数据清洗是数据分析、数据挖掘中至关重要的步骤之一。它不仅会直接影响到数据分析、数据挖掘的结果,还有助于我们进一步认识数据。前车之鉴是写这篇文章的主要目的。希望本文能够帮助小伙伴们少踩些坑。
在正式介绍我清洗铁路旅客流量数据的过程之前,不免要首当其冲说明下题目及数据的来源。该数据集来自于第四届泰迪杯全国数据挖掘挑战赛B题。
##数据库设计
该数据集是以xls文件给出的,且xls文件内的内容格式复杂,不便于读取数据。所以,整理数据集,设计数据库是必要的。
设计数据库的原则是尽可能的涵盖梯形密度表提供所有的信息。我将数据分别存入5张表中:t_meteorology、t_passenger_flow、t_station_info、t_train_info和t_train_kezuolv。下面是创建这几张表的sql语句。
CREATE TABLE `meteorology_table` (
`date` date NOT NULL COMMENT '日期',
`weather` varchar(20) DEFAULT NULL COMMENT '天气状况 晴/晴',
`temperature` varchar(20) DEFAULT '' COMMENT '气温 2℃/-5℃',
`wind` varchar(20) DEFAULT NULL COMMENT '风力风向 南风4-5级/南风3-4级',
`district` varchar(20) NOT NULL COMMENT '地区 ZD111',
PRIMARY KEY (`date`,`district`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `passenger_flow_table` (
`date` date NOT NULL COMMENT '日期',
`trainId` varchar(20) NOT NULL COMMENT '车次',
`station` varchar(20) NOT NULL COMMENT '车站',
`stationNum` int(11) DEFAULT NULL COMMENT '该车次的第几个站',
`inboundTime` time DEFAULT NULL COMMENT '进站时间',
`outboundTime` time DEFAULT NULL,
`upNum` int(11) DEFAULT NULL,
`downNum` int(11) DEFAULT NULL,
PRIMARY KEY (`trainId`,`date`,`station`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `station_info_table` (
`station` varchar(20) NOT NULL COMMENT '车站',
`district` varchar(20) DEFAULT NULL COMMENT '所属地区',
`mileage` int(20) DEFAULT NULL COMMENT '里程(公里)\r\n假设所有的站都是在一条直线上\r\n里程指的是到ZD111-01的距离',
PRIMARY KEY (`station`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `train_info_table` (
`trainId` varchar(20) NOT NULL COMMENT '车次',
`startStation` varchar(20) DEFAULT NULL COMMENT '始发站',
`endStation` varchar(20) DEFAULT NULL COMMENT '终点站',
`openDays` int(11) DEFAULT NULL COMMENT '开行天数',
`riJunDingYuan` int(11) DEFAULT NULL COMMENT '日均定员',
PRIMARY KEY (`trainId`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `train_kezuolv_table` (
`date` date NOT NULL COMMENT '日期',
`trainId` varchar(20) NOT NULL COMMENT '车次',
`keZuoLv` float DEFAULT NULL COMMENT '客座率',
PRIMARY KEY (`date`,`trainId`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
该数据库设计的缺点显而易见,没有包含梯形密度表的中间部分的数据,如图1红框中的内容。
##数据异常或缺失
###梯形密度表缺失
下载该数据集合后,初步浏览所下载的文件,发现所提供的数据的日期范围为2015年1月1日到2016年3月20日。由此,我下意识的想了下,是否会缺失某一天的数据呢?带着疑问,我按文件名浏览了一遍数据集。果不其然,被我一语中的。缺失的文件有20150324.xls、20150330.xls、20150331.xls、201507026.xls和20151031.xls。而20150826.xls虽然存在,但是没有任何内容,是个空文件。因此,20150826.xls也可以认为是缺失的。
针对这种情况,补全数据需要分为两步:
步骤1,补全每一天的运行车次;
步骤2,用均值或者其他方法补全上下车人数。(我用的是均值)
步骤1需要特别注意的是,要添加的车次是否在当天运行。数据集中所有车次运行频率如图2所示。从图2中可以看出,不是所有的车次在给定时间段内一直运行,而是有的运行几次,有的运行一段时间,还有的先运行几次,然后运行一段时间。
因此,给缺失文件补全车次的原则如下:
(1)如果要添加的车次只出现几次,那么,该车次可以舍弃;
(2)如果要添加的车次某段时间连续出现,且缺失的文件日期正在这段时间内,那么添加该车次;
以上的梯形密度表缺失是因为文件缺失导致。下面的情况是由于某一天的文件缺了本应该存在的车次。
如图3,D52在20160202-20160302时间段内共出现23次,由此可以认为,该车次有6天是缺失的,需要在对应日期补全车次及上下车人数。
同一车次,与正常的梯形密度表相比,如果上车站或下车站只缺少一个,那么只需当前的梯形密度表即可做出判断;如果上车站或下车站缺少多个,那么需要根据最近几天的相同车次的上下车站来判断,这是因为,有些车次对于某个站,有时候会停车,有时候则不会。此外,有些梯形密度表的上下车人数严重缺失,如G09车次在2015年08月03日,梯形密度表的上下车站个数为1、2(如图4©),而正常情况下应该为9、10(如图4(d)),这时,应该认为该梯形密度表整体缺失。
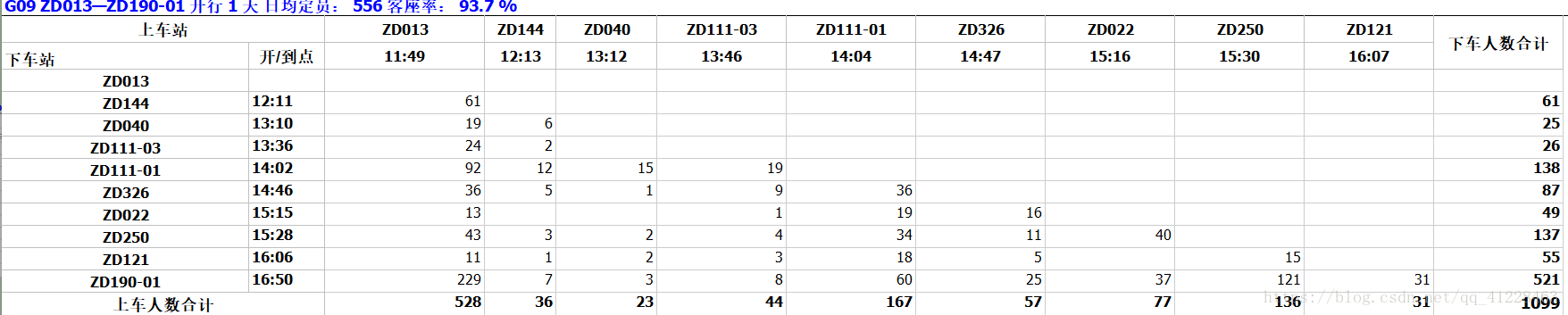
此外,数据集的少部分xls文件中上下车站名出现了汉字,而不是编码。该情况出现的位置分别为20150418.xls中的第852行(K08)和20150426.xls中的第1059行(k01))。这种情况通过与其它xls文件比较,便可以得到真实地名的编码。
以上就是我清洗数据时遇到的所有特殊情况。记录下来,希望对小伙伴们或多或少有些帮助。可能会有遗漏,希望大家指正。