) 2 test

还原
1 test.set_index(["所属区域","产品类别"],drop=True,append=True,inplace=True) 2 test
~zip创建
pd.MultiIndex.from_tuples、zip的用法:将两集合拆包组成新的配对集合
1 X=[1,2,3,4] 2 Y=['a','b','c','d'] 3 XY=list(zip(X,Y)) 4 print(XY)
[(1, 'a'), (2, 'b'), (3, 'c'), (4, 'd')]
1 z1,z2=zip(*XY)
1 z1
(1, 2, 3, 4)
1 indexs=pd.MultiIndex.from_tuples(XY,names=["first","scend"])
1 df=pd.DataFrame(np.random.randn(4),columns=['A'],index=indexs) 2df

loc常规按顺序索引
1 test.set_index(["所属区域","产品类别"],drop=True,inplace=True) 2 test.loc[("苏州","睡袋"),"数量"]#indexs用(),且不能不写第一索引
所属区域 产品类别
苏州 睡袋 120.0
睡袋 160.0
睡袋 100.0
睡袋 360.0
睡袋 240.0
睡袋 120.0
.....
注:test.loc[(,"睡袋")]
但是直接跳过第一索引会报错
可使用slice切片组合使用,但slice使用过程中所有索引与列均要显示指出
1 test.loc[(slice(None),"睡袋"),:]#冒号不能省略