1 Spark基本概念

1.1Spark是什么
Spark使用Scala语言进行实现,它是一种面向对象、函数式编程语言,能够像操作本地集合对象一样轻松地操作分布式数据集(Scala 提供一个称为 Actor 的并行模型,其中Actor通过它的收件箱来发送和接收非同步信息而不是共享数据,该方式被称为:Shared Nothing 模型)。在Spark官网上介绍,它具有运行速度快、易用性好、通用性强和随处运行等特点。
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行计算框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark是Scala编写,方便快速编程。
1.2 Spark产生的技术背景
(1)为什么会有Spark?因为传统的并行计算模型无法有效的解决迭代计算(iterative)和交互式计算(interactive);而Spark的使命便是解决这两个问题,这也是他存在的价值和理由。
(2)Spark如何解决迭代计算?其主要实现思想就是RDD,把所有计算的数据保存在分布式的内存中。迭代计算通常情况下都是对同一个数据集做反复的迭代计算,数据在内存中将大大提升IO操作。这也是Spark涉及的核心:内存计算。
(3)Spark如何实现交互式计算?因为Spark是用scala语言实现的,Spark和scala能够紧密的集成,所以Spark可以完美的运用scala的解释器,使得其中的scala可以向操作本地集合对象一样轻松操作分布式数据集。
(4)Spark和RDD的关系?可以理解为:RDD是一种具有容错性基于内存的集群计算抽象方法,Spark则是这个抽象方法的实现。
粗粒度:表示类别级,即仅考虑对象的类别(the type of object),不考虑对象的某个特 定实例。比如,用户管理中,创建、删除,对所有的用户都一视同仁,并不区分操作的具体对象实例。
细粒度:表示实例级,即需要考虑具体对象的实例(the instance of object),当然,细粒度是在考虑粗粒度的对象类别之后才再考虑特定实例。比如,合同管理中,列表、删除,需要区分该合同实例是否为当前用户所创建。
1.3 Spark的优缺点及与其他技术的对比
1)运行速度快
Spark拥有DAG执行引擎,支持在内存中对数据进行迭代计算。官方提供的数据表明,如果数据由磁盘读取,速度是Hadoop MapReduce的10倍以上,如果数据从内存中读取,速度可以高达100多倍。
2)易用性好
Spark不仅支持Scala编写应用程序,而且支持Java和Python等语言进行编写,特别是Scala是一种高效、可拓展的语言,能够用简洁的代码处理较为复杂的处理工作。
3)通用性强
Spark生态圈即BDAS(伯克利数据分析栈)包含了Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX等组件,这些组件分别处理Spark Core提供内存计算框架、SparkStreaming的实时处理应用、Spark SQL的即席查询、MLlib或MLbase的机器学习和GraphX的图处理,它们都是由AMP实验室提供,能够无缝的集成并提供一站式解决平台。
4)随处运行
Spark具有很强的适应性,能够读取HDFS、Cassandra、HBase、S3和Techyon为持久层读写原生数据,能够以Mesos、YARN和自身携带的Standalone作为资源管理器调度job,来完成Spark应用程序的计算。
Spark与MapReduce的区别
都是分布式计算框架,Spark基于内存,MR基于内存。Spark处理数据的能力一般是MR的十倍以上,Spark中除了基于内存计算外,还有DAG有向无环图来切分任务的执行先后顺序。
1.4 Spark的应用场景
目前大数据处理场景有以下几个类型:
- 复杂的批量处理(Batch Data Processing),偏重点在于处理海量数据的能力,至于处理速度可忍受,通常的时间可能是在数十分钟到数小时;
- 基于历史数据的交互式查询(Interactive Query),通常的时间在数十秒到数十分钟之间
- 基于实时数据流的数据处理(Streaming Data Processing),通常在数百毫秒到数秒之间
目前对以上三种场景需求都有比较成熟的处理框架,第一种情况可以用Hadoop的MapReduce来进行批量海量数据处理,第二种情况可以Impala进行交互式查询,对于第三中情况可以用Storm分布式处理框架处理实时流式数据。以上三者都是比较独立,各自一套维护成本比较高,而Spark的出现能够一站式平台满意以上需求。
通过以上分析,总结Spark场景有以下几个:
lSpark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大,数据量小但是计算密集度较大的场合,受益就相对较小
l由于RDD的特性,Spark不适用那种异步细粒度更新状态的应用,例如web服务的存储或者是增量的web爬虫和索引。就是对于那种增量修改的应用模型不适合
l数据量不是特别大,但是要求实时统计分析需求
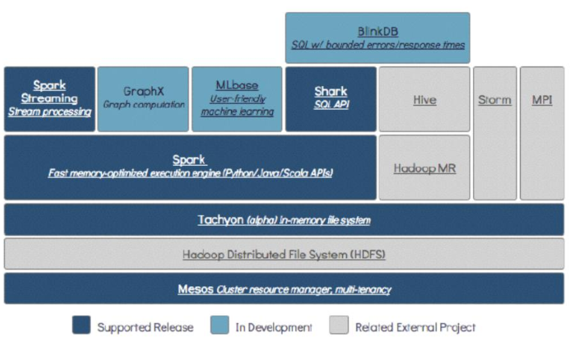
1.5 Spark生态系统
Spark生态圈也称为BDAS(伯克利数据分析栈),是伯克利APMLab实验室打造的,力图在算法(Algorithms)、机器(Machines)、人(People)之间通过大规模集成来展现大数据应用的一个平台。伯克利AMPLab运用大数据、云计算、通信等各种资源以及各种灵活的技术方案,对海量不透明的数据进行甄别并转化为有用的信息,以供人们更好的理解世界。该生态圈已经涉及到机器学习、数据挖掘、数据库、信息检索、自然语言处理和语音识别等多个领域。
Spark生态圈以Spark Core为核心,从HDFS、Amazon S3和HBase等持久层读取数据,以MESS、YARN和自身携带的Standalone为资源管理器调度Job完成Spark应用程序的计算。 这些应用程序可以来自于不同的组件,如Spark Shell/Spark Submit的批处理、Spark Streaming的实时处理应用、Spark SQL的即席查询、BlinkDB的权衡查询、MLlib/MLbase的机器学习、GraphX的图处理和SparkR的数学计算等等。
1.6 Spark运行模式
Local
多用于本地测试,如在eclipse,idea中写程序测试等。
Standalone
Standalone是Spark自带的一个资源调度框架,它支持完全分布式。
Yarn
Hadoop生态圈里面的一个资源调度框架,Spark也是可以基于Yarn来计算的。
Mesos
资源调度框架。
要基于Yarn来进行资源调度,必须实现AppalicationMaster接口,Spark实现了这个接口,所以可以基于Yarn。
2 Spark环境搭建
standalone模式搭建
1、检查基础环境是否满足,如jdk版本等
本文所述,均是建立在VMware搭建的虚拟机环境中,其实生产环境也是一致的。搭建虚拟机安装hadoop等过程,请参见本博客相关博文(还呆在草稿箱中,尚未发布。。。)
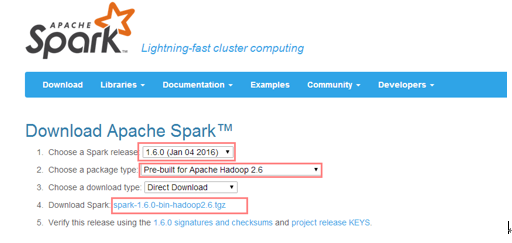
2、下载安装包,解压 以1.6.0为例
此处改了个名,改不改无所谓,随意。
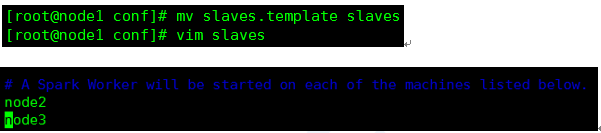
3、修改conf目录下的slaves.template文件,添加从节点
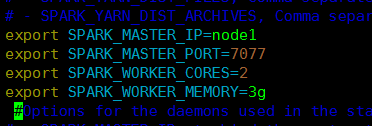
4、修改spark-env.sh,并同步到其他节点
SPARK_MASTER_IP:master的ip
SPARK_MASTER_PORT:提交任务的端口,默认是7077
SPARK_WORKER_CORES:每个worker从节点能够支配的core的个数
SPARK_WORKER_MEMORY:每个worker从节点能够支配的内存数
5、启动集群
进入sbin目录下,执行当前目录下的./start-all.sh
6、搭建客户端
将spark安装包原封不动的拷贝到一个新的节点上,然后,在新的节点上提交任务即可。
注意:
8080是Spark WEBUI界面的端口,7077是Spark任务提交的端口。
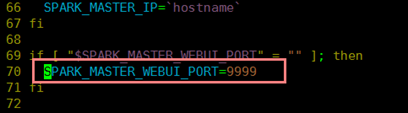
修改master的WEBUI端口:
修改start-master.sh即可。(随意)
也可以在Master节点上导入临时环境变量,只是作用于之后的程序,重启就无效了。
删除临时环境变量:





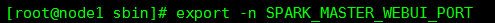
yarn模式搭建
1、2、3、4、5、6步同standalone,
接下来在客户端中配置
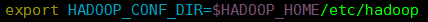
CDH安装
真爽,直接点和选就可以了。可一套直接将全套大数据框架全部安装完毕。此处因为没有环境就不提供了,可参加官方文档。
测试是否成功
计算圆周率π
standalone模式提交
./spark-submit \
--master spark://node1:7077 \
--class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 10000
yarn提交
./spark-submit \
--master yarn \
--class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 10000