12.1. GIL(全局解释器锁)
GIL面试题如下
描述Python GIL的概念, 以及它对python多线程的影响?编写一个多线程抓取网页的程序,并阐明多线程抓取程序是否可比单线程性能有提升,并解释原因。
Guido的声明:http://www.artima.com/forums/flat.jsp?forum=106&thread=214235
he language doesn’t require the GIL – it’s only the CPython virtual machine that has historically been unable to shed it.
参考答案:
Python语言和GIL没有半毛钱关系。仅仅是由于历史原因在Cpython虚拟机(解释器),难以移除GIL。
GIL:全局解释器锁。每个线程在执行的过程都需要先获取GIL,保证同一时刻只有一个线程可以执行代码。
线程释放GIL锁的情况: 在IO操作等可能会引起阻塞的system call之前,可以暂时释放GIL,但在执行完毕后,必须重新获取GIL Python 3.x使用计时器(执行时间达到阈值后,当前线程释放GIL)或Python 2.x,tickets计数达到100
Python使用多进程是可以利用多核的CPU资源的。
多线程爬取比单线程性能有提升,因为遇到IO阻塞会自动释放GIL锁
12.2. 深拷贝、浅拷贝
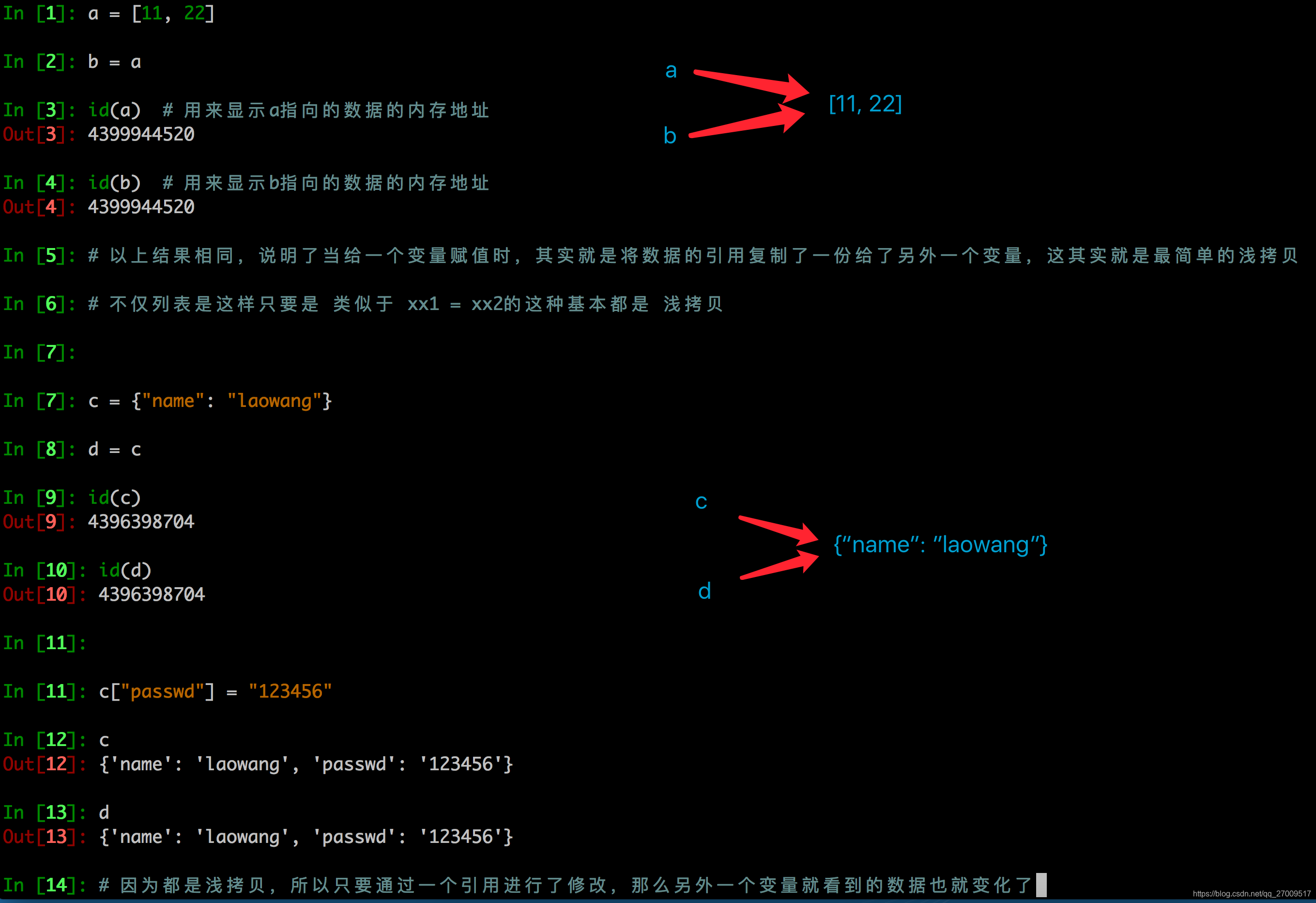
1. 浅拷贝
浅拷贝是对于一个对象的顶层拷贝
通俗的理解是:拷贝了引用,并没有拷贝内容

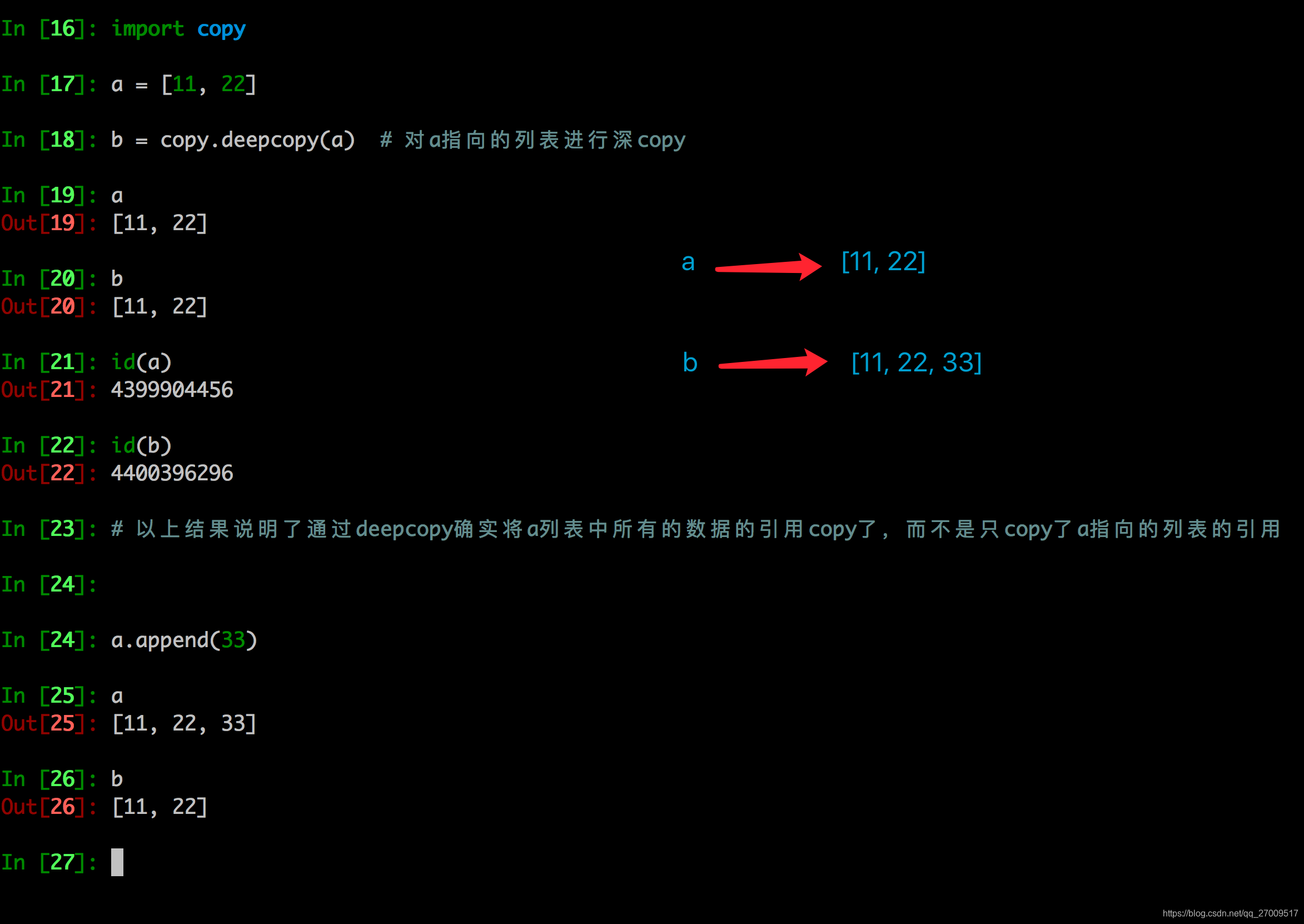
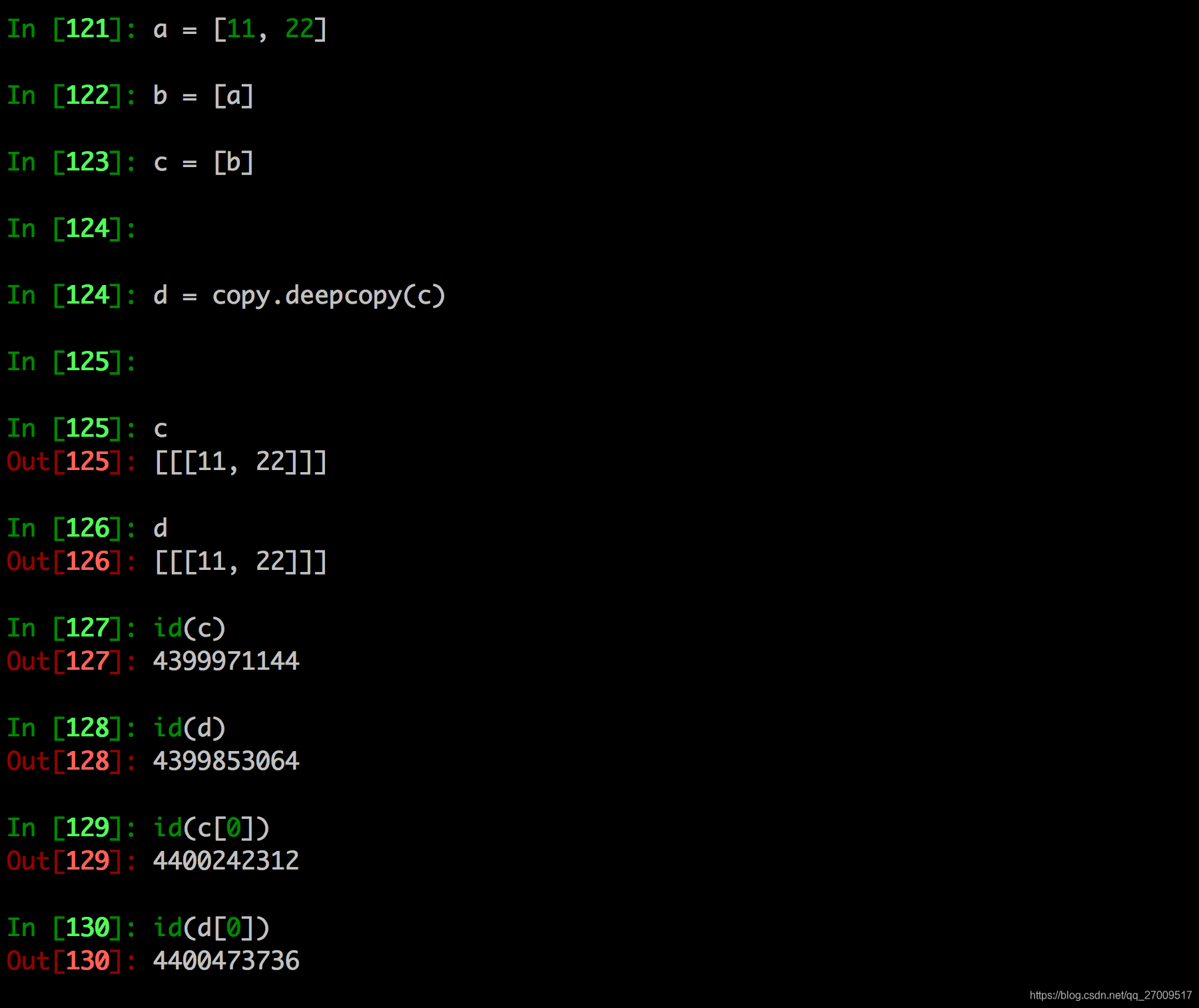
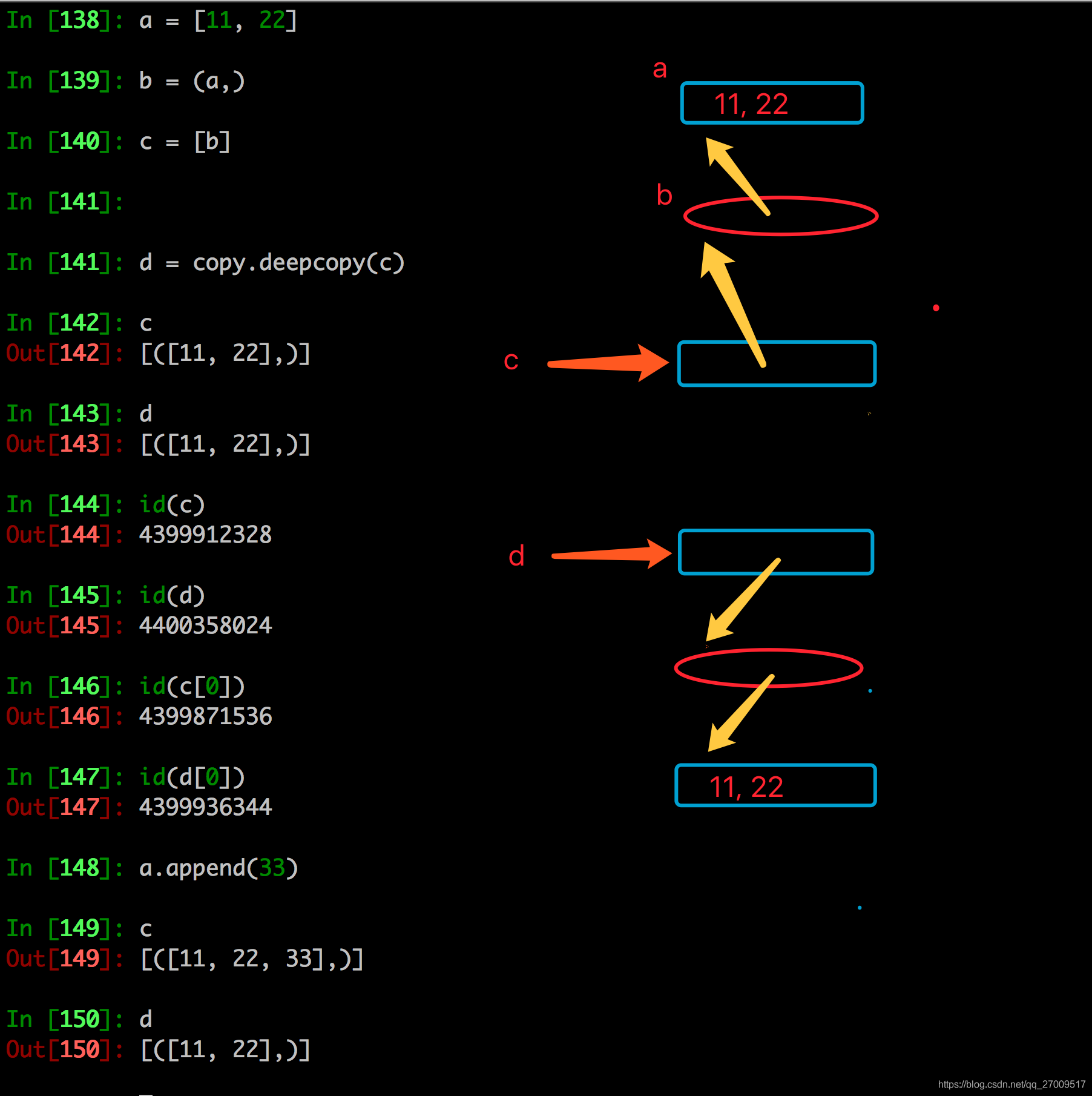
2. 深拷贝
深拷贝是对于一个对象所有层次的拷贝(递归)
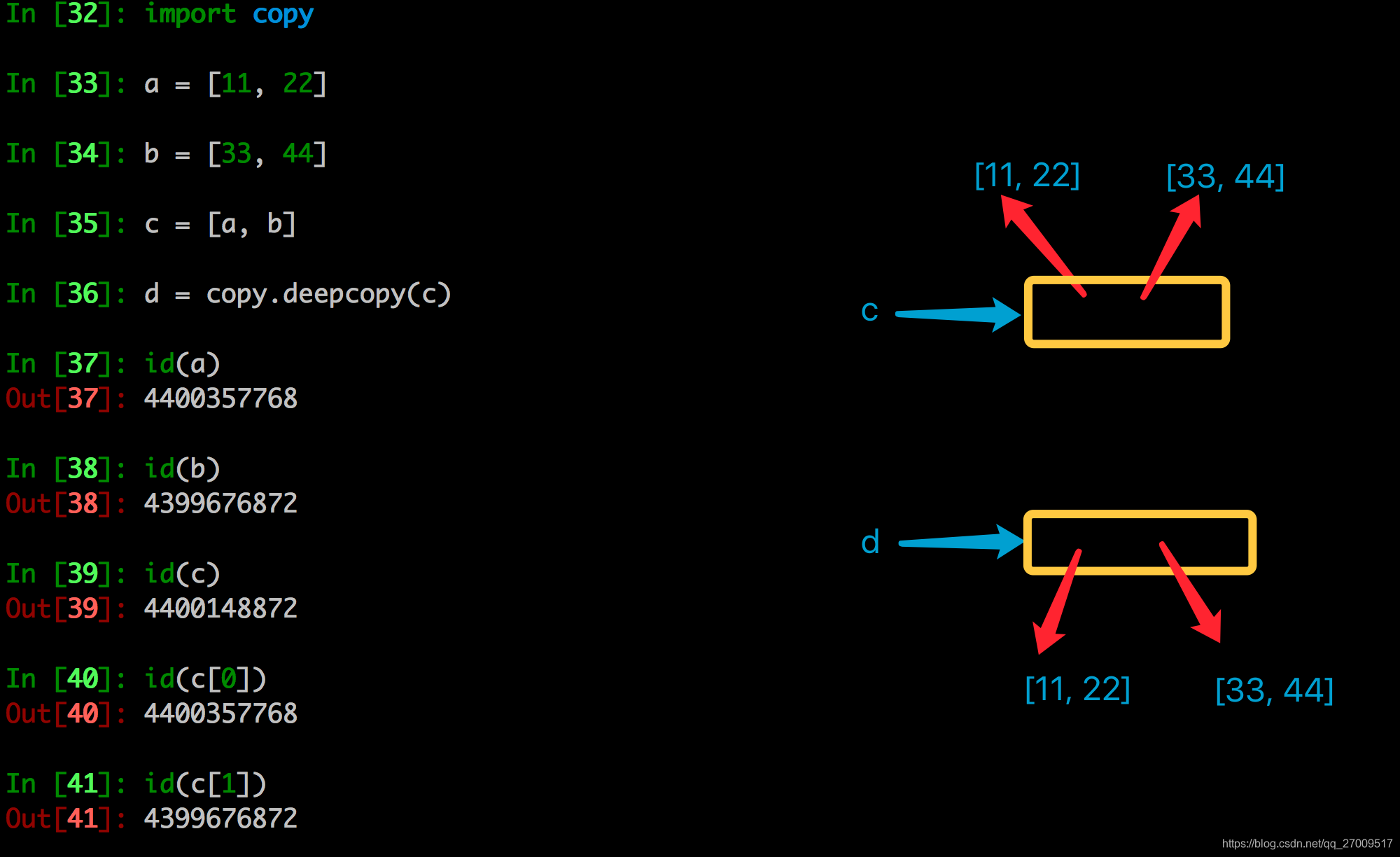
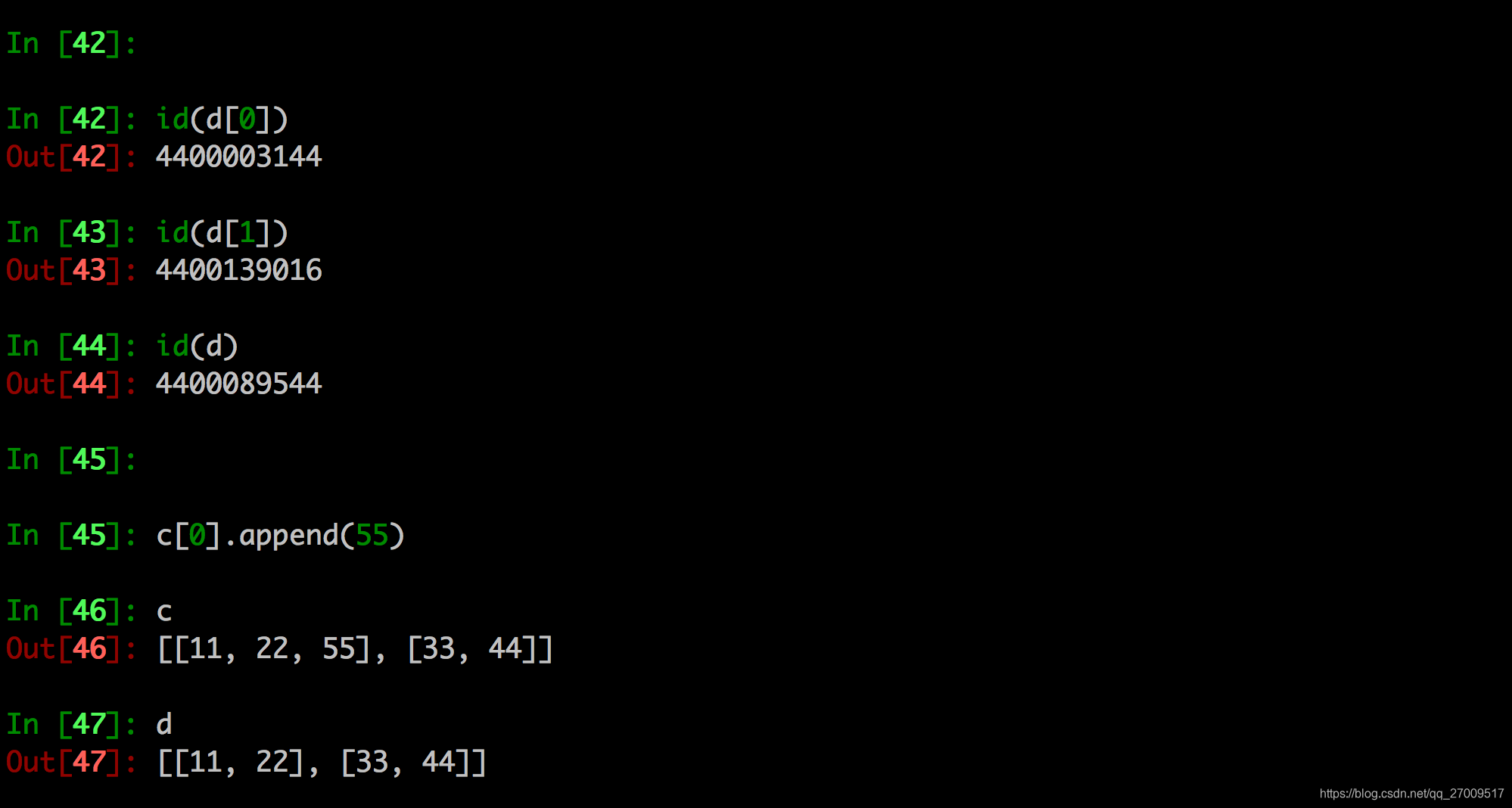
进一步理解深拷贝
3. 拷贝的其他方式
分片表达式可以赋值一个序列
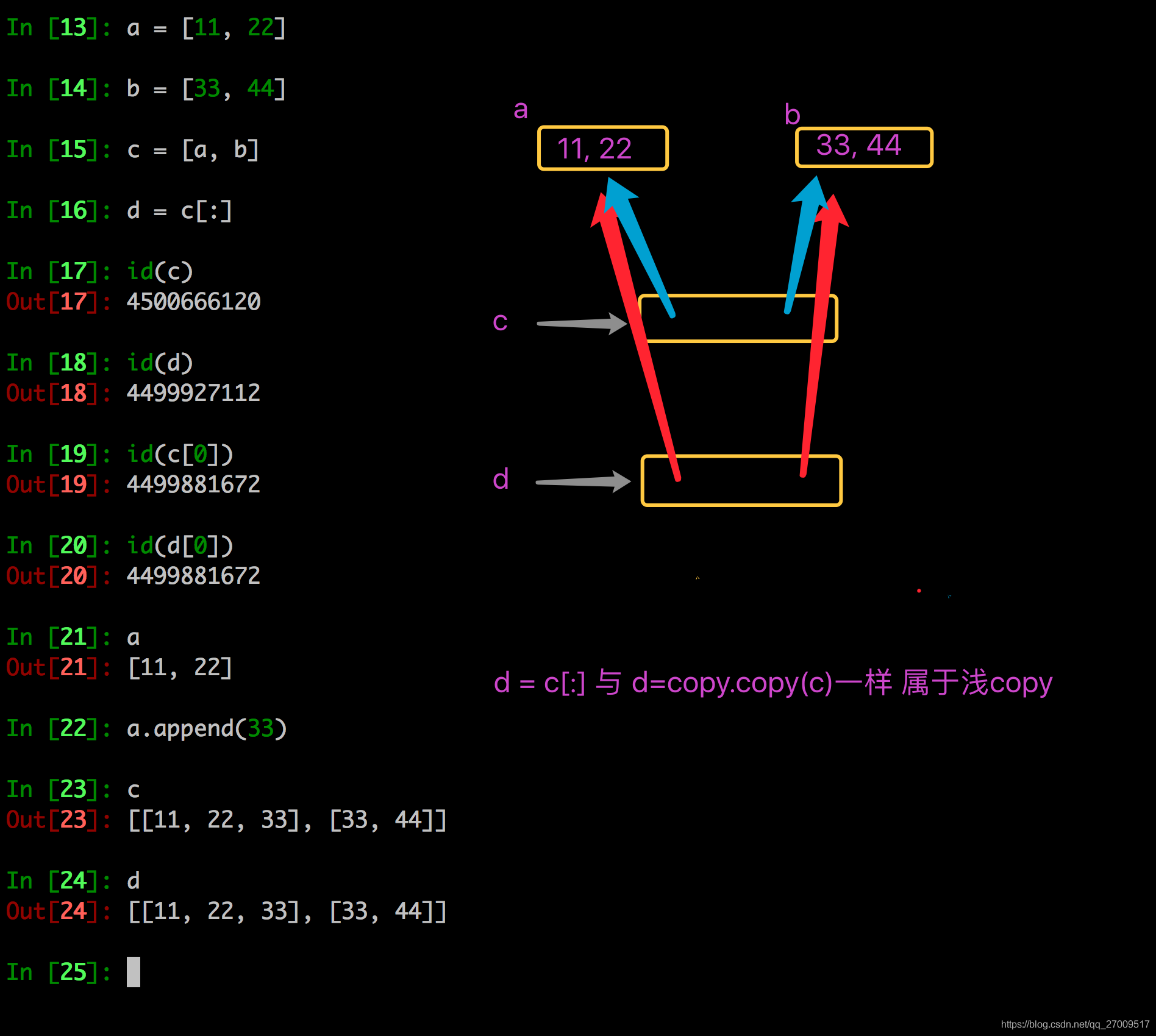
字典的copy方法可以拷贝一个字典
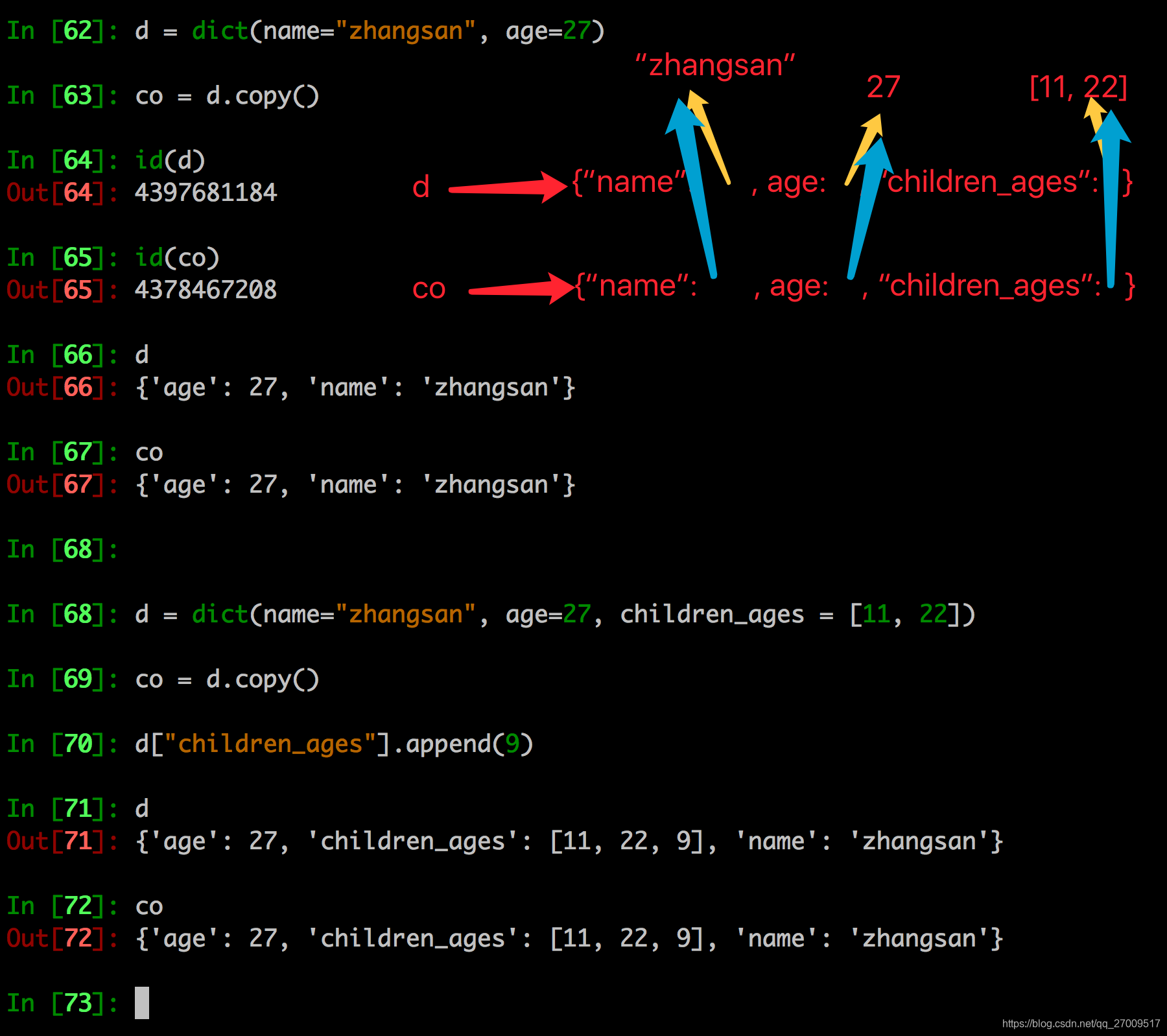
4. 注意点
浅拷贝对不可变类型和可变类型的copy不同
- copy.copy对于可变类型,会进行浅拷贝
- copy.copy对于不可变类型,不会拷贝,仅仅是指向
In [88]: a = [11,22,33]
In [89]: b = copy.copy(a)
In [90]: id(a)
Out[90]: 59275144
In [91]: id(b)
Out[91]: 59525600
In [92]: a.append(44)
In [93]: a
Out[93]: [11, 22, 33, 44]
In [94]: b
Out[94]: [11, 22, 33]
In [95]: a = (11,22,33)
In [96]: b = copy.copy(a)
In [97]: id(a)
Out[97]: 58890680
In [98]: id(b)
Out[98]: 58890680
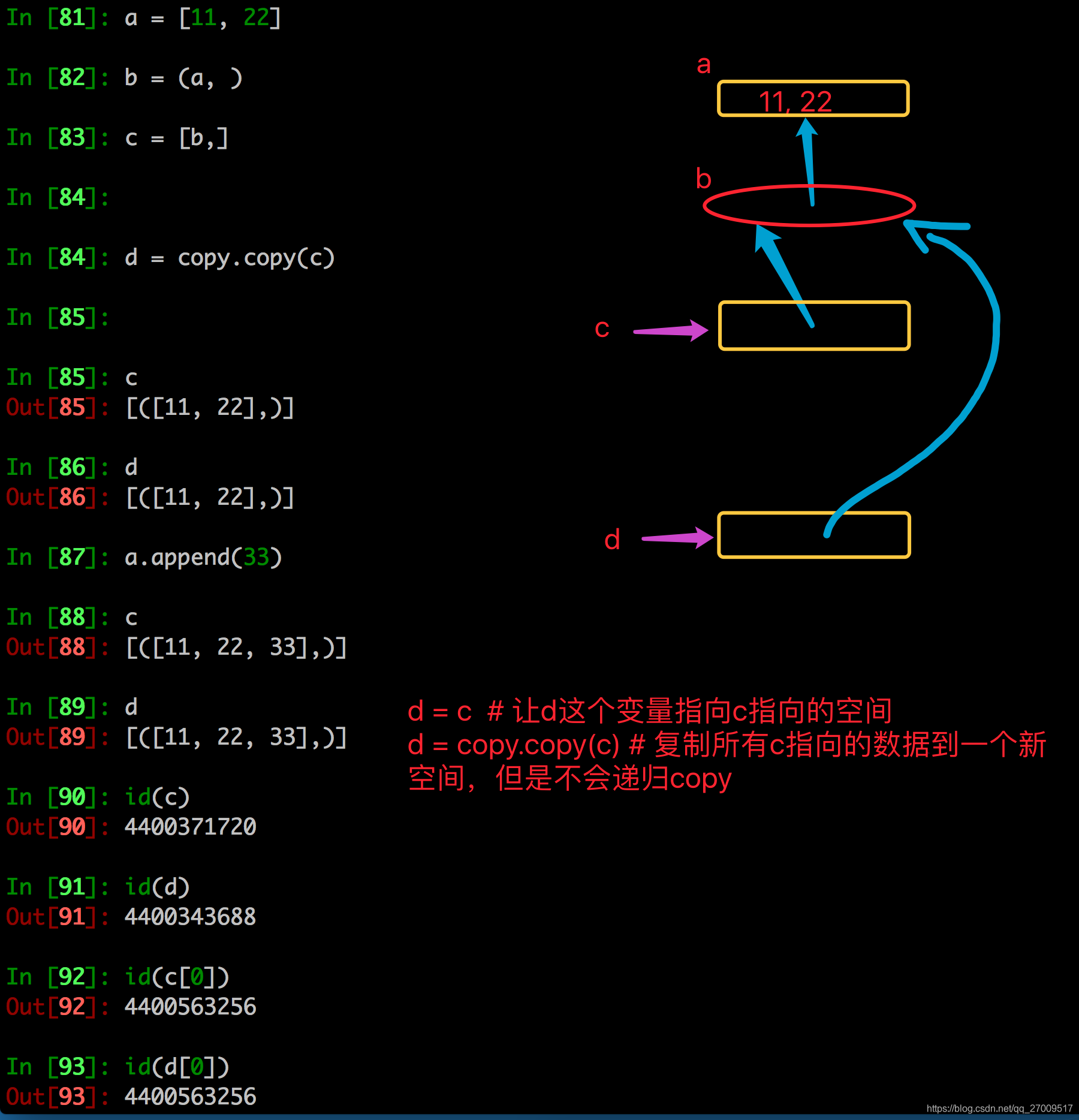
copy.copy和copy.deepcopy的区别
copy.copy
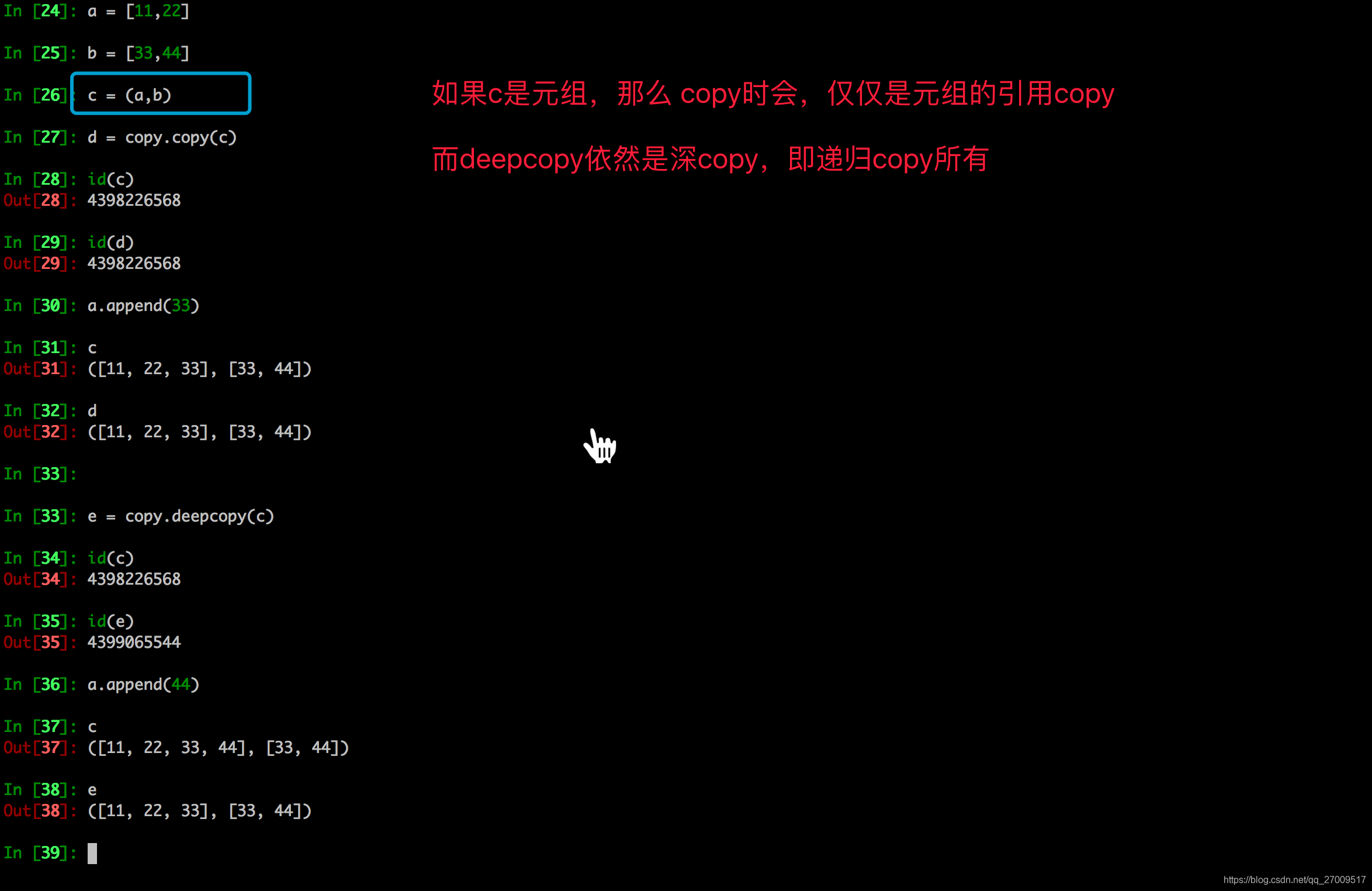
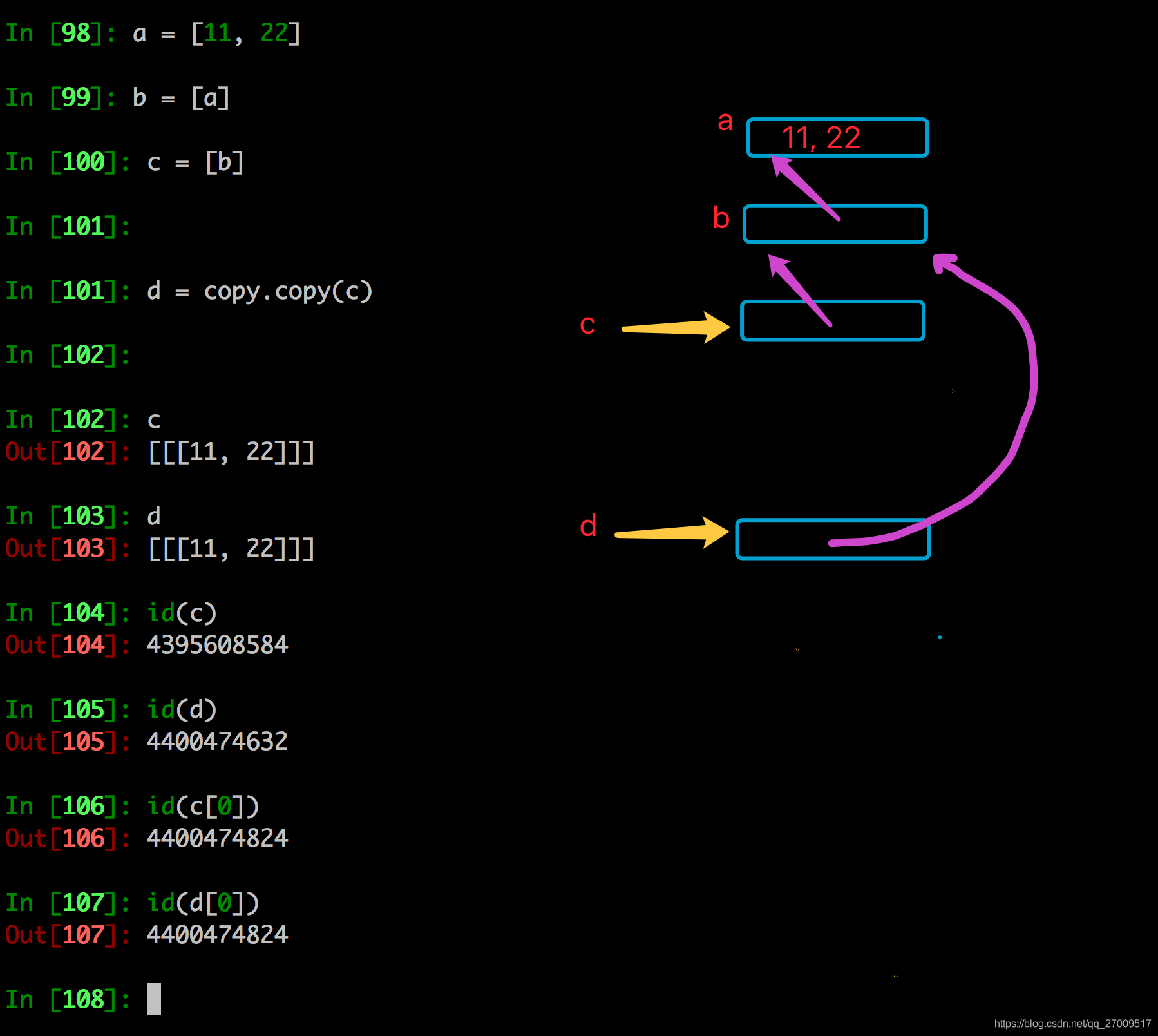
copy.deepcopy

12.3. 私有化
- xx: 公有变量
- _x: 单前置下划线,私有化属性或方法,from somemodule import *禁止导入,类对象和子类可以访问
- __xx:双前置下划线,避免与子类中的属性命名冲突,无法在外部直接访问(名字重整所以访问不到)
- xx:双前后下划线,用户名字空间的魔法对象或属性。例如:init , __ 不要自己发明这样的名字
- xx_:单后置下划线,用于避免与Python关键词的冲突
通过name mangling(名字重整(目的就是以防子类意外重写基类的方法或者属性)如:_Class__object)机制就可以访问private了。
#coding=utf-8
class Person(object):
def __init__(self, name, age, taste):
self.name = name
self._age = age
self.__taste = taste
def showperson(self):
print(self.name)
print(self._age)
print(self.__taste)
def dowork(self):
self._work()
self.__away()
def _work(self):
print('my _work')
def __away(self):
print('my __away')
class Student(Person):
def construction(self, name, age, taste):
self.name = name
self._age = age
self.__taste = taste
def showstudent(self):
print(self.name)
print(self._age)
print(self.__taste)
@staticmethod
def testbug():
_Bug.showbug()
# 模块内可以访问,当from cur_module import *时,不导入
class _Bug(object):
@staticmethod
def showbug():
print("showbug")
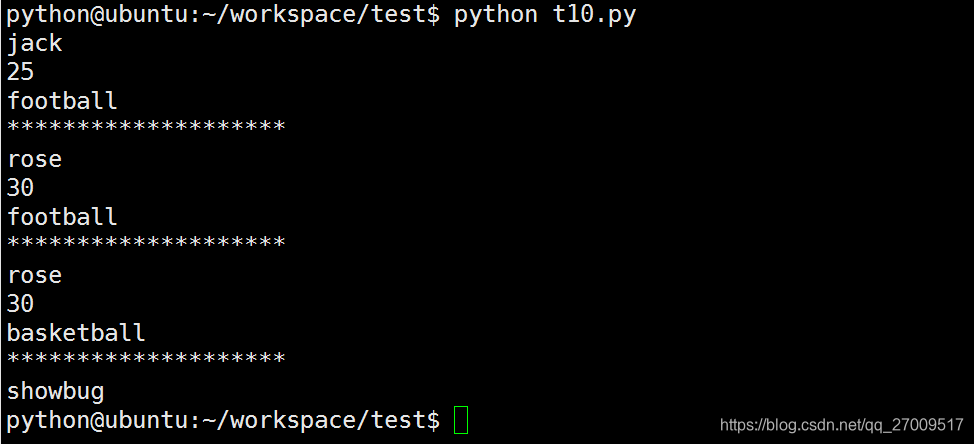
s1 = Student('jack', 25, 'football')
s1.showperson()
print('*'*20)
# 无法访问__taste,导致报错
# s1.showstudent()
s1.construction('rose', 30, 'basketball')
s1.showperson()
print('*'*20)
s1.showstudent()
print('*'*20)
Student.testbug()
私有变量
总结
- 父类中属性名为__名字的,子类不继承,子类不能访问
- 如果在子类中向__名字赋值,那么会在子类中定义的一个与父类相同名字的属性
- _名的变量、函数、类在使用from xxx import *时都不会被导入
12.4. import导入模块
- import 搜索路径
路径搜索
从上面列出的目录里依次查找要导入的模块文件
‘’ 表示当前路径
列表中的路径的先后顺序代表了python解释器在搜索模块时的先后顺序
程序执行时添加新的模块路径
sys.path.append('/home/itcast/xxx')
sys.path.insert(0, '/home/itcast/xxx') # 可以确保先搜索这个路径
In [37]: sys.path.insert(0,"/home/python/xxxx")
In [38]: sys.path
Out[38]:
[’/home/python/xxxx’,
‘’,
‘/usr/bin’,
‘/usr/lib/python35.zip’,
‘/usr/lib/python3.5’,
‘/usr/lib/python3.5/plat-x86_64-linux-gnu’,
‘/usr/lib/python3.5/lib-dynload’,
‘/usr/local/lib/python3.5/dist-packages’,
‘/usr/lib/python3/dist-packages’,
‘/usr/lib/python3/dist-packages/IPython/extensions’,
‘/home/python/.ipython’]
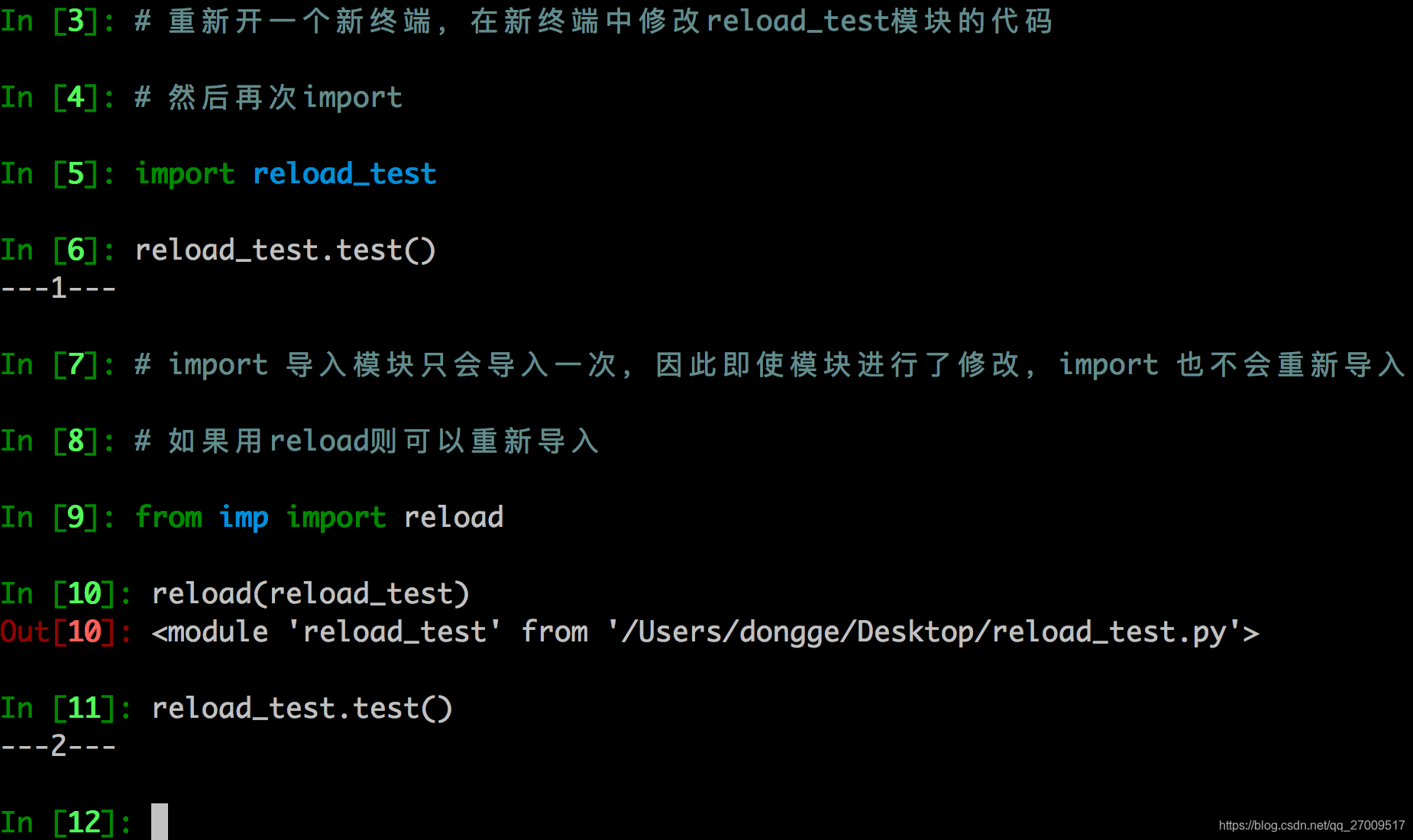
- 重新导入模块
模块被导入后,import module不能重新导入模块,重新导入需用reload



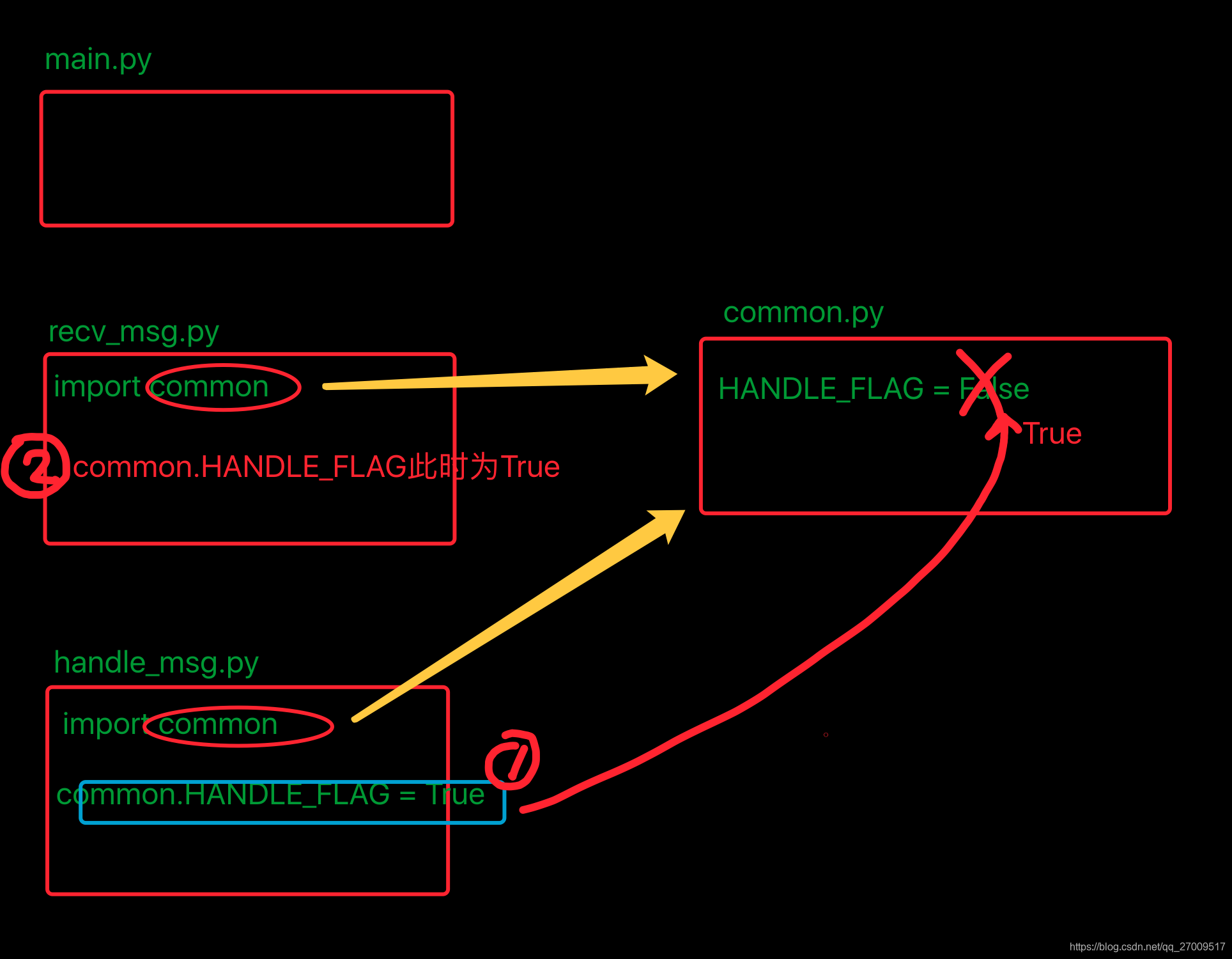
- 多模块开发时的注意点
recv_msg.py模块
from common import RECV_DATA_LIST
# from common import HANDLE_FLAG
import common
def recv_msg():
"""模拟接收到数据,然后添加到common模块中的列表中"""
print("--->recv_msg")
for i in range(5):
RECV_DATA_LIST.append(i)
def test_recv_data():
"""测试接收到的数据"""
print("--->test_recv_data")
print(RECV_DATA_LIST)
def recv_msg_next():
"""已经处理完成后,再接收另外的其他数据"""
print("--->recv_msg_next")
# if HANDLE_FLAG:
if common.HANDLE_FLAG:
print("------发现之前的数据已经处理完成,这里进行接收其他的数据(模拟过程...)----")
else:
print("------发现之前的数据未处理完,等待中....------")
handle_msg.py模块
from common import RECV_DATA_LIST
# from common import HANDLE_FLAG
import common
def handle_data():
"""模拟处理recv_msg模块接收的数据"""
print("--->handle_data")
for i in RECV_DATA_LIST:
print(i)
# 既然处理完成了,那么将变量HANDLE_FLAG设置为True,意味着处理完成
# global HANDLE_FLAG
# HANDLE_FLAG = True
common.HANDLE_FLAG = True
def test_handle_data():
"""测试处理是否完成,变量是否设置为True"""
print("--->test_handle_data")
# if HANDLE_FLAG:
if common.HANDLE_FLAG:
print("=====已经处理完成====")
else:
print("=====未处理完成====")
main.py模块
from recv_msg import *
from handle_msg import *
def main():
# 1. 接收数据
recv_msg()
# 2. 测试是否接收完毕
test_recv_data()
# 3. 判断如果处理完成,则接收其它数据
recv_msg_next()
# 4. 处理数据
handle_data()
# 5. 测试是否处理完毕
test_handle_data()
# 6. 判断如果处理完成,则接收其它数据
recv_msg_next()
if __name__ == "__main__":
main()

12.5. 再议 封装、继承、多态
封装、继承、多态 是面向对象的3大特性
为啥要封装
好处
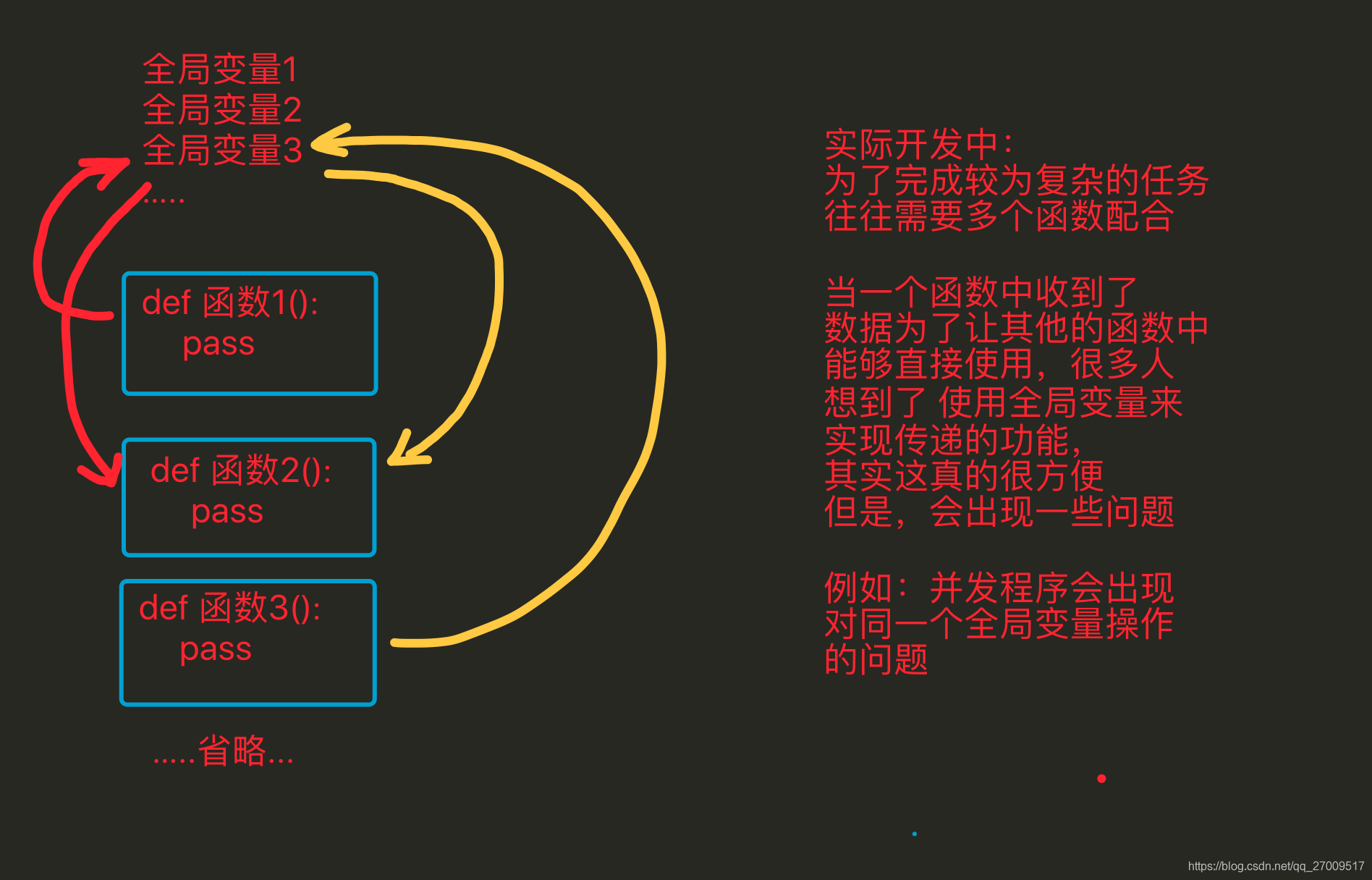
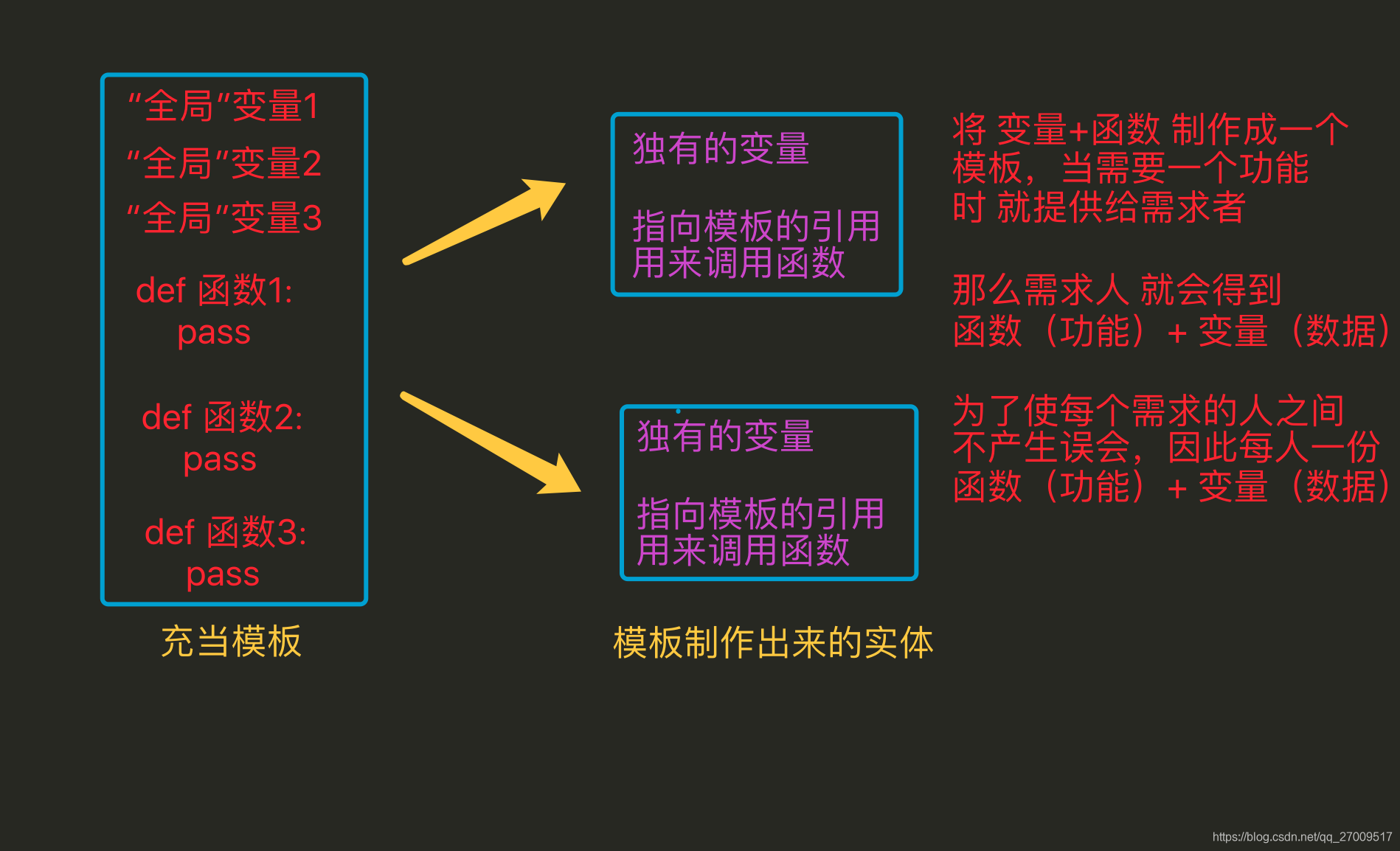
- 在使用面向过程编程时,当需要对数据处理时,需要考虑用哪个模板中哪个函数来进行操作,但是当用面向对象编程时,因为已经将数据存储到了这个独立的空间中,这个独立的空间(即对象)中通过一个特殊的变量(class)能够获取到类(模板),而且这个类中的方法是有一定数量的,与此类无关的将不会出现在本类中,因此需要对数据处理时,可以很快速的定位到需要的方法是谁 这样更方便
- 全局变量是只能有1份的,多很多个函数需要多个备份时,往往需要利用其它的变量来进行储存;而通过封装 会将用来存储数据的这个变量 变为了对象中的一个“全局”变量,只要对象不一样那么这个变量就可以再有1份,所以这样更方便
- 代码划分更清晰
面向过程
全局变量1
全局变量2
全局变量3
...
def 函数1():
pass
def 函数2():
pass
def 函数3():
pass
def 函数4():
pass
def 函数5():
pass
面向对象
class 类(object):
属性1
属性2
def 方法1(self):
pass
def 方法2(self):
pass
class 类2(object):
属性3
def 方法3(self):
pass
def 方法4(self):
pass
def 方法5(self):
pass
为啥要继承
说明
(1) 能够提升代码的重用率,即开发一个类,可以在多个子功能中直接使用
(2) 继承能够有效的进行代码的管理,当某个类有问题只要修改这个类就行,而其继承这个类的子类往往不需要就修改
怎样理解多态
class MiniOS(object):
"""MiniOS 操作系统类 """
def __init__(self, name):
self.name = name
self.apps = [] # 安装的应用程序名称列表
def __str__(self):
return "%s 安装的软件列表为 %s" % (self.name, str(self.apps))
def install_app(self, app):
# 判断是否已经安装了软件
if app.name in self.apps:
print("已经安装了 %s,无需再次安装" % app.name)
else:
app.install()
self.apps.append(app.name)
class App(object):
def __init__(self, name, version, desc):
self.name = name
self.version = version
self.desc = desc
def __str__(self):
return "%s 的当前版本是 %s - %s" % (self.name, self.version, self.desc)
def install(self):
print("将 %s [%s] 的执行程序复制到程序目录..." % (self.name, self.version))
class PyCharm(App):
pass
class Chrome(App):
def install(self):
print("正在解压缩安装程序...")
super().install()
linux = MiniOS("Linux")
print(linux)
pycharm = PyCharm("PyCharm", "1.0", "python 开发的 IDE 环境")
chrome = Chrome("Chrome", "2.0", "谷歌浏览器")
linux.install_app(pycharm)
linux.install_app(chrome)
linux.install_app(chrome)
print(linux)
运行结果
Linux 安装的软件列表为 []
将 PyCharm [1.0] 的执行程序复制到程序目录…
正在解压缩安装程序…
将 Chrome [2.0] 的执行程序复制到程序目录…
已经安装了 Chrome,无需再次安装
Linux 安装的软件列表为 [‘PyCharm’, ‘Chrome’]