本文来源没啥特别,因为没使用ip代理导致爬取boos直聘数据时,ip被封了,不过好在已解决,想看看博主的爬虫文章的可以点击下方链接,还是蛮全的。
一、免费代理ip地址推荐
芝麻代理需要注册,但注册后每天可以领取代理,还是很不错的
站大爷和快代理都有免费的开放代理
快代理也可以注册账号,在免费代理页面通过人工客服也可以领取试用独有IP
二、reuqests的ip代理
文章使用 http://httpbin.org/ip 这个测试 HTTP 请求及响应的网站
没使用ip代理之前
import requests
response = requests.get("http://httpbin.org/ip")
print(response.text)

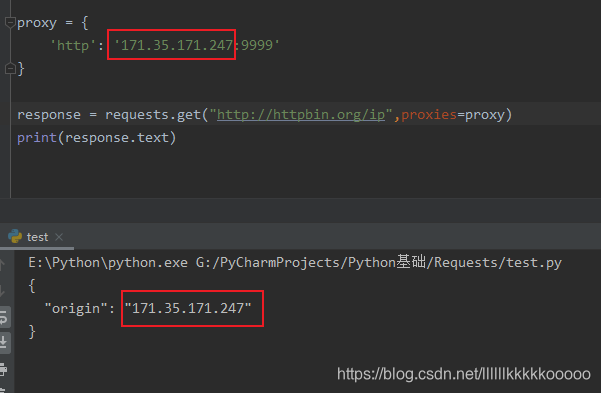
使用ip代理之后
import requests
proxy = {
'http': '171.35.171.247:9999'
}
response = requests.get("http://httpbin.org/ip",proxies=proxy)
print(response.text)
可以看见返回的ip和代理的ip一样
三、selenium的ip代理
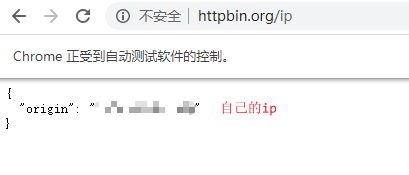
没使用代理之前
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("http://httpbin.org/ip")
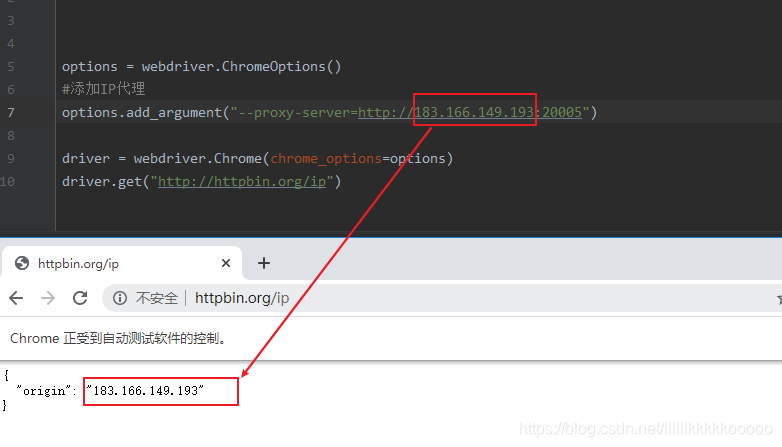
使用代理之后
from selenium import webdriver
options = webdriver.ChromeOptions()
#添加IP代理
options.add_argument("--proxy-server=http://183.166.149.193:20005")
driver = webdriver.Chrome(chrome_options=options)
driver.get("http://httpbin.org/ip")
四、ip代理大坑(重点)
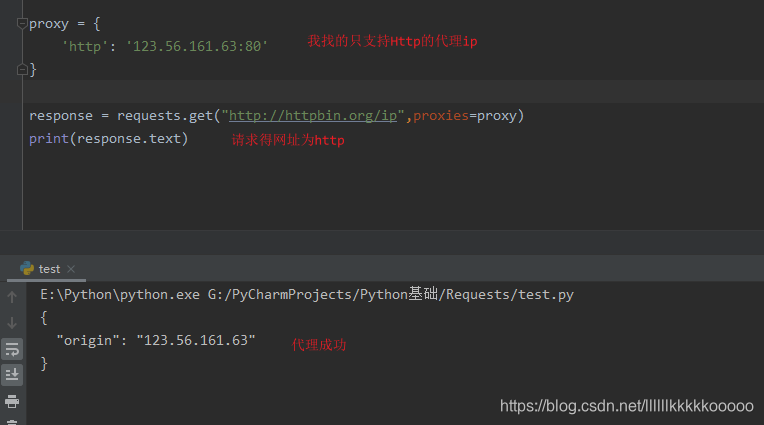
ip代理有http和https的区别,但很多小伙伴不清楚到底有什么区别,经过博主踩坑后终于搞懂了,在线分享给大家
1.
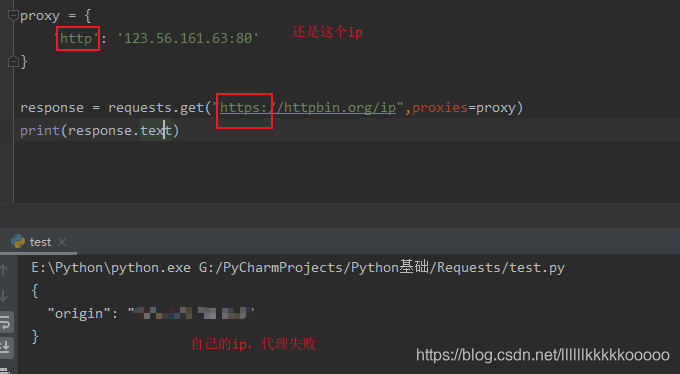
2.
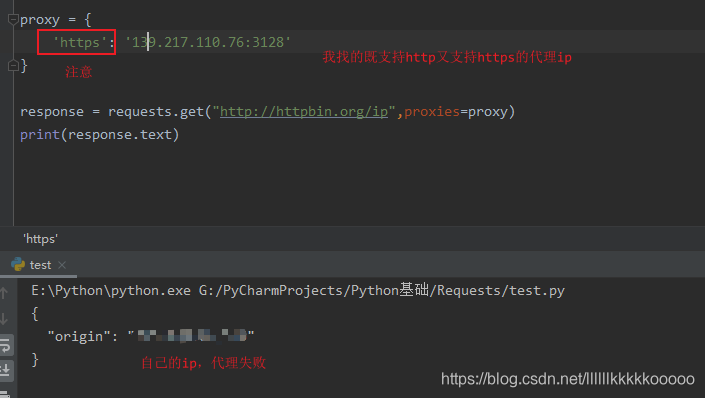
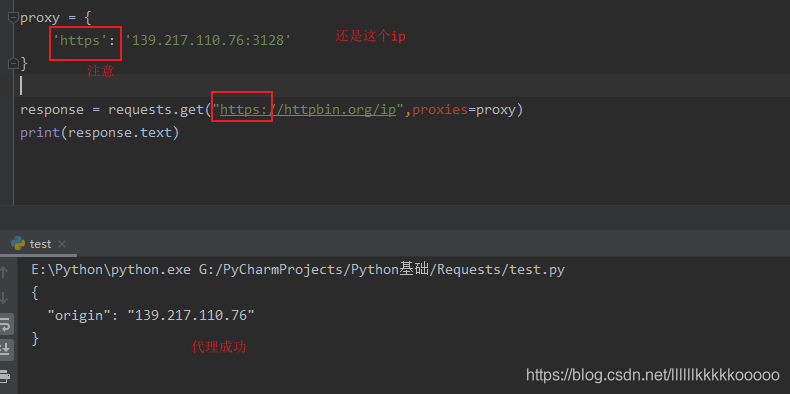
结论:如果请求的ip是https类型的,但代理的ip是只支持http的,那么还是使用本机的ip,
如果请求的ip是http类型的,那么代理的ip一定要是http的,前面不能写成https。
尾声
觉得博主写的不错的读者大大们,可以点赞关注和收藏哦,谢谢各位!