提前先把今天的文章发了,估计没有时间,要是有时间,还会坚持今天的发文。
我这是用自己的数据文件做的,如果有朋友需要的话,私聊我。
我的数据文件有一百多行,太长了就不全部展示了。

老规矩,上代码:
第一步,先导入会用到的库和库函数。
第二步,处理文件。

结果:

第三步,用SelectPercentile()函数做特征选择
特征1:

结果:

特征2:

结果:

特征3:

结果:

特征4:

结果:

接着使用sklearn的LDA进行维度转换。

结果:

然后,使用sklearn的GBDT组合特征。

结果:

模型采用默认的GBDT的参数。

然后,使用sklearn的PolynomialFeatures方法组合特征。

结果:
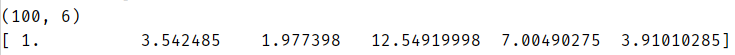
最后,加载数据集。

结果:

最后,感谢大家前来阅读鄙人的文章,不胜感激,文中或有诸多不妥之处,还望指出和海涵。