1.题目
哈夫曼树的应用 要传输一则报文内容如下:
“AAAAAAAAAAAAAAABBBBBBBBBCCCCCCCCDDDDDDDDDDDDEEEEEEEEEEFFFFF”
请为这段报文设计哈夫曼编码,要求如下:
- 请计算出每个字符出现的概率,并以概率为权重来构造哈夫曼树,写出构造过程、画出 最终的哈夫曼树,得到每个字符的哈夫曼编码。
- 请将上述设计哈夫曼编码的过程,用代码来实现,并输出各个字母的哈夫曼编码。(有 代码,有运行结果的截图)
- 请分析算法的效率,至少包括时间复杂度和空间复杂度等。
2.分析题目
这段文长59,其中6个字符的个数和概率:
| 字符 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|
| 个数 | 15 | 9 | 8 | 12 | 10 | 5 |
| 概率 | 0.254 | 0.153 | 0.136 | 0.203 | 0.169 | 0.085 |
3.构建二叉树
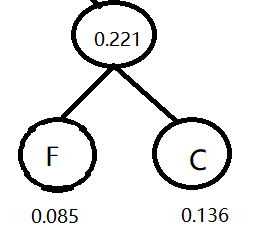
1)选择6个字母中概率最小的两个,C和F构成二叉树。然后就生成一个新结点,权值为0.221.
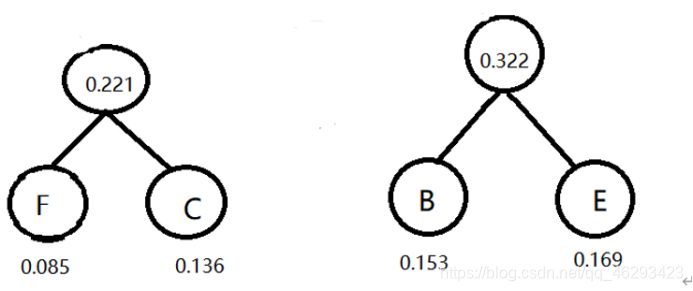
2)在剩下的字母和这个新结点中选择最小的两个结点,B,E生成新结点,权值为0.322。
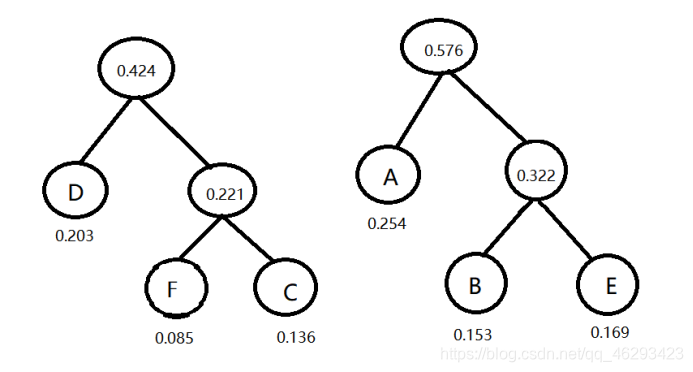
3)接着选出剩下的结点中最少的两个,0.221和D(0.203),又组合生成二叉树,产生新的结点0.424.

4)再选择剩下的结点中最小两个,0.321和A(0.254)生成新的二叉树,新结点0.576.
5)最后将两个二叉树组合起来,就是哈夫曼树。
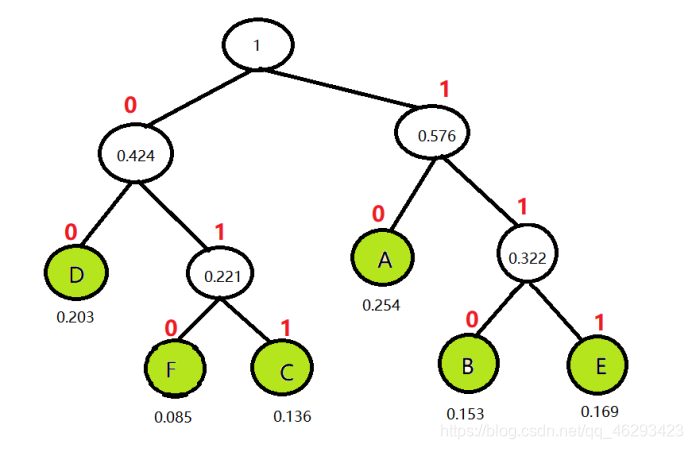
所以,编码为:
| 字符 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|
| 编码 | 10 | 110 | 011 | 00 | 111 | 010 |
4.代码
#include<stdio.h>
#include<string.h>
#define MAX 106
#define MAXLEAF 6 //定于哈夫曼树中叶子结点个数
#define MAXNODE MAXLEAF*2-1//n个叶子结点中又2n-1个结点
typedef struct
{
int weight; //结点权重
int parent,lchild,rchild;//双亲和左孩子、右孩子下标
}HTNode;
typedef struct code
{
int bits[MAXLEAF];
int start;
char ch;
}HTCode;
HTNode tree[MAXNODE];//数组二叉树
HTCode HFCode[MAXLEAF];//每个字母编码
void CreatHuffmanTree(int n,int weight[])//创建哈夫曼树数组
{
if(n<1) return;
int i,j;
for(i = 0; i < MAXNODE;i++)//初始化
{
tree[i].parent = 0;
tree[i].lchild = 0;
tree[i].rchild = 0;
}
for(i=0;i<n;i++)//输入前n个数的权值
{
tree[i].weight = weight[i];
}
/*---------------------初始化-------------------*/
for(i=MAXLEAF;i<MAXNODE;i++)
{
int m1 = MAX,m2 = MAX,t1=0,t2=0;
for(j=0;j<i;j++)//选择两个最小的权值,且双亲为0
{
if(tree[j].weight < m1 && tree[j].parent == 0)
{
m2 = m1;
t2 = t1;
m1 = tree[j].weight;
t1 = j;
}//m1是最小的权值,t1是他的位置
else if(tree[j].weight < m2 && tree[j].parent == 0)
{
m2 = tree[j].weight;
t2 = j;
}//m2是次小,t2是他的位置
}
tree[t1].parent = i;
tree[t2].parent = i;//新结点,从森林中删除t1,t2,把双亲由0改成i
tree[i].lchild = t1;
tree[i].rchild = t2;//新结点的孩子结点
tree[i].weight = tree[t1].weight + tree[t2].weight;//新结点的权值
printf("%d\n",tree[i].weight);
}
}
void HuffmanCode()//求字符的编码
{
int i,j,c,f;
/*初始化字符*/
HFCode[0].ch = 'A';
HFCode[1].ch = 'B';
HFCode[2].ch = 'C';
HFCode[3].ch = 'D';
HFCode[4].ch = 'E';
HFCode[5].ch = 'F';
for(i=0;i<MAXLEAF;i++)//求哈夫曼编码
{
HFCode[i].start = MAXLEAF;
c = i;
f = tree[i].parent;
while(f!=0)
{
HFCode[i].start--;//回溯第一次,从后往前
if(tree[f].lchild == c)
{
HFCode[i].bits[HFCode[i].start] = 0;//c是f的左孩子就为0
}
else
{
HFCode[i].bits[HFCode[i].start] = 1;//是右孩子就为1
}
c = f; //c向上移动
f = tree[f].parent; //f向上移动
}
}
for(i=0;i<MAXLEAF;i++)//输出
{
printf("字符 %c 权值为 %d,编码为:",HFCode[i].ch,tree[i].weight);
for(j=HFCode[i].start;j<MAXLEAF;j++)
{
printf("%d",HFCode[i].bits[j]);
}
printf("\n");
}
}
int main()
{
char str[100];
printf("输入电报内容:");
scanf("%s",str);
int count[10];//每个字母的出现次数
int weight[10];//每个字母的权值
int n = strlen(str);
//printf("%d\n",n);
int i,j;
for(i=0;i<MAXLEAF;i++)//初始化
{
count[i] = 0;
}
for(i=0;i<n;i++)//统计个数
{
switch(str[i])
{
case'A':
count[0]++;
break;
case'B':
count[1]++;
break;
case'C':
count[2]++;
break;
case'D':
count[3]++;
break;
case'E':
count[4]++;
break;
case'F':
count[5]++;
break;
}
}
for(i=0;i<MAXLEAF;i++)
{
weight[i] = (count[i]*1.0/n)*100;
}
CreatHuffmanTree(MAXLEAF,weight);
HuffmanCode();
return 0;
}