一开始下载了最新版的kettle8.2,经过各种百度,下载hive配置和jar包,但是总是连接不上hive,报各种错误,不一一举例了。
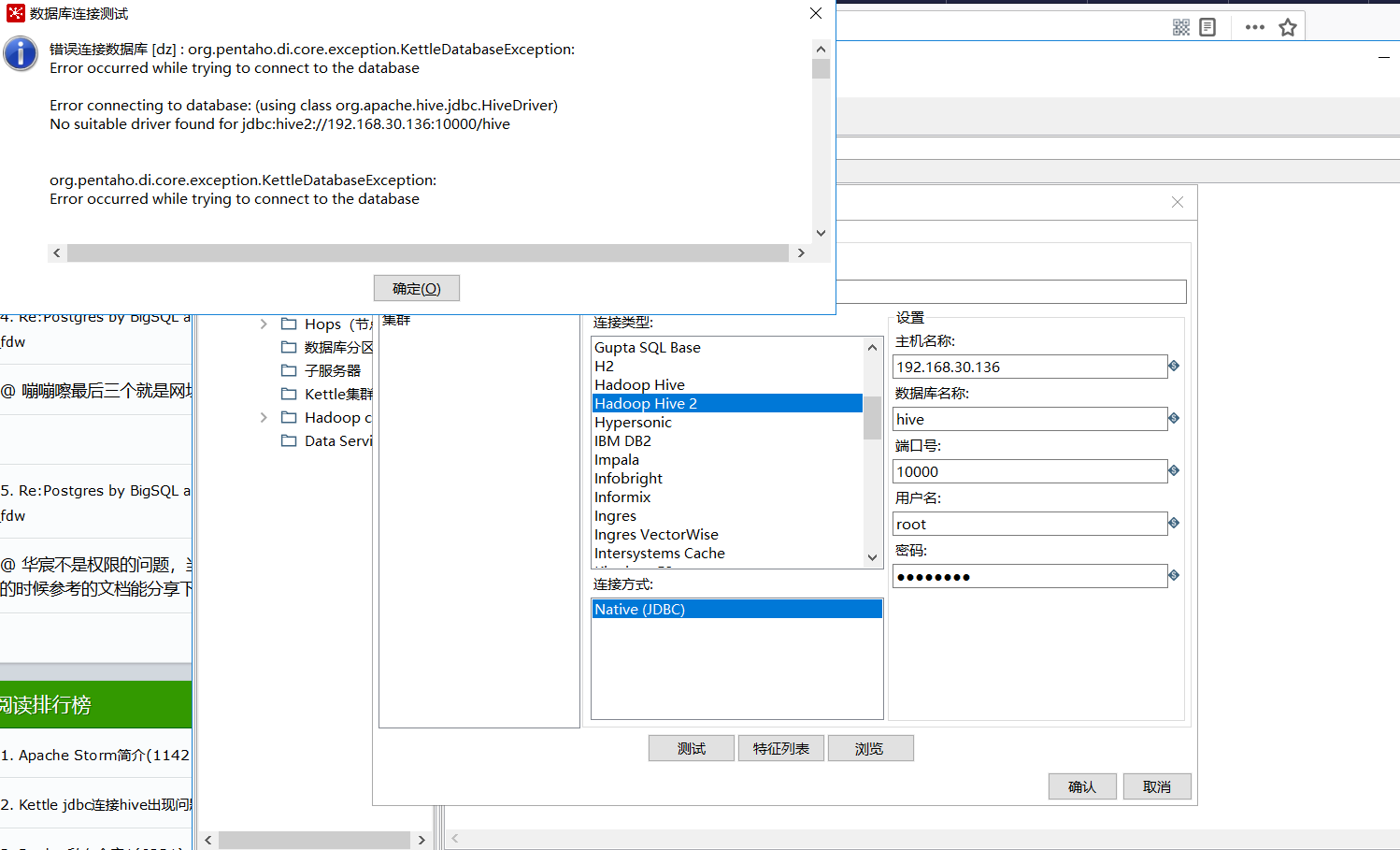
折腾很久才发现,原来是版本不匹配
因为kettle连接hadoop集群,分为连接CDH还是apache hadoop,从目录\data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations 就可以看出,每个版本的kettle只能连接该目录下指定的集群版本,因为 pentaho-hadoop-shims*.jar 这个文件的是用来匹配kettle和集群版本的,不能随意搭配。因为官网上的shims版本是有限的。(https://sourceforge.net/projects/pentaho/files/Big%20Data%20Shims)
故,卸载了最新的kettle8.2版本,在以上官网上下载了shims文件匹配的kettle,因为我的集群是cdh5.8.2, 更换集群版本太费力,就按照文件名字 pentaho-hadoop-shims-cdh58-package-70.2016.10.00-25-dist.zip
找到了匹配的kettle版本7.0(文件中的70既是kettle版本号),文件名中的cdh58是指CDH 5.8.*版本。
好了,下载kettle 7.0 (镜像地址:http://mirror.bit.edu.cn/pentaho/),解压后:
只有一个 data-integration 目录,开始配置连接hive
1. 下载hive的配置文件:
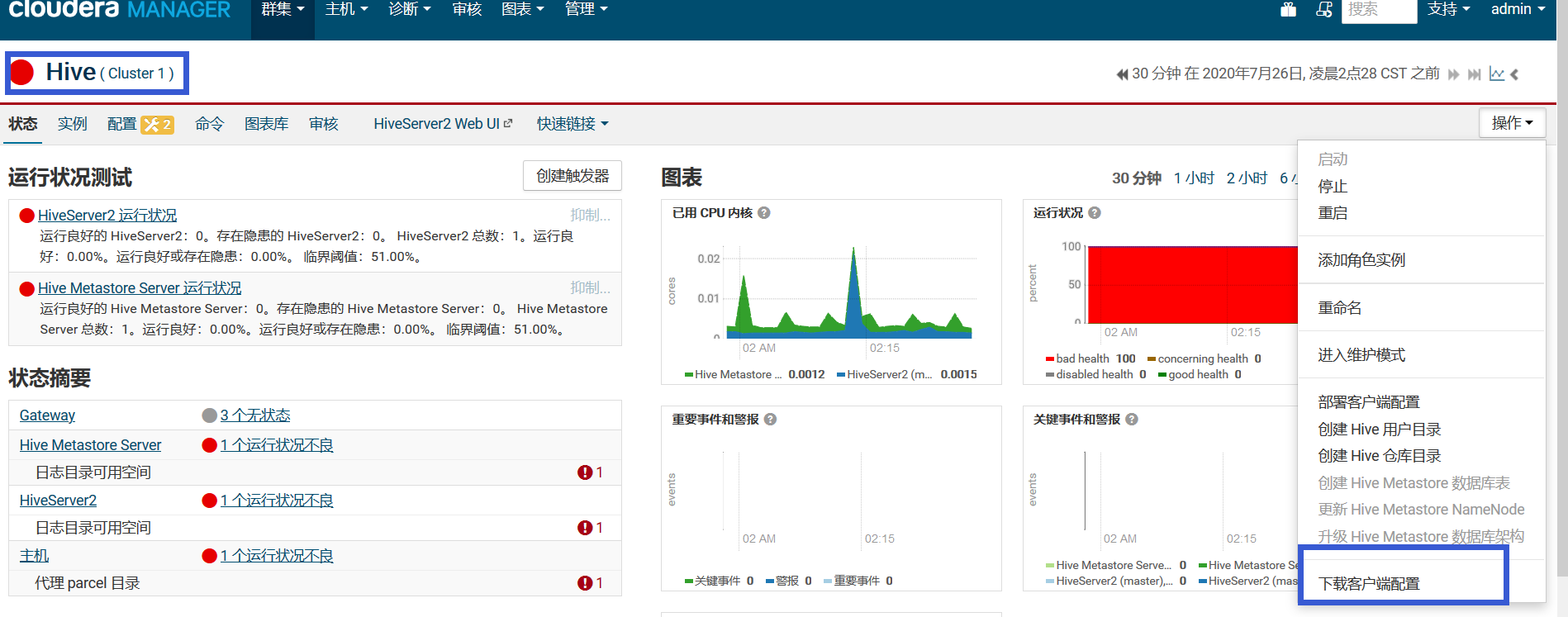
将hive-conf配置目录下的以下四个文件复制
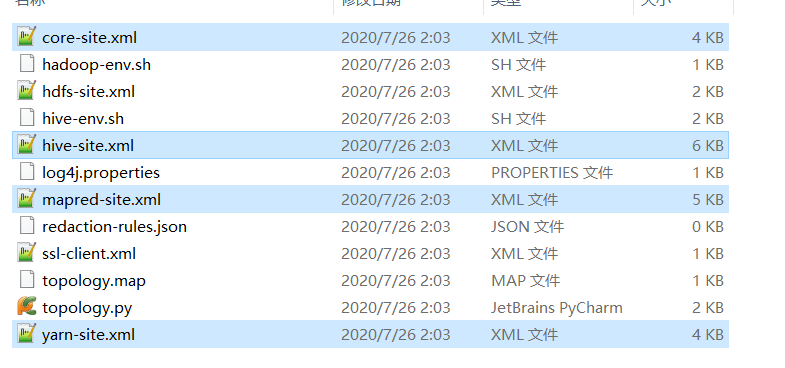
覆盖替换 kettle目录下data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\cdh58 的 四个同名文件。(本以为还需要去官网下shims文件,惊喜的发现在这个目录中已经存在了 pentaho-hadoop-shims-cdh58-70.2016.10.00-25.jar)
2. 修改data-integration\plugins\pentaho-big-data-plugin 目录下的 plugin.properties 文件中的配置项,指定要使用的集群配置是哪个。

3 . 所需jar包, 有些说需要下载hive中的所有关于hive的jar包,其实在这里不用,只需要在集群中下载 hadoop-core*.jar和hadoop-common*.jar 两个包,放入一下目录

放上依赖jar后,重启,测试成功。
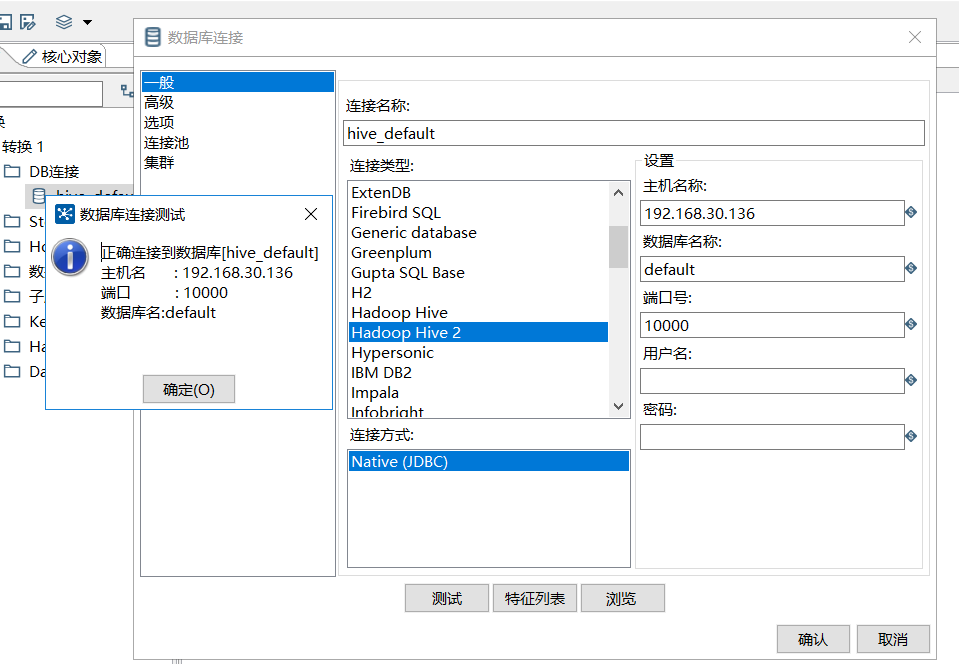
连接参数中,主机名是:hiveserver2服务所在主机的ip, 数据库名称 是 集群中hive中已经存在的某个db, 也就是你要读写的hive库。 端口号是hiveserver2默认开启的端口号,可以在hive的配置中查到是否是10000. 用户名密码 可以不用指定。
参考: https://blog.csdn.net/shipfei_csdn/article/details/103925063
https://www.cnblogs.com/cssdongl/p/6003449.html