文章目录
综合笔记











1.安装mysql客户端流程:
-
登录navicat官网下载
-
将压缩包拷贝ubuntu中进行解压,解压命令:tar zxvf navicat.tar.gz

-
进入解压目录,运行命令./start_navicatt


-
如果试用是灰色的则进行下一步
-
删除 .navicat64/ 隐藏文件,再次运行即可


-
如果试用界面是乱码的则修改配置文件,改成如下形式(vim常用操作请查看我的另一篇随记):


-
再次执行第三步操作即可,试用到期可再次删除那个隐藏文件
2.ubuntu下安装mysql服务端
- sudo apt-get install mysql-server
3.验证安装结果
- 命令:ps aux|grep mysql,跟下图一样则说明安装成功

4.mysql数据库运行状态
4.1 sudo service mysql status 查看数据库运行状态
-
绿点 正在运行

-
白点 停止运行
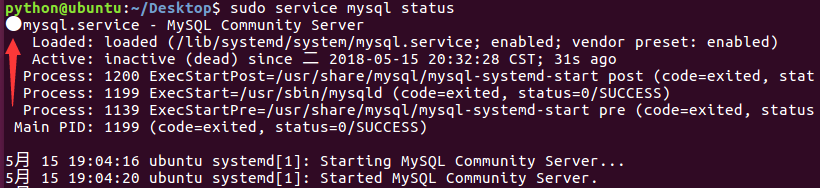
4.2 sudo service mysql start 启动数据库服务

4.3 sudo service mysql stop 停止数据库服务

- 4.4 sudo service mysql restart 重启数据库服务

5. 登录数据库
5.1 通过客户端软件登录,详见步骤1
5.2 通过命令登录
- 登录远程主机:mysql [-h 192.168.205.129 –P 3306] –uroot -p
- h 连接服务端数据库的IP地址
- P(大写) 连接的端口号,一般为3306
- u 用户权限 - p(小写) 输入密码,一般为mysql
登陆成功:

6. 退出数据库客户端
- exit、quit、ctrl+d
7. 配置msyql服务允许远程登录访问
7.1 数据文件夹:

7.2 数据库配置文件:

7.3 关闭防火墙
- sudo apt-get install ufw 安装防火墙
- sudo ufw enable 打开防火墙
- sudo ufw status 查看防火墙状态
- sudo ufw disable 关闭防火墙
7.4 更改配置文件的bind-address
-
进入配置文件

-
修改mysqld.cnf中的bind-addres,首先给用户可执行权限

-
再次使用vim修改bind-address

-
修改成功
-
再把文件权限改回去

7.5 修改权限
- 权限 update
userset host=”%” where user=”root” - 允许指定用户访问:
GRANT ALL PRIVILEGES ON . TO ‘root’@‘10.10.11.12’ IDENTIFIED BY ‘FEFJay’ WITH GRANT OPTION; flush privileges;(IP这里,可以使用%来表示所有IP) - 重启服务即可
8. 创建数据库
8.1 使用客户端软件创建数据库
8.2 使用命令创建数据库
- create database 数据库名
- create database 数据库名 character set utf8
- show create database 数据库名
8.3 修改数据库编码
- alter database 数据库名 character set utf8
8.4 删除数据库
- drop database 数据库名
8.5 切换、使用数据库
- use 数据库名
8.6 显示当前数据库
- select database()
8.7 展示所有数据库
- show databases
9. 创建数据表
9.1 使用命令创建数据表
- create table 表名
(
字段1 字段类型,
字段2 字段类型,
字段3 字段类型……
)
9.2 常用数据字段类型
-
整数

-
小数

-
字符串

-
日期时间类型


-
枚举
10.查询
10.1 查询数据表中全部的行和列
- select col1,col2,col3….from table
- select * from table
10.2 查询表的部分列
- select col1,col2,col3…from table
10.3 给查询出来的数据列设置别名
- select col1 as “别名1”,col2 as ‘别名2’…from table
- select col1 ‘别名1’,col2 ‘别名2’….from table
- 注意多表查询重名问题
10.4 DISTINCT关键字的使用
-
作用:消除结果集中的重复数据
-
语法:select distinct col from table
-
注意:要求所有的字段都相同才会去重
10.5 LIMIT关键字的使用
- 作用:指定结果的显示范围
- 语法:
- select * from table limit m,n
m:起始的位置
n:显示的数量
- select * from table limit m
m:从第一条开始共显示m条数据
11. 插入数据
11.1 所有列都插入值
- 语法:insert into table values(v1,v2,v3….)
- 特点:列值同数,列值同序
11.2 为指定列插入值
- 语法:insert into table(col1,col2,col3) values(v1,v2,v3)
- 特点:指定顺序,列值对应
11.3 一次性插入多条记录
- 语法:insert into table(co1,col2,col3…)values
(v1,v2,v3),
(v1,v2,v3),
(v1,v3,v3)……
12.修改数据
12.1 修改指定数据
- 语法:update table set {col1=value1}[…n]where expressioin
12.2 修改全部数据
- 语法:update table set {col1=value1}[…n]
13. 删除数据
13.1 使用delete命令删除数据
- 语法:delete from table where expression
13.2 逻辑删除
13.3 使用truncate命令删除数据
- truncate table
13.4 区别
- Delete语句删除数据,自动编号没有恢复到默认值。但是truncate重新设置了自动编号
- 通过truncate语句删除数据表数据,不能根据条件删除,而是一次性删除,delete语句可以根据条件进行删除
- truncate在清空表中数据的时候,速度要比delete语句快的多
14. 对列进行增删改查
14.1 增加一列
- alter table tablename add 列名 数据类型
14.2 删除一列
- alter table tablename drop column 列名
14.3 修改列的数据类型
- alter table tablename modify 列名 数据类型
14.4 修改列的数据类型并且改名
- alter table tablename change old_colname new_colname 数据类型
15. 约束
-
问题1:数据冗余

-
问题2:失去了完整性

-
问题3:数据缺少唯一标识

-
问题4:失去了实体完整性

-
问题5:失去了引用完整性

-
问题6:失去了域完整性

15.1 约束概念:限定数据库中数据的一套规则
15.2 约束作用:保证数据的准确性、完整性、可靠性、联动性
15.3 数据库常用约束:
-
主键约束
- 作用:让数据具有唯一标识
- 语法:
create table table_primarykey
(
id int primary key
) - 特点:自动设置非空约束
-
自动增长
- 作用:使数据自动增长,一般给主键设置
- 语法:
create table table_autoincrement
(
id int primary key auto_increment
)
-
唯一约束
- 作用:保证数据的准确性
- 语法:
create table table_unique
(
qqnumber int unique
) - 特点:可以为多列设置唯一约束
-
非空约束
- 作用:保证数据不为空
- 语法:
create table table_notnull
(
name varchar(30) not null
)
-
默认约束
- 作用:给字段设置默认值
- 语法:
create table table_default (
sex char(2) default ‘男’
)
-
检查约束
- 作用:检查数据的完整性
- 语法:
create table table_check (
sex char(2) check(‘男’ or ‘女’) )
create table table_enum ( sex enum(‘男’,’女’) )
-
外键约束
- 作用:让两表之间产生联动关系
- 语法:
create table class(
id int primary key auto_increment,classname varchar(30) not null)
create table score ( id int primary key auto_increment, chinese_score int not null, foreign key(id) references class(id) )
-
要想删除class表和score表,首先要删除score表
16. 为数据增补约束
16.1 添加/删除主键约束
- 添加主键约束
- 语法:alter table table_name add constrain con_name primary key(col_name)
- 删除主键约束
16.2 外键约束
- 添加外键约束
- 语法:alter table table_name add constrain con_name foreign key(col_name) references table(col_name)
- 删除外键约束
16.3 检查约束
- 添加检查约束
- 语法:alter table table_name add constraint con_name check(expression)
- 删除检查约束
16.4 默认约束
- 添加默认约束
- 语法:alter table table_name alter col_name default value
- 删除默认约束
16.5 自动增长
- 添加自动增长
- 语法:alter table table_name modify column col_name type auto_increment
- 删除自动增长
17. 条件查询
17.1 普通条件查询
- 语法:select * from table where expression
- where:将查询到的数据,通过where后的expression一条一条的进行筛选,符合要求则显示,不符合要求则去除。


17.2 模糊查询 - 语法:
- between….and….
- 范围查询 in 、or
- like 通配符 %和_
17.3 查询空值的运算符
- is null
18. 数据排序
- 作用:对查询出的数据进行升序或降序排列
- 语法:select col11,col2,col3…from table order by order_by_collist[asc/desc]
18.1 多列排序:
- 关注点:升序、降序、优先级

19. 数据分组
- 语法:select col1…col2… from table Group by col分组配合排序
- 注意:如果使用了group by分组,那么select不允许出现其他列,除非这些列包含在分组中
20. 聚合函数
- 作用:对多条数据做统计功能
- 注意:在使用聚合函数后,select后不允许出现其他列,除非这些列包含在分组中或者聚合函数中

20.1 常用聚合函数

20.2 聚合函数与Group by语句配合使用

- Having by语句
- 作用:having by为group by之后得到数据进行进一步的筛选
- 类似于select 和 where的关系。Where为select后的数据进行进一步的筛选。
- Having by 为group by后的数据进行筛选
- Limit关键字的使用
- 语法:
select * from table limit m
select * from table limit m,n
- sql语句执行顺序
— from 表名
— where
— group by
— select distinct *
— having
— order by
— limit - 连接查询
- 当查询结果的数据来自多张表的时候,需要将多张表连接成一个大的数据集,再选择合适的列进行返回。
24.1 内连接:选择两种表中交叉的数据进行返回

24.2 左连接:选择左表全部数据以及右边中和左表相同的数据

24.3 右连接:选择右表全部数据以及左表中和右表相同的数据

24.4 笛卡尔积:两张表数据行的乘积
25. 自关联
- 概念:让某张表自己和自己进行连接。
26. 子查询
- 概念:将一个查询结果在另一个查询中使用,称之为子查询。
- 语法:select * from (select col1,col2,col3 from table) as t
26.1 子查询分类
- 独立子查询:
- 子查询可以独立运行
- 相关子查询:
- 子查询中引用了父查询的结果或者父查询中引用了子查询的结果,子查询和父查询都不可以独立运行
26.2 子查询注意点:
- 如果主查询使用到子查询的数据,则必须给子查询起一个表名。
- 在子查询使用关系运算符的时候要注意,因为子查询有可能返回多个值。
!每行命令必须以分号(;)结尾
先通过命令行进入数据库客户端
mysql -h服务端ip地址 -P(大写)服务端使用的端口,一般为3306 -p(小写)
回车之后输入密码,进入
显示所有数据库
show databases;
创建数据库并设置编码:
- 数据库创建时可以设置字符集以及排序规则
- 字符集一般使用utf8的,排序规则一般使用忽略大小写的,其实也不能说是忽略大小写
- 它的原理是放进数据库的都转换成大写,然后不管用户输入的大写还是小写都转换成大写再去数据库里查
- 所以看起来就相当于是忽略了大小写
- 如果不设置中文会乱码
create database 数据库名字 character set utf8;
create database 数据库名字 charset=utf8;
修改数据库编码
alter database 数据库名字 character set utf8;
展示创建数据库的过程
show create database 数据库名字;
使用某个数据库
use 数据库名字;
判断当前在哪个数据库里
select database();
查看该数据库有哪些表
show tables;
创建数据库中的表
create table 表的名字(
字段名字 类型(范围) [约束],
字段名字 类型(范围) [约束],
字段名字 类型(范围) [约束]);
查看某表的字段(属性)
desc 表的名字;
show create table 表的名字;
往表中添加字段
alter table 表的名字 add 字段名字 类型(范围) [约束];
修改表字段类型
alter table 表名字 modify 字段名字 新类型(范围) [约束];
修改表字段的名字和类型
alter table 表名字 change 旧的字段名字 新的字段名字 新类型(范围) [约束];
给表中的字段添加约束
主键,外键,检查,唯一四个约束要用add constraint,其他的约束可以用modify
alter table 表的名字 add constraint 起个名字(随意) 约束(字段名字);
往表中添加数据
insert into 表的名字(字段名字) values(要添加的数据);
查询表中的数据
select * from 表的名字;
根据范围查询表里的数据
select * from table limit m,n;
- 显示范围是:[m+1行,m+n行],包括m+1和m+n行
根据字段查询表里的数据
select 字段名字1,字段名字2 from 表的名字;
给从表里查询出来的数据的字段取别名
select 字段名字1 as 要取的别名,字段名字2 as 要取的别名 from 表的名字;
根据字段查询表里的数据(去重)
select distinct 字段名字 from 表的名字;
根据条件查询表里的数据(条件可使用not,!=,or,in(值1,值2…),and,between…and…)
select * from 表的名字 where 条件;
模糊查询表里的数据
在根据条件查询的条件中使用like和通配符%(任意字符),_(一个字符)
查询表里的某字段为NULL的值条件必须用is null,不能用= null
对表里的数据排序(先按字段1排,有相同的则再按字段2排)
select * from 表的名字 order by 字段名字1 asc(默认升序)/desc(降序),字段名字2 asc(默认升序)/desc(降序);
修改表中某字段的所有数据
update 要修改的表的名字 set 要修改的字段 = 修改后的内容;
修改表中某字段的指定数据(where 后面是查找条件)
update 要修改的表的名字 set 要修改的字段 = 修改后的内容 where 字段 = 内容;
删除表中的一个字段(这里要注意不能全删光)
alter table 表的名字 drop column 字段名字;
删除表中的数据
truncate 表的名字; (后面不能跟where)
delete from 表的名字;
delete from 表的名字 where 字段名字 = 内容;
删除数据库/表
drop database/table 存在的数据库名字/表的名字;
清屏
system clear
导入导出数据库
导出(终端中): mysqldump -uroot -p 存在的要导出的数据库的名字 > 要导出位置的绝对路径/新名字.sql
导入(终端中): mysql -uroot -p 新数据库的名字 < 路径/要导入的数据库名字.sql
导入(客户端中):
- 先建一个新的数据库,名字随意
- use 这个空的数据库
- source 写要导入的.sql文件的绝对路径
约束
两种添加的时机:1. 建表的时候 2. alter 添加约束
演示代码(不想打的可以直接复制,我写全了,不过代码里也有会报错的地方,认真看错误的原因才能理解的更深):
主键约束(自带唯一约束):
create database yueshu character set utf8;
use yueshu;
show tables;
create table tbl_PK(
id int unsigned(无符号) primary key auto_increment(自动增长),(顺序不能错)
name varchar(30));
insert tbl_PK values(1,‘张三’),(2,‘李四’),(3,‘王五’);
select * from tbl_PK;
insert tbl_PK values(0,‘张三’),(0,‘李四’),(0,‘王五’);
唯一约束:
create table tbl_UQ(
id int unsigned primary key auto_increment,
card_id varchar(18) unique);
insert into tbl_UQ values(0,‘123123’);
select * from tbl_UQ;
insert into tbl_UQ values(0,‘123123’);
insert into tbl_UQ values(0,‘123123321’);
select * from tbl_UQ;
非空约束:
create table tbl_NN(
id int unsigned primary key auto_increment,
name varchar(10) not null);
alter table tbl_NN add age int unsigned;
desc tbl_NN;
insert into tbl_NN values(0, ‘张三’);
insert into tbl_NN(id,name) values(0, ‘张三’);
select * from tbl_NN;
insert into tbl_NN(id,age) values(0, 18);
默认约束:
create table tbl_Default(
id int unsigned primary key auto_increment,
gender char(2) not null default ‘男’);
alter table tbl_Default add name varchar(30);
insert into tbl_Default(id, name) values(0,‘张三’);
select * from tbl_Default;
检查约束:(MySQL中不起作用)
create table tbl_Check(
id int,
age int check ( age > 0 and age < 120),
gender char(2) check (‘男’ or ‘女’));
insert into tbl_Check values(0, 180, ‘中性’);
select * from tbl_Check;
外键约束:
create table Employees(
EmpId int unsigned primary key auto_increment,
EmpName varchar(50),
EmpGender char(2),
EmpAge int,
EmpEmail varchar(100),
EmpAddress varchar(500)
DeptId int);
create table Department(
DepId int unsigned primary key auto_increment,
DepName varchar(50));
alter table Employees add constraint FK_DeptId_DepId foreign key(DeptId) references Department(DepId);
外键必须和主键关联
insert into Department values(0,‘一部门’),(0,‘二部门’);
select * from Department;
insert into Employees(EmpId,DeptId) values(0,1);
select * from Employees;
insert into Employees(EmpId,DeptId) values(0,3);
drop table Department;
drop table Employees;
drop table Department;
聚合函数(聚合函数不计算null值)
- 对多条数据进行统计
把某字段中的数据分组
select 字段名字1 from 表的名字 group by 字段名字1;
根据某字段(字段名字1)分组,显示其它字段(字段名字2)成分
select 字段名字1,group_concat(字段名字2) from 表的名字 group by 字段名字1;
求和
select sum(字段名字) as ‘别名’ from 表的名字;
求最大
select max(字段名字) as ‘别名’ from 表的名字;
求最小
select min(字段名字) as ‘别名’ from 表的名字;
求平均
select avg(字段名字) as ‘别名’ from 表的名字;
求某字段所含数据的总个数(不算null那一行)
select count(字段名字) as ‘别名’ from 表的名字;
分组之后显示每组的数据个数
select 字段名字1,count(*) from 表的名字 group by 字段名字1;
保留小数指定位数
select round(那个小数,保留的位数) from 表的名字;
having 对分组之后的数据进行进一步的筛选
类似于 select 和 where 之间的关系
select 字段名字1 from 表的名字 group by 字段名字1 having 条件;
多表查询
- 尽量避免多表查询
- 多表查询会出现笛卡尔积
内连接,满足条件显示(还是会产生笛卡尔积,只是用on进行了条件筛选)
select * from 表1的名字 inner join 表2的名字 on 表1的名字.字段的名字 = 表2的名字.字段的名字;
左连接,以表1为基础,表1全显示,表2不够的用null补全
select * from 表1的名字 left join 表2的名字 on 表1的名字.字段的名字 = 表2的名字.字段的名字;
右连接,以表2为基础,表2全显示,表1不够的用null补全
select * from 表1的名字 right join 表2的名字 on 表1的名字.字段的名字 = 表2的名字.字段的名字;
自关联
- 让表自己和自己进行连接
- 表中的某一列关联了表中的另外一列,但是他们的业务含义是不一样的
select * from 表的名字 inner join 表的名字 on 表的名字.字段的名字 = 表的名字.字段的名字;
代码示例:
Create table areas
(
id int,
atitle varchar(100),
pid int
)
如:
id 编号 pid 上级编号
id atitle pid
1 河北省 null
2 石家庄 1
3 平山县 2
子查询
select * from 表1的名字 where 字段1的名字=(select 字段2的名字 from 表2的名字 where 条件)
执行顺序:
1—from 表名
2—where
3—group by
4—select distinct *
5—having
6—order by
7—limit
注意事项:
enum ,添加数据的时候是从1开始的不是从0开始的 ,比如enum(‘男’,‘女’)-----1是男,2是女,以此类推
https://www.cnblogs.com/ln-supergood/p/9325461.html