
六、Hive 自定义函数
在Hive当中又系统自带的函数,可以通过
show functions;语句查询系统现在已经存在函数。desc function upper;显示自带函数用法,desc function extended upper;详细显示自带函数用法。其系统中已经存在很多函数,但是这些往往不能满足生产需求,所以Hive保留了相关接口,以便用户日后去自定义函数去拓展相关的功能。
在Hive中,用户可以自定义一些函数,用于扩展HiveQL的功能,而这类函数叫做UDF(用户自定义函数)。UDF分为两大类:UDAF(用户自定义聚合函数)和UDTF(用户自定义表生成函数)。在介绍UDAF和UDTF实现之前,我们先在本章介绍简单点的UDF实现:UDF和GenericUDF,然后以此为基础介绍UDAF和UDTF的实现。
6.1 UDF
Hive有两个不同的接口编写UDF程序。一个是基础的UDF接口,一个是复杂的GenericUDF接口。
org.apache.hadoop.hive.ql. exec.UDF 基础UDF的函数读取和返回基本类型,即Hadoop和Hive的基本类型。如Text、IntWritable、LongWritable、DoubleWritable等。
org.apache.hadoop.hive.ql.udf.generic.GenericUDF 复杂的GenericUDF可以处理Map、List、Set类型。
@Describtion注解是可选的,用于对函数进行说明,其中的_FUNC_字符串表示函数名,当使用DESCRIBE FUNCTION命令时,替换成函数名。@Describtion包含三个属性:
name:用于指定Hive中的函数名。
value:用于描述函数的参数。
extended:额外的说明,例如当使用DESCRIBE FUNCTION EXTENDED name的时候打印。
6.1.1 准备数据
表结构
drop table logs;
create table
logs
(
userid string ,
fromUrl string ,
dateString string,
timeString string,
ipAddress string,
browserName string,
pcSystemNameOrmobileBrandName string ,
systemVersion string,
language string,
cityName string
)
partitioned BY (day string)
row format delimited fields terminated
by ' ';
导入数据
load data inpath '/clean.log' into table logs partition(day='19-06-19');
部分数据展示
a1b21e96-01d8-47ca-b343-2fb7a7172701 http://192.168.123.129:1211/Test/index.jsp 2019-06-19 23:19:26 223.71.30.3 Chrome MI-8) Android-9 zh-CN CHINA 19-06-19
6.1.2 编写Java类
这里是真正的写自定义函数的逻辑,首先需要设计一下自定义函数的逻辑。
想要实现的效果(当然这个可以自行定义):比如说查询userid(名字) 和城市,
输出 你好 userid ,pcSystemNameOrmobileBrandName 好玩吗?
环境
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.2</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
出现的问题

看上图,阿里云代理的中心仓库无法下载这个依赖,这也就意味着最经常使用的几大Maven仓库也无法下载,所有在几经周折后,找到了发布这个依赖的私服(私服中也有其他依赖,可以直接使用)
解决办法
pentaho私服WEB地址 :https://public.nexus.pentaho.org/
办法1
通过所有就可以下载到当前这个缺失依赖
缺点:麻烦 优点:无需再去校验或者下载其他的Jar包
mvn install:install-file -DgroupId=org.pentaho -DartifactId=pentaho-aggdesigner-algorithm -Dversion=5.1.5-jhyde -Dpackaging=jar -Dfile=pentaho-aggdesigner-algorithm-5.1.5-jhyde-javadoc.jar
mvn 需要配置环境变量
-Dfile 需要指定正确的路径
办法2
将阿里云的镜像替代为pentaho镜像,打开xml文件
但是地址怎么写?
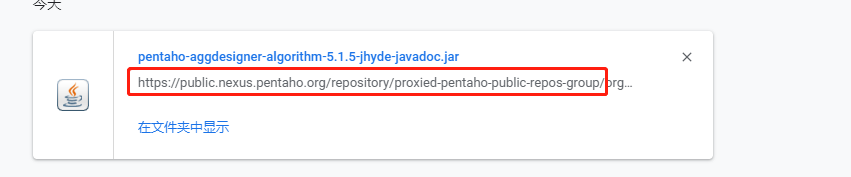
https://public.nexus.pentaho.org/repository/proxied-pentaho-public-repos-group/org/pentaho/pentaho-aggdesigner-algorithm/5.1.5-jhyde/pentaho-aggdesigner-algorithm-5.1.5-jhyde-javadoc.jar

上述连接中是下载缺失依赖的jar,可以看到从org之前都是其公共仓库的连接了,所在在你的xml文件中去除阿里云的依赖,添加下方镜像即可
<mirror>
<id>nexus-pentaho</id>
<mirrorOf>*</mirrorOf>
<name>Nexus pentaho</name>
<url>https://public.nexus.pentaho.org/repository/proxied-pentaho-public-repos-group/</url>
</mirror>
但是,此种方法需要重新将你的其他依赖再进行一次校验或者下载 ,也有其局限性
真正的代码
package io.csdn.udf;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDF;
/**
* Create by GuoJF on 2019/6/19
*/
@Description(
name = "hello",
value = "_FUNC_(str1,str2) - from the input string"
+ "returns the value that is \"你好 $str1 ,$str2 好玩吗? \" ",
extended = "Example:\n"
+ " > SELECT _FUNC_(str1,str2) FROM src;"
)
public class HelloUDF extends UDF {
public String evaluate(String str1,String str2){
try {
return "Hello " + str1+", "+str2 +" 好玩吗?";
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
return "ERROR";
}
}
}
6.1.3添加功能
本地生成Jar包,并且上传至Linux服务器,进入Hive命令行
hive>ADD jar /root/Hive_Test-1.0-SNAPSHOT.jar
hive> CREATE TEMPORARY FUNCTION hello AS "com.rechen.udf.HelloUDF";
6.1.4展示效果
select hello(userid,pcSystemNameOrmobileBrandName) from logs;
部分效果如下:
Hello f8b13cf1-f601-4891-ab3b-ca06069a9f41, CHINA 好玩吗?
Hello f8b13cf1-f601-4891-ab3b-ca06069a9f41, CHINA 好玩吗?
6.2 GenericUDF(了解)
org.apache.hadoop.hive.ql.udf.generic.GenericUDF 复杂的GenericUDF可以处理Map、List、Set类型。
Serde是什么:Serde实现数据序列化和反序列化以及提供一个辅助类ObjectInspector帮助使用者访问需要序列化或者反序列化的对象。
6.3 UDTF(了解)
用户自定义表生成函数(UDTF)。用户自定义表生成函数(UDTF)接受零个或多个输入,然后产生多列或多行的输出,如explode()。要实现UDTF,需要继org.apache.hadoop.hive.ql.udf.generic.GenericUDTF,同时实现三个方法:
//该方法指定输入输出参数:输入的Object Inspectors和输出的Struct。
1. abstract StructObjectInspector initialize(ObjectInspector[] args) throws UDFArgumentException;
//该方法处理输入记录,然后通过forward()方法返回输出结果。
2. abstract void process(Object[] record) throws HiveException;
//该方法用于通知UDTF没有行可以处理,可以在该方法中清理代码或者附加其他处理输出。
3. abstract void close() throws HiveException;
6.4 UDAF (了解)
用户自定义聚合函数(UDAF)接收从零行到多行的零个到多个列,然后返回单一值,如sum()、count()。要实现UDAF,我们需要实现下面的类:
org.apache.0.hive.ql.udf.generic.AbstractGenericUDAFResolver
org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator
AbstractGenericUDAFResolver检查输入参数,并且指定使用哪个resolver。在AbstractGenericUDAFResolver里,只需要实现一个方法:
Public GenericUDAFEvaluator getEvaluator(TypeInfo[] parameters) throws SemanticException;
但是,主要的逻辑处理还是在evaluator中。我们需要继承GenericUDAFEvaluator,并且实现下面几个方法:
//输入输出都是Object inspectors
public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException;
//AggregationBuffer保存数据处理的临时结果
abstract AggregationBuffer getNewAggregationBuffer() throws HiveException;
//重新设置AggregationBuffer
public void reset(AggregationBuffer agg) throws HiveException;
//处理输入记录
public void iterate(AggregationBuffer agg, Object[] parameters) throws HiveException;
//处理全部输出数据中的部分数据
public Object terminatePartial(AggregationBuffer agg) throws HiveException;
//把两个部分数据聚合起来
public void merge(AggregationBuffer agg, Object partial) throws HiveException;
//输出最终结果
public Object terminate(AggregationBuffer agg) throws HiveException;
在给出示例之前,先看下UADF的Enum GenericUDAFEvaluator.Mode。Mode有4中情况:
1. PARTIAL1:Mapper阶段。从原始数据到部分聚合,会调用iterate()和terminatePartial()。
2. PARTIAL2:Combiner阶段,在Mapper端合并Mapper的结果数据。从部分聚合到部分聚合,会调用merge()和terminatePartial()。
3. FINAL:Reducer阶段。从部分聚合数据到完全聚合,会调用merge()和terminate()。
4. COMPLETE:出现这个阶段,表示MapReduce中只用Mapper没有Reducer,所以Mapper端直接输出结果了。从原始数据到完全聚合,会调用iterate()和terminate()。
6.5 Hive函数综合案例
6.5.1 实现列自增长
Java代码
package io.rechen.udf;
/**
* Create by rechen on 2020/7/20
*/
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.hive.ql.udf.UDFType;
import org.apache.hadoop.io.LongWritable;
/**
* UDFRowSequence.
*/
@Description(name = "row_sequence",
value = "_FUNC_() - Returns a generated row sequence number starting from 1")
@UDFType(deterministic = false)
public class RowSequence extends UDF {
private LongWritable result = new LongWritable();
public RowSequence() {
result.set(0);
}
public LongWritable evaluate() {
result.set(result.get() + 1);
return result;
}
}
导入函数
打Jar包上传至Linux服务器,并在Hive命令行中输出如下指令
hive> add jar /root/Hive-1.0-SNAPSHOT.jar
hive> create temporary function row_sequence as 'com.rechen.udf.RowSequence';
查询数据
SELECT row_sequence(), userid FROM logs;
效果展示

6.5.2 数据合并
需求描述
假设我们在Hive中有两张表,其中一张表是存用户基本信息,另一张表是存用户的地址信息等
user_basic_info 表信息
| id | name |
|---|---|
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | d |
user_address_info 表信息
| name | address |
|---|---|
| a | add1 |
| a | add2 |
| b | add3 |
| c | add4 |
| d | add5 |
我们希望得到这样的结果:
| id | name | address |
|---|---|---|
| 1 | a | add1,add2 |
| 2 | b | add3 |
| 3 | c | add4 |
| 4 | d | add5 |
建表
创建user_basic_info
user_basic_info
create table user_basic_info(id string,name string)
row format delimited fields terminated
by ' ';
1 a
2 b
3 c
4 d
load data local inpath '/root/user_basic_info' overwrite into table user_basic_info;
创建user_address_info
user_address_info
create table user_address_info(name string,address string)
row format delimited fields terminated
by ' ';
a add1
a add2
b add3
c add4
d add5
load data local inpath '/root/user_address_info' overwrite into table user_address_info;
select max(a.id), a.name, concat_ws('|', collect_set(b.address)) as address from user_basic_info a join user_address_info b on a.name=b.name group by a.name;
max的作用取当前组中其中的一个值 当然min等这样的函数也行
结果

数据合并
创建新表 user_all_info
create table user_all_info(id string,name string,address string)
row format delimited fields terminated
by ' ';
执行插入语句
insert into table user_all_info select max(a.id), a.name, concat_ws('|', collect_set(b.address)) as address from user_basic_info a join user_address_info b
on a.name=b.name group by a.name;
最终结果

献给每一个正在努力的我们,就算在忙,也要注意休息和饮食哦!我就是我,一个在互联网跌跌撞撞,摸爬滚打的热忱,给个三连吧~ 还有就是不要只看,多动手才行!努力呀!