第一天
1.1简介
Node.js简介
V8引擎本身就是用于Chrome浏览器的JS解释部分,Ryan Dahl把这个V8搬到了服务器上,用于做服务器的软件。
Node.js是一个让Javascrip运行在服务端的开发平台,它让JavaScript的触角伸到了服务器端,可以与PHO、JSP、Python、Ruby平起平坐。
·NodeJS不是一种独立的语言,与PHP、JSP、Pythoin、Perl、Ruby的‘即是语言也是平台’不同,Nodejs使用JS编程,运行在V8引擎上。
·与PHP、JSP相比,Node.js跳过了Apache、Ngix,IIS等HTTP服务器,它自己不用建设在任何服务器软件智商,Node.js的许多设计理念与经典架构(LAMP linux+apache+mysql+Php)有很大不同,可以提供强大的伸缩能力。
PHP、JSP、.net都需要运行在服务器程序上,Apache、Nginx、Tomcat、IIS。
Node.js自身哲学,是花最小的硬件成本,追求更高的并发,更高的处理性能。
1.2特点
单线程 非阻塞I/O 事件驱动
单线程
在Java、PHP或者.net等服务器语言中,会为每一个客户端连接创建一个新的线程,而每个线程需要耗费大约2MB内存。也就是说,理论上,一个8GB内存的服务器可以同时连接的最大用户数为4000个左右要让web应用程序支持更多的用户,就需要增加服务器的数量,而web应用程序的硬件成本当然就上升了。
Node.j不为每个客户连接创建一个新县城,而仅仅使用 一个线程,当有用户连接了,就触发一个内部事件,通过非阻塞I/O事件驱动机制,让Node.js程序宏观上也是并行的。使用Node.js一个8GB内存的服务器,可以同时处理超过4万用户的连接。
另外,单线程带来的好处,还有操作系统完全不再有线程创建、销毁的时间开销。
缺点:一个用户造成了线程的崩溃,整个服务器都崩溃了。
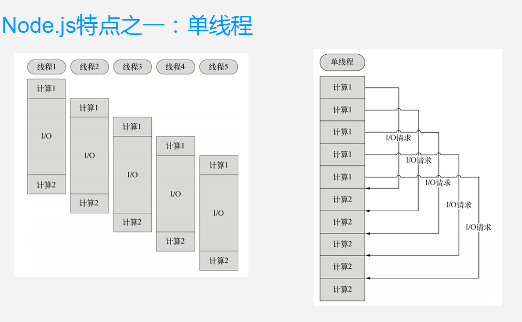
因为有事件队列,所以遇到IO请求就继续做下一个计算,而是不去让一个线程等待I/O请求堵死。
非阻塞I/O
例如,当在访问数据库取得数据的时候,需要一段时间,在传统的单线程处理机制中,在执行了访问数据库代码之后,整个线程都将暂停下来,等待数据库返回结果,才能执行后面的代码,也就是说,I/O阻塞了代码的执行,极大的降低了程序的执行效率。
由于Node.js中采用了非阻塞性的I/O机制,因此在执行了访问数据库的代码之后,将立即转而执行其后面的代码,把数据库返回结果的处理代码放在回调函数中,从而提高了程序的执行效率。
当某个I/O执行完毕时,将以事件的形式通知执行I/O操作的线程,线程执行这个事件的回调函数。为了处理异步I/O,线程必须有事件循环,不断的检查有没有未处理的事件,依次予以处理。
阻塞模式下,一个线程只能处理一项任务,要想提高吞吐量必须通过多线程,而非阻塞模式下,一个线程永远在执行计算操作,这个线程的CPU核心利用率永远是100%,所以,这是一种特别有哲理的解决方案,预期人多,但是好多人闲着,还不如一个人玩命,往死里干活。
事件驱动
在Node中,客户端请求建立连接,提交数据等行为,会触发相应的事件,在Node中,在一个时刻,只能执行一个事件回调函数,但是在执行一个事件回调函数的中途,可以转而处理其他事件(比如,又又新用户连接了),然后返回继续执行原事件的回调函数,这种处理机制,称为“事件环”(event loop)机制。
Node.js底层是C++(V8也是C++写的)。底层代码中,近半数都用于事件队列、回调函数队列的构建,用事件驱动来完成服务器任务的调度,这是鬼才才能想道的。
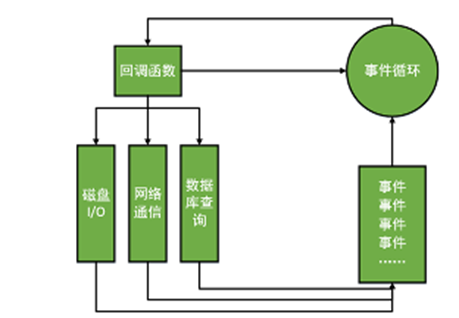
单线程,单线程的好处,减少了内存开销,操作系统的内存换页。
如果某一个事情,进入了,但是被I/O阻塞了,所以这个线程就阻塞了。
非阻塞I/O,不会傻等I/O语句结束,而会执行后面的语句。
非阻塞就能解决问题了么?比如执行着小红的业务,执行
过程中,小刚的I/O完成了。所以要有事件环(Event Loop)机制,不管是新用户的请求,还是老用户的I/O完成,都将以事件方式加入事件环,等待调度。
CPU计算和磁盘I/O是不同的元件,是并行操作的,磁盘I/O不是由CPU计算。
1.3适合开发什么
善于I/O,不善于计算,因为Node.js最擅长的就是任务调度,如果你的业务多用CPU进行计算,实际上也相当于这个计算阻塞了这个单线程。
当应用程序需要处理大量并发的I/O,而在客户端发出相应之前,应用程序内部并不需要进行非常复杂的处理的时候,Node非常适合。Nodejs也非常适合与websocket配合,开发长连接的实时交互应用程序。
比如:
·用户表单收集 (百度的表单是用Node做的、知乎的站内信用Node写的)
·考试系统
- ·聊天室
- ·图文直播
- ·提供JSON的API
tracert www.sina.com
看看经过多少个服务器中专到达了新浪服务器。
1.4 NodeJS无法挑战老牌3P

二、Node.js安装
Node.js和Java非常像,跨平台的。不管是Linux还是Windows编程时完全一致的(有一些不一样的路径的表述)。Linux版的Node.js环境和windows不一样,但是编程语言一样,很像Java虚拟机,
WindowsCMD技巧,输入目录的时候按Tab键可以智能感应。
或者可以直接拖进去
const http = require(‘http’)
var server= http.createServer((req,res)=>{
res.WriteHead(200,{‘Content-type’:’text/html;charset=UTF-8’});
res.end(‘哈哈哈我买了一个iphone’);
})
server.listen(3000,(err)=>{
if(err) throw err;
console.log(‘服务器已经成功运行在3000端口’;)
})
一个JS文件不能直接在浏览器运行的(比如拖动到浏览器中),必须要加一堆HTML标签,老老实实写在script的引用中让浏览器解析才可以使用。
Node却可以直接运行,Node是一个JS执行环境(runtime)。(runtime—“编译时候的”库)
NodeJS没有根目录的概念,因为它根本没有任何的web容器!
让Node.js提供一个静态服务都特别难。(对HTML、JS、CSS静态资源的服务)
Node.js的http模块不能像iis,tomcat一样能自动处理静态资源。
web容器的定义:
web容器是一种服务程序,在服务器一个端口就有一个提供相应服务的程序,而这个程序就是处理从客户端发出的请求,如JAVA中的Tomcat容器,ASP的IIS或PWS都是这样的容器。一个服务器可以有多个容器。
顶层路由设计
(需要对每一次路由进行设计,对所有请求进行设计)
写一个网页,在中间引入
<img src=’0.jpg’ />
这样一个标签,会发现图片无法正常加载。
这是因为Node没有web容器
对0.jpg的请求并没有定义。
请补上:
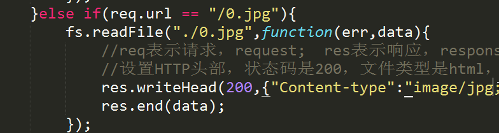
这样的话,就算是link了一个css,你也得自己去手动写…
想下面这样:
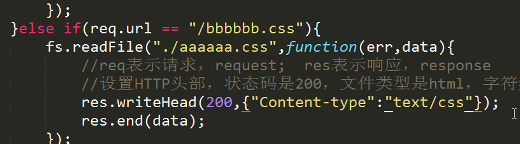
让Node.js提供一个静态服务都特别难。
(对HTML、JS、CSS静态资源的服务)
也就是说,node.js中,如果看见一个网址是
127.0.0.1:3000/fang
别再去想,一定有一个文件夹,叫做fang了。可能/fang的物理文件,是同目录的test.html URL和真实物理文件,是没有关系的。URL是通过Node的顶层路由设计,呈现一个静态文件的。
这种顶层路由设计,自由性很大,可以设计出非常非常漂亮的路由。
源代码:
haha.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
<link rel="stylesheet" href="bbbb.css">
<style>
div{
background: green;
border-radius: 50%;
width:100px;
height:100px;
}
</style>
</head>
<body>
<div></div>
</body>
</html>
test.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
<style>
div{
padding: 15px;
background: powderblue;
}
</style>
</head>
<body>
<div></div>
</body>
</html>
2.js:
const http = require('http');
const fs = require('fs');
var server = http.createServer((req, res) => {
if (req.url == '/test') {
fs.readFile('./test.html', (err, data) => {
if (err) throw err;
res.writeHead(200, { 'Content-type': 'text/html,charset=UTF-8' });
res.end(data);
})
}
else if (req.url == '/haha') {
fs.readFile('./haha.html', (err, data) => {
if (err) throw err;
res.writeHead(200, { 'Content-type': 'text/html,charset=UTF-8' });
res.end(data);
})
}
else{
res.writeHead(404, { 'Content-type': 'text/html,charset=UTF-8' });
res.end('没有这个页面');
}
});
server.listen(3000, () => {
console.log('服务器运行了');
});
(注:这里的源代码有个比较严重的问题,fs应该用绝对路径,否则可能会看不了)
三、HTTP模块
Node.js中,将很多的功能,划分为了一个个module 大陆翻译为模块,台湾书翻译为模组。
http模块简单讲解
//引用模块
var http = require('http');
var server=http.createServer((req,res)=>{
console.log('服务器接收到了请求'+req.url);
//服务器必须要有res.end();否则浏览器那边小菊花会一致旋转。
//焦急地等待服务器的回复..直到浏览器内置请求时间超时
res.end();
});
server.listen(3000,()=>{
console.log('在3000端口启动了服务');
})
http模块

没有web容器的概念。
MIME
【词典】 多用途的网际邮件扩充协议:

… … 在Content-type字段需要写MIME类型
注:监听’127.0.0.1’ 监听’localhost’ 还是不能在浏览器中访问自己的IP地址,设置listen监听自己的IP,这样局域网中别人才能访问你。
response.writeHead(statusCode[, statusMessage][, headers])
const body = 'hello world';
response.writeHead(200, {
'Content-Length': Buffer.byteLength(body),
'Content-Type': 'text/plain' });
//引用模块
var http = require('http');
var server=http.createServer((req,res)=>{
console.log('服务器接收到了请求'+req.url);
//服务器必须要有res.end();否则浏览器那边小菊花会一致旋转。
//焦急地等待服务器的回复..直到浏览器内置请求时间超时
res.writeHead(200,{
'Content-type':'text/html;charset=UTF-8'
})
res.end('hello');
});
server.listen(3000,()=>{
console.log('在3000端口启动了服务');
});

再写一遍hello world:
var http = require('http');
//因为createServer返回的是一个新的http.Server实例,
//所以可以连续打点向下写。
http.createServer((req,res)=>{
res.writeHead(200,{
'Content-type':'text/html;charset=UTF-8'
})
res.write('Hello World!');
res.end();
}).listen(3000,()=>{console.log('yep')});
URL模块
我们现在来看以下req里面能够使用的东西。
最关键的就是req.url属性,表示用户的请求URL地址。
所有的路由设计,都是通过req.url来实现的。
我们比较关心的不是拿到URL,而是识别这个URL。
识别URL,用到两个新模块,一个是url模块,第二个是querystring模块。
字符串查询:用querystring处理。

url.parse(req.url).xxxxx…
测试一下:
http://127.0.0.1:3000/asdasd/asdasd/qweqwe1.html?asdsad=fafsa&asd=afasff#23


传入第二个参数可以把query也给parse成对象。

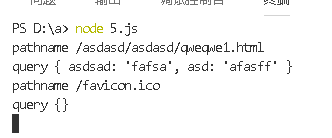
源代码:
var http = require('http');
var url = require('url');
var server = http.createServer((req,res)=>{
//url.parse()可以把一个完整的URL地址,分为很多部分:
//host、port、pathname、path、query
//传入第二个参数为true,那么就可以将query编程对象
var pathname = url.parse(req.url).pathname;
var query = url.parse(req.url).query;
console.log('pathname',pathname);
console.log('query',query);
res.end();
}).listen(3000);
试着做一个表单提交
server.js:
const http = require('http');
const url = require('url');
var server = http.createServer((req,res)=>{
var queryObj = url.parse(req.url,true).query;
var name = queryObj.name;
var age = queryObj.age;
var sex = queryObj.sex;
res.writeHead(200,{'Content-type':'text/html;charset=utf8'})
res.end('服务器收到了表单请求'+name+age+sex);
}).listen(3000,'127.0.0.1',()=>{console.log('服务器成功创建')});
1.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
<style>
</style>
</head>
<body>
<form action="http://127.0.0.1:3000/" method="GET">
姓名:<input type="text" name="name"><br>
年龄:<input type="text" name='age'><br>
<input type="radio" name='sex'id='man' value="男"><label for="man">男</label>
<input type="radio" name='sex'id='woman' value="女"><label for="woman">女</label>
<input type="submit">
</form>
</body>
</html>
注:
‘querystring’模块也有parse,返回的是querystring部分的一个对象。其实相当于是’url’模块中的parse,第二个参数加了true。
parseQueryString<boolean> 如果为true,则query属性总会通过querystring模块的parse()方法生成一个对象。 如果为false,则返回的 URL 对象上的query属性会是一个未解析、未解码的字符串。 默认为false。
(教程中的确是这样讲的,但是其实是有一点点不一样的。。querystring返回的是这样
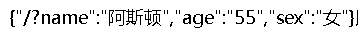
用url方式返回的是这样
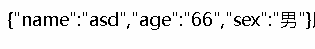
)
简单的小路由展示
当用户访问/student/1234567890 的查询此学号的学生信息
当用户访问/teacher/65433的时候,查询此教师的信息
其他的,我们提示错误,如果位数不退,提示位数不对。
const http = require('http');
var server = http.createServer((req,res)=>{
res.writeHead(200,{'Content-type':'text/html;charset=utf8'});
//得到url
var userurl = req.url;
var startsWith = userurl.substr(0,9);
var id = userurl.substr(10);
//substr函数来判断此时的开头
if( startsWith == '/student/'){
if(/\d{10}/.test(id))
{
res.end('您要查询的学生信息,id为'+id);
}
else{
res.end('学号位数不对');
}
}else if(startsWith == '/teacher/'){
if(/\d{6}/.test(id)){
res.end('您要查询老师信息,id为'+id);
}
else{
res.end('老师学号位数不对');
}
}
else
{
res.end('请检查url');
}
});
server.listen(3000);
探求事件环机制
内容:读取一个文件然后展示出来:
const http =require('http');
const fs = require('fs');
const path = require('path');
var server = http.createServer((req,res)=>{
var userid = parseInt(Math.random() * 89999) + 10000;
if(req.url == '/favicon.ico'){return;}
console.log('欢迎'+userid );
res.writeHead(200,{'Content-type':'text/html;charset=utf8'});
//两个参数
fs.readFile(path.join(__dirname+'/1.txt'),(err,data)=>{
if(err) throw err;
console.log(userid+'文件读取完毕');
res.end(data);
})
}).listen(3000,()=>{console.log('server is running at port 3000')});
fs模块的功能
四、fs模块
提出问题:
当循环内有一个异步操作:这个异步操作将读出的文件夹push到一个数组中,在哪里console.log(arr)比较合适?
(其实,如果能找到循环中最后一次异步操作的回调就好,问题被转化成,怎么寻找循环中异步操作的回调的最后一次?)
var http = require('http');
var fs = require('fs');
//存储所有的文件夹
var wenjianjia = [];
fs.readdir('./album', (err, files) => {
//files是个文件名的数组,表示./album这个文件夹中的所有东西
//包括文件、文件夹
for (var i = 0; i < files.length; i++) {
(function(i){
//文件名
var thefile = files[i];
//又要进行一次检测
fs.stat('./album/' + thefile, (err, stats) => {
if (stats.isDirectory()) {
wenjianjia.push(thefile);
if(i==files.length-1)
console.log(wenjianjia);
}
});
})(i);
}
});
(这个方法是我写的,使用了闭包)
视频中是这样写的:
//迭代器
var fs = require('fs');
//存储所有的文件夹
var wenjianjia = [];
fs.readdir('./album', (err, files) => {
//files是个文件名的数组,表示./album这个文件夹中的所有东西
//包括文件、文件夹
var i = 0;
(function iterator(i) {
var thefile = files[i];
if (i == files.length) {
console.log(wenjianjia);
return;
}
fs.stat('./album/' + thefile, (err, stats) => {
if (stats.isDirectory()) {
wenjianjia.push(thefile);
}
i++;
//主要是这里保证了在这个异步操作后再完成下一次操作,
iterator(i);
});
})(i);
});
使用的了迭代器。
总结一下:当遇到这样,读取一个文件夹并判断里面的内容哪个是文件,哪个是文件夹。
一个异步操作中,有一个循环,循环中还有一个异步操作。
静态资源文件管理
const http = require('http');
const url = require('url');
const fs = require('fs');
const path = require('path');
http.createServer((req, res) => {
if (req.url == '/favicon.ico') return;
//得到用户的路径
//127.0.0.1/a/1.html?id=2
var pathname = url.parse(req.url).pathname;
//真的读取这个文件
if (pathname == '/') {
pathname = 'index.html';
}
var extname = path.extname(pathname);
var mime = getMime(extname);
//我们很牛逼的把static变成根目录了,做了一个服务器
fs.readFile('./static/' + pathname, (err, data) => {
if (err) {
fs.readFile('./static/404.html', (err, data) => {
//MIME类型,就是
//网页文件:text/html
//jpg文件:image/jpg
res.writeHead(404, { 'Content-type': `${mime};charset=utf8` });
res.end(data);
});
return;
};
res.writeHead(200, { 'Content-type': `${mime};charset=utf8` });
res.end(data);
});
}).listen(3000);
function getMime(extname) {
switch (extname) {
case '.html':
return 'text/html';
break;
case '.jpg':
return 'image/jpg';
break;
case '.css':
return 'text/css';
break;
}
}
写了一个静态资源服务器,把static文件设置为默认的根目录了。
const http = require('http');
const url = require('url');
const fs = require('fs');
const path = require('path');
http.createServer((req, res) => {
if (req.url == '/favicon.ico') return;
//得到用户的路径
//127.0.0.1/a/1.html?id=2
var pathname = url.parse(req.url).pathname;
//真的读取这个文件
if (pathname == '/') {
pathname = 'index.html';
}
var extname = path.extname(pathname);
var mime = getMime(extname);
//我们很牛逼的把static变成根目录了,做了一个服务器
fs.readFile('./static/' + pathname, (err, data) => {
if (err) {
fs.readFile('./static/404.html', (err, data) => {
//MIME类型,就是
//网页文件:text/html
//jpg文件:image/jpg
res.writeHead(404, { 'Content-type': `${mime};charset=utf8` });
res.end(data);
});
return;
};
res.writeHead(200, { 'Content-type': `${mime};charset=utf8` });
res.end(data);
});
}).listen(3000);
function getMime(extname) {
switch (extname) {
case '.html':
return 'text/html';
break;
case '.jpg':
return 'image/jpg';
break;
case '.css':
return 'text/css';
break;
}
}