前言:《Python核心编程》读书笔记,我可太爱这本书了,这篇读书笔记里面只记录了一些较为常用的板块,方便我以后复习查看!!!
文章目录
什么是正则表达式
我看来最大的作用就是,爬虫或者过滤非法字符
正则表达式为高级的文本模式匹配、抽取、与/或文本形式的搜索和替换功能提供了基础。
简单地说,正则表达式(简称为 regex)是一些由字符和特殊符号组成的字符串,它们描述了
模式的重复或者表述多个字符,于是正则表达式能按照某种模式匹配一系列有相似特征的字
符串。换句话说,它们能够匹配多个字符串……一种只能匹配一个字符串的正则
表达式模式是很乏味并且毫无作用的,不是吗?
Python 通过标准库中的 re 模块来支持正则表达式。本节将做一个简短扼要的介绍。
元字符
| 表示法 | 描述 | 实例 |
|---|---|---|
| literal | 匹配文本字符串的字面值 literal | foo |
| re1|re2 | 匹配正则表达式 re1 或者 re2 | foo/bar |
| . | 匹配任何字符(除了\n 之外) | b.b |
| ^ | 匹配字符串起始部分 | ^Dear |
| $ | 匹配字符串终止部分 | /bin/*sh$ |
| * | 匹配 0 次或者多次前面出现的正则表达式 | [A-Za-z0-9]* |
| + | 匹配 1 次或者多次前面出现的正则表达式 | [a-z]+.com |
| ? | 匹配 0 次或者 1 次前面出现的正则表达式 | goo? |
| {N} | 匹配 N 次前面出现的正则表达式 | [0-9]{3} |
| {M,N} | 匹配 M~N 次前面出现的正则表达式 | [0-9]{5,9} |
| […] | 匹配来自字符集的任意单一字符 | [aeiou] |
| […x−y…] | 匹配 x~y 范围中的任意单一字符 | [0-9], [A-Za-z] |
| [^…] | 不匹配此字符集中出现的任何一个字符,包括某一范围的字符(如果在此字符集中出现) | [^aeiou], [^A-Za-z0-9] |
| (*|+|?|{})? | 用于匹配上面频繁出现/重复出现符号的非贪婪版本(*、+、?、{}) | .*?[a-z] |
| (…) | 匹配封闭的正则表达式,然后另存为子组 | ([0-9]{3})?,f(oo |
特殊字符
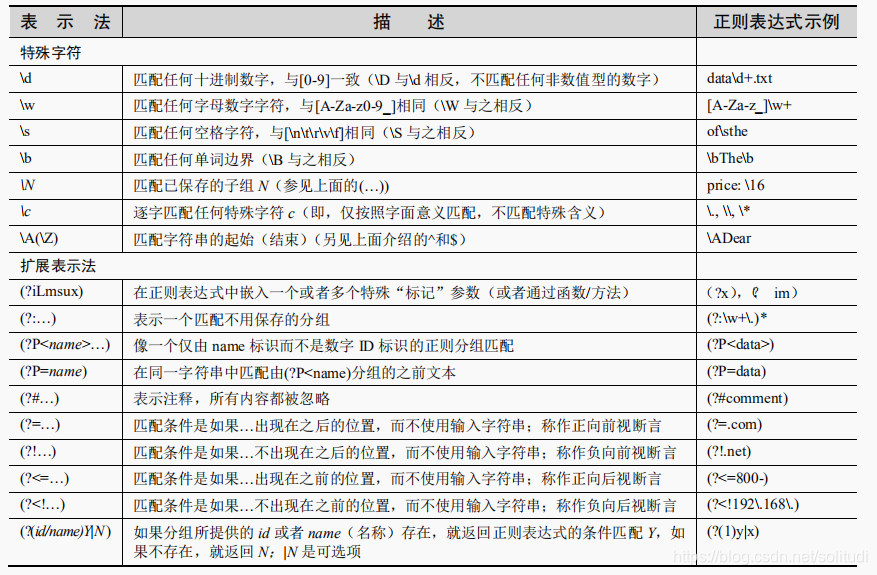
使用圆括号指定分组(重点)
当使用正则表达式时,一对圆括号可以实现以下任意一个(或者两个)功能:
• 对正则表达式进行分组;
• 匹配子组。
为什么匹配子组这么重要呢?主要原因是在很多时候除了进行匹配操作以外,我们还想要提取所匹配的模式。例如,如果决定匹配模式\w±\d+,但是想要分别保存第一部分的字母,和第二部分的数字,如果为两个子模式都加上圆括号,例如(\w+)-(\d+),然后就能够分别访问每一个匹配
子组。
扩展表示法
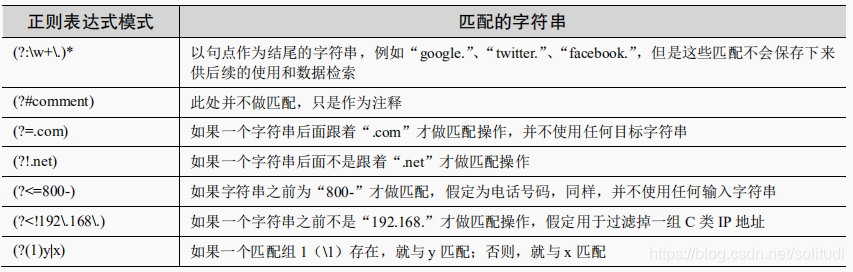
看起来暂时不太清楚的语句截图方便复习

懂了匹配字符
Python的re
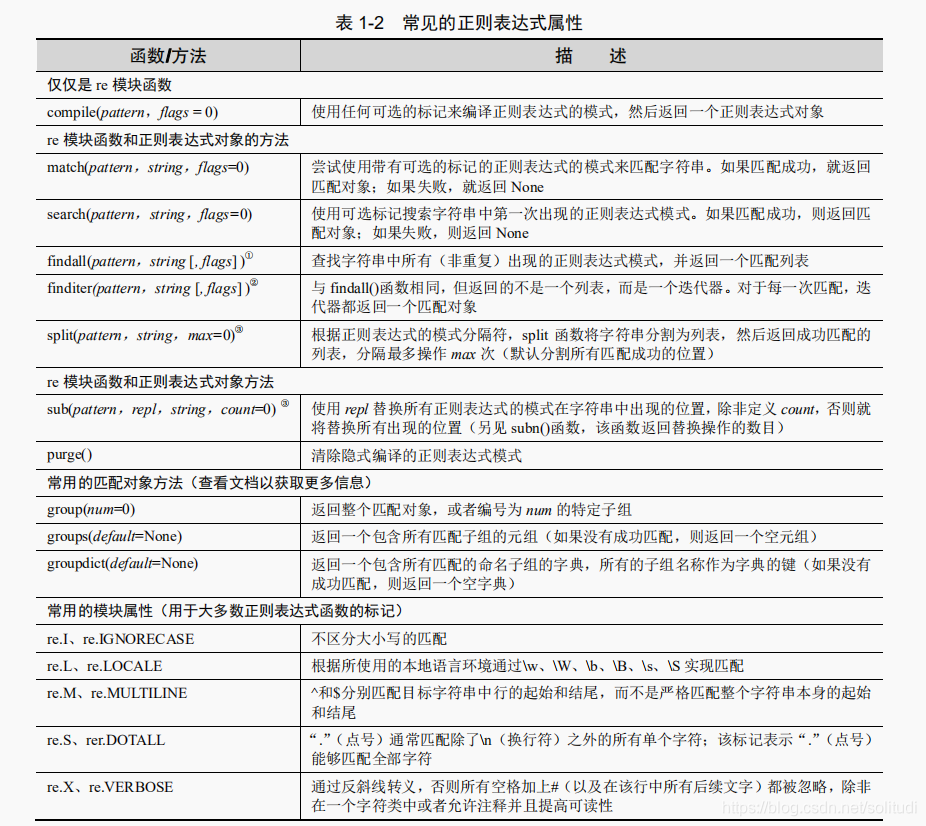
使用 match()方法匹配字符串
match()
函数试图从字符串的起始部分对模式进行匹配。如果匹配成功,就返回一个匹配对象;如果匹配失败,就返回 None,匹配对象的 group()方法能够用于显示那个成功的匹配
import re
a = re.match("aa\w*","aaaccc")
print(a.group())
使用 search()在一个字符串中查找模式(搜索与匹配的对比)
其实,想要搜索的模式出现在一个字符串中间部分的概率,远大于出现在字符串起始部分的概率。这也就是 search()派上用场的时候了。search()的工作方式与 match()完全一致,不同之处在于 search()会用它的字符串参数,在任意位置对给定正则表达式模式搜索第一次出现的匹配情况。如果搜索到成功的匹配,就会返回一个匹配对象;否则,返回 None。
import re
a = re.search("aa\w*","aaaccc")
print(a)
print(a.group())
group()与groups()
group()要么返回整个匹配对象,要么根据要求返回特定子组。groups()则仅返回一个包含唯一或者全部子组的元组。如果没有子组的要求,那么当group()仍然返回整个匹配时,groups()返回一个空元组。


匹配字符串的起始和结尾以及单词边界
