java集合
集合概述
java的集合类主要由两个接口派生而出:Collection和Map
Collection集合体系的继承树:

Map体系的继承树:

java11为Collection新增了一个toArray(IntFunction)方法,使用该方法的主要目的就是利用泛型,传统的toArray()方法不管Collection本身是否使用泛型,toArray()的返回值总是Object[];但新增的toArray(IntFunction)方法不同,当Collection使用泛型时,toArray(IntFunction)可以返回特定类型的数组。
var strColl = List.of("Java","Kotlin","Swift","Python");
//toArray()方法是一个Lambda表达式,代表IntFunction对象
//此时toArray()方法的返回值类型是String[],而不是Object[]
String[] sa = strColl.toArray(String[]::new);
System.out.println(Arrays.toString(sa));
使用Lambda表达式遍历集合
public class CollectionEach{
public static void main(String[] args){
var books = new HashSet();
books.add("轻量级");
books.add("疯狂java讲义");
books.add("疯狂Android讲义");
//调用forEach()方法遍历集合
books.forEach(obj -> System.out.println("迭代集合元素:" + obj));
}
}
上面代码调用了Iterable的forEach()默认方法来遍历集合元素,参数为Lambda表达式,该表达式目标类型是Consumer,forEach()方法会自动将集合元素逐个的传递给Lambda表达式的形参,这样Lambda表达式的代码体即可遍历到集合元素了。
使用iterator遍历集合元素
Iterator接口隐藏了各种Collection实现类的底层细节,向应用程序提供了遍历Collection集合元素的统一编程接口。
Iterator接口里定义了如下4个方法:
1.boolean hasNext():如果被迭代的集合元素还没有被遍历完,则返回true.
2.Object next():返回集合里的下一个元素
3.void remove():删除集合里上一次next方法返回的元素。
4.void forEachRemaining(Consumer action),java8为Iterator新增的默认方法, 可以使用Lambda表达式来遍历集合元素。
PS :Iterator必须依附于Collection对象,若有一个Iterator对象,则必然有一个与之关联的Collection对象,Iterator提供了两个方法来迭代访问Collection集合里的元素,并可通过remove()方法来删除集合中上一次next()方法返回的集合元素。
当使用Iterator迭代访问Collection集合元素时,Collection集合里的元素不能被改变,只有通过Iterator的remove()方法删除上一次next()方法返回的集合元素才可以;否则将会引发java.util.ConcurrentModificationException异常。
例子如下:
public class IteratorErrorTest{
public static void main(String[] args){
var books = new HashSet();
books.add("轻量级");
books.add("疯狂java讲义");
books.add("疯狂Android讲义");
//调用forEach()方法遍历集合
books.forEach(obj -> System.out.println("迭代集合元素:" + obj));
var it = bboks.iterator();
while(it.hasNext()){
var book = (String) it.next();
System.out.println(book);
if(book.equals("疯狂java讲义")){
//使用Iterator迭代过程中,不可修改集合元素,下面代码引发异常
books.remove(book);
}
}
}
}
Iterator迭代器采用的是(fail-fast)机制,一旦在迭代过程中检测到该集合已经被修改(通常是程序中的其他线程修改),程序立即引发ConcurrentModificationException异常,而不是显示修改后的结果,这样可以避免资源共享而引发的潜在问题。
使用Predicate操作集合
java8为Collection集合新增了一个removeIf(Predicate filter)方法,该方法将会批量删除符合filter条件的所有元素。
该方法需要一个Predicate(谓词)对象作为参数,Predicate也是函数式接口,因此可使用Lambda表达式作为参数。
下面程序示范利用Predicate来过滤集合:
var books = new HashSet();
books.add("疯狂java");
books.add("Hadoop从入门到精通");
books.add("数据结构");
books.removeIf(ele -> ((String)ele).length() < 10);
System.out.println(books);
上面程序传入一个Lambda表达式作为过滤条件将所有长度小于10的字符串元素都删除。
使用Predicate可以充分简化集合的运算,需求如下:
1.统计书名中出现“疯狂”字符串的图书数量
2.统计书名长度大于10的图书数量
传统变成此处需要执行两次循环,但采用Predicate只需要一个方法即可。
示例如下:
public class PredicateTest2{
public static void main(String[] args){
var books = new HashSet();
books.add("疯狂java");
books.add("Hadoop从入门到精通");
books.add("数据结构");
System.out.println(calAll(books,ele->((String)ele).conains("疯狂")));
System.out.println(calAll(books,ele->((String)ele).length() > 10)));
}
public static int calAll(Collection books,Predicate p){
int total = 0;
for(var obj : books){
if(p.test(obj)){
total++;
}
}
return total;
}
}
程序传入了两个Lambda表达式,其目标类型都是Predicate类型,这样calAll()方法就只会统计满足条件的图书了。
使用Stream操作集合
Set集合
HashSet类
HashSet特点:
1.不能保证元素的排列顺序,顺序可能与添加顺序不同,顺序也有可能发生变化。
2.HashSet不是同步的,如果多个线程同时访问一个HashSet,假设有两个或两个以上线程同时修改了HashSet集合时,则必须通过代码来保证其同步。
3.集合元素值可以是null。
HashSet添加元素机制:
当向HashSet集合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据该hashCode值决定该对象在HashSet中的存储位置,如果有两个元素通过equals()方法比较返回true,但它们的hashCode()方法返回值不相等,HashSet将会把它们存储在不同的位置,依然可以添加成功。
HashSet集合判断两个元素相等的标准是两个对象通过equals()方法比较相等,并且两个对象的hashCode()方法返回值也相等。
PS :如果两个对象的hashCode()方法返回的hashCode值相同,但它们通过equals()方法比较返回false时,会在这个位置用连式结构来保存多个对象;而HashSet访问集合元素时也是根据元素的hashCode值快速定位的,如果HashSet中两个以上的元素具有相同的hashCode值,将会导致性能下降。
重写hashCode()方法的基本规则:
1.在程序运行过程中,同一个对象多次调用hashCode()方法应该返回相同的值。
2.当两个对象通过equals()方法比较返回true时,这两个对象的hashCode()方法应返回相等的值。
3.对象中用作equals()方法比较标准的实例变量,都应该用于计算hashCode值。
重写hashCode()方法的一般步骤:
1.把对象内每个有意义的实例变量(即每个参与equals()方法比较标准的实例变量)计算出一个int乐行的hashCode值。
计算方式如下表:
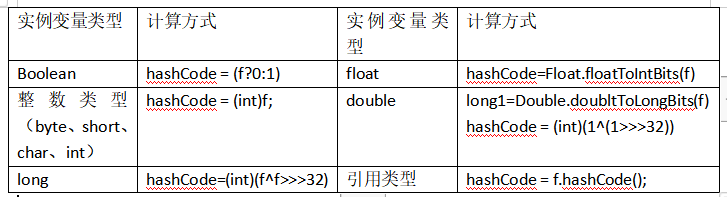
2.用第一步计算出来的多个hashCode值组合计算出一个hashCode值返回。
return f1.hashCode() + (int)f2;
LinkedHashSet类
集合也是根据元素的hashCode值来决定元素的存储位置,但同时使用链表维护元素的次序。性能略低于HashSet的性能,但迭代访问Set里的全部元素时,性能较好,输出元素的顺序与添加顺序一致。
TreeSet类
TreeSet并不是根据元素的插入顺序进行排序的,而是根据元素实际值的大小来进行排序的,TreeSet采用红黑树的数据结构来存储集合元素,支持自然排序和定制排序,默认情况下,TreeSet采用自然排序。
1.自然排序
定义:TreeSet会调用集合元素的compareTo(Object obj)方法来比较元素之间的大小关系,然后将集合元素按升序排列,这种方式就是自然排序。
PS :如果把一个对象添加到TreeSet时,则该对象的类必须实现Comparable接口,否则程序将会抛出异常。
TreeSet重写equals()方法时,一定注意方法与compareTo(Object obj)方法有一致的结果。equal()返回true,comapreTo()返回0。
实现了Comparable接口的常用类:
BigDecimal、BigInteger以及所有的数值型对应的包装类;按他们对应的数值大小进行比较。
Character:按字符的Unicode值进行比较。
Boolean:true对应的包装类实例大于false对应的包装类实例。
String:依次比较字符串中每个字符的Unicode值。
Date、Time:后面的时间、日期比前面的时间、日期大。
如果希望TreeSet正常运作,TreeSet只能添加同一种类型的对象。
TreeSet可以删除没有被修改实例变量、且不与其他被修改实例变量的对象重复的对象。
2.定制排序
如果需要定制排序,比如降序排列,可以通过Comparator接口里包含的int compare(T o1,T o2)方法,该方法用于比较o1和o2的大小,如果返回正整数,则o1 > o2,如果返回0,则o1 = o2;如果返回负整数,则o1 < o2
在创建TreeSet集合对象时,提供一个Comparator对象与该TreeSet集合关联,由该Comparator对象负责集合元素的排序逻辑,Comparator对象是一个函数式接口,因此可用Lambda表达式来代替Comparator对象。
class M{
int age;
public M(int age){
this.age = age;
}
public String toString(){
return "M [age:" + age + "]";
}
}
public class TreeSetTest4{
var ts = new TreeSet((o1,o2)->{
var m1 = (M)o1;
var m2 = (M)o2;
return m1.age > m2.age ? -1 :m1.age < m2.age ? 1 : 0;});
ts.add(new M(5));
ts.add(new M(-3));
ts.add(new M(9));
System.out.println(ts);
}
上述代码使用了目标类型为Comparator的Lambda表达式,负责ts集合的排序,所以把M对象添加到ts集合中时,无需M类实现Comparator几口,因为此时TreeSet无需通过M对象本身来比较大小。
EnumSet类
EnumSet是一个专为枚举类设计的集合类,EnumSet中的所有元素都必须是指定枚举类型的枚举值,其集合元素也是有序的,EnumSet以枚举值在Enum类内的定义顺序来决定集合元素的顺序。
EnumSet在内部以位向量的形式存储,这种存储形式非常紧凑、高效,因此EnumSet对象占用内存很小,而且运行效率很好,尤其进行批量操作(比如containsAll()和retainAll()方法)时,如果其参数也是EnumSet集合,该批量操作的执行速度也非常快。
EnumSet不允许加入null元素,试图插入null元素,抛出空指针异常,试图删除null元素将返回false。
各类Set实现类的性能分析
HashSet性能总比TreeSet好(特别是最常用的添加、查询元素等操作),因为TreeSet需要额外的红黑树算法来维护集合元素的次序。
只有当需要一个保持排序的Set时,才应该使用TreeSet,否则都应该使用HashSet。
HashSet还有一个自类:LinkedHashSet,对于普通的插入、删除操作,LinkedHashSet比HashSet略慢一点,是由维护链表所带来的额外开销造成的,但由于有了链表,遍历LinkedHashSet会更快。
EnumSet是所有Set实现类里性能最好的,但它只能保存同一个枚举类的枚举值作为集合元素。
PS :Set的三个实现类HashSet、TreeSet、EnumSet都是线程不安全的,如果多个线程同时访问一个Set集合,并且有超过一个线程修改了Set集合,则必须手动保证该Set集合的同步性,通常利用Collections工具类的synchronizedSortedSet方法来包装该Set集合。
例如:
SortedSet s = Collections.synchronizedSortedSet(new TreeSet())
List集合
List集合代表一个元素有序、可重复的集合,集合中每个元素都有其对应的顺序索引,可以通过索引来访问指定位置的集合元素,List集合默认按元素的添加顺序设置元素的索引。
改进的List接口和ListIterator接口
void add(int index,Object element):将元素element插入到List集合的index处。
boolean addAll(int index,Collection c):将集合c所包含的所有元素都插入到List集合的index处。
int indexOf(Object o):返回对象o在List集合中第一次出现的位置索引
List subList(int fromIndex,int toIndex):返回从索引fromIndex(包含)到索引toIndex(不包含)处所有集合元素组成的自己和。
void replaceAll(UnaryOperator operator):根据operator指定的计算规则重新设置List集合的所有元素。
java8为List集合增加了sort()和replaceAll()两个常用的默认方法,sort方法需要一个Comparator对象来控制元素排序,使用Lambda表达式来作为参数;replaceAll()方法需要一个UnaryOperator来提花你所有集合元素,UnaryOperator也是一个函数式接口,可以使用Lambda表达式作为参数。
与Set只提供一个iterator()方法不同,List还额外提供了一个listIterator()方法,该方法返回一个ListIterator对象,ListIterator接口继承了 Iterator接口,提供了专门操作List的方法,并增加了
boolean hasPrevious():返回该迭代器关联的集合是否还有上一个元素。
object previous():返回该迭代器的上一个元素。
ListIterator与普通的Iterator进行对比,增加了向前迭代的功能(Iterator只能向后迭代),而且ListIterator还可通过add()方法向List集合中添加元素(Iterator只能删除元素)。
ArrayList
详情见ArrayList和LinkedList的区别笔记
ArrayList和LinkedList的区别(内含源码解析)
固定长度的List
Arrays工具类里提供了asList(Object …a)方法,该方法可以把一个数组或指定个数的独享转换成一个List集合,这个List集合既不是ArrayList实现类的实例,也不是Vector实现类的实例,而是Arrays的内部类ArrayList的实例。
Arrays.ArrayList是一个固定长度的List集合,程序整年遍历访问集合元素,不能增加、删除结合里的元素。
Queue集合
PriorityQueue实现类
PriorityQueue保存队列元素的顺序是按队列元素的大小进行重新排序,而且PriorityQueue不允许插入null元素。
PriorityQueue有两种排序方式:
1.自然排序:采用自然顺序的PriorityQueue集合中的元素碧玺实现了Comparable接口,而且应该是同一个类的多个实例,否则可能抛出类型转换异常。
2.定制排序:创建PriorityQueue队列时,传入一个Comparable对象,该对象负责对队列中的所有元素进行排序,采用定制排序时,不要求队列元素实现Comparator接口。要求与TreeSet对元素的要求基本一致。
Deque接口与ArrayDeque实现类
Deque接口时Queue接口的子接口,它代表一个双端队列,Deque接口里定义了一些双端队列的方法,这些方法允许从两端来操作队列的元素。
Deque接口提供了一个典型的实现类:ArrayDeque,它是一个基于数组实现的双端队列,创建Deque时同样可指定一个numElements参数,该参数用于指定Object[]数组的长度,如果不指定numElements参数,Deque底层数组的长度为16。
ArrayList和ArrayDeque两个集合类的实现机制基本相似,底层都采用一个动态的、可重分配的Object[]数组来存储集合元素,当集合元素超出了该数组的容量时,系统会从新分配一个Object[]数组来存储集合元素。
ArrayDeque不仅可以作为栈使用,也可以作为队列使用。
LinkedList实现类
LinkedList是List接口的实现类,意味着它是一个List集合,可以根据索引来随机访问集合中的元素,除此之外LinkedList还实现了Deque接口,可以被当成双端队列来使用,因此既可以作为栈使用,也可以作为队列使用。
LinkedList插入、删除元素时性能出色,随机访问集合元素时性能较差。
增强的Map集合
Map用于保存具有映射关系的数据,一组值保存Map里的key,另一组值用于保存Map里的value,key和value可以使任何引用类型的数据。Map的key不允许重复,即同一个Map对象的任何两个key通过equals方法比较总是返回false。
key和value存在单向一对一关系,即通过指定的key,总能找到唯一的、确定的value。如果把Map里所有的key放在一起就组成了一个Set集合,Map里也确实包含了一个keySet()方法,用于返回Map里所有key组成的Set集合。
Map中包括一个内部类Entry,该类封装了一个key-value对。Entry包含如下三个方法:
1.Object getKey():返回该Entry里包含的key值
2.Object getValue():返回该Entry里包含的value值。
3.Object setValue(V value):设置该Entry里包含的value值,并返回新设置的value值。
改进的HashMap和Hashtable实现类
Hashtable和HashMap存在两点典型区别:
1.Hashtable是一个线程安全的Map实现,但HashMap是线程不安全的实现,所以HashMap比Hashtable的性能高一点;但如果有多个线程访问同一个Map对象时,使用Hashtable实现类会更好。
2.Hashtabl不允许使用null作为key和value,如果试图把null值放进Hashtable中,将会引发空指针异常,但HashMap可以使用null作为key或value。
由于HashMap里的key不能重复,所以HashMap里最多只有一个key-value对的key为null,但可以有无数多个key-value对的value为null。
HashMap、Hashtable判断两个key相等的标准也是通过equals()方法比较返回true,两个key的hashCode值也相等。
判断两个value是否相等,直接通过equals()方法比较返回true即可。
LinkedHashMap实现类
LinkedHashMap使用双向链表来维护key-value对的顺序(其实只需要考虑key的顺序)该链表负责维护Map的迭代顺序,迭代顺序与key-value对的插入顺序保持一致。只要插入时保持顺序,便可以避免使用TreeMap所增加的成本,迭代输出LinkedHashMap时,将会按照添加时的顺序输出。
使用Properties读写属性文件
Properties相当于一个key、value都是String类型的Map。
但是不保证key-value对之间的次序。
提供方法:
void load(InputStream inStream):从属性文件(以输入流表示)中加载key-value对,把加载到的key-value对追加到Properties里
void store(OutputStream out,String comments):将Properties中的
key-value对输出到指定的属性文件(以输出流表示)中
PS :Properties可以把key-value对以XML文件的形式保存起来,也可以从XML文件中读取。
SortedMap接口和TreeMap实现类
正如Set接口派生出SortedSet子接口,SortedSet接口有一个TreeSet实现类一样,Map接口也派生出一个SortedMap子接口,SortedMap接口有一个TreeMap实现类。
TreeMap就是一个红黑树数据结构,每个key-value对即作为红黑树的一个节点。TreeMap存储key-value对时,需要根据key对节点进行排序,TreeMap可以保证所有的key-value对处于有序状态。
两种排序方式:
1.自然排序:TreeMap的所有key必须实现Comparable接口,而且所有的key应该是同一个类的对象,否则将会抛出ClassCastException异常。
2.定制排序:创建TreeMap时,传入一个Comaparator对象,该对象负责对TreeMap中的所有key进行排序,采用定制排序时不要求Map的key实现Comparable接口。
类似于TreeSet中判断两个元素相等的标准,TreeMap中判断两个key相等的标准是:两个key通过compareTo()方法返回0,TreeMap即认为这两个key是相等的。
如果使用自定义类作为TreeMap的key,且让TreeMap良好的工作,则重写该类的equals()方法和compareTo()方法应该保持一致的返回结果。
PS :Set和Map的关系十分密切,java源码就是先实现了HashMap、TreeMap等集合,然后通过包装一个所有的value都为空对象的Map集合实现了Set集合。
WeakHashMap实现类
WeakHashMap与HashMap的用法基本相似,区别在于,HashMap的key保留了对实际对象的强引用,意味着只要该HashMap对象不被销毁,该HashMap的所有key所引用的对象就不会被垃圾回收,HashMap也不会自动删除这些key所对应的key-value对;但WeakHashMap的key只保留了对实际对象的若阴影,如果WeakHashMap对象的key所引用的对象没有被其他强引用边浪所引用,则这些key所引用的对象可能被垃圾回收,WeakHashMap也可能自动删除这些key所对应的
key-value对。
public class WeakHashMapTest{
public static void main(String[] args){
var whm = new WeakHashMap();
whm.put(new String("语文"),new String("良好"));
whm.put(new String("数学"),new String("及格"));
whm.put(new String("英语"),new String("优秀"));
whm.put("java",new String("良好"));
System.out.println(whm);
System.gc();
System.runFinalization();
System.out.println(whm);
}
}
WeakHashMap对象的第四个key-value对的key时一个字符串直接量,系统使用缓冲池保留对该字符串对象的强引用,所以垃圾回收时不会回收它。
IdentityHashMap实现类
实现机制与HashMap基本相似,但处理两个key相等时比较独特,在IdentityHashMap中,当且仅当两个key严格相等(key1 == key2)时,IdentityHashMap才认为两个key相等。
IdentityHashMap也允许使用null作为key和value,也不保证key-value对之间的顺序。
EnumMap实现类
EnumMap是一个与枚举类一起使用的Map实现,EnumMap中的所有key都必须是单个枚举类的枚举值。创建EnumMap是必须显示或隐式指定它对应的枚举类。
EnumMap具有如下特征:
1.EnumMap在内部以数组形式保存,所以这种实现形式非常紧凑、高效。
2.EnumMap根据key的自然顺序(即枚举值在枚举类中的定义顺序)来维护key-value对的顺序。
3.EnumMap不允许使用null作为key,但允许使用null作为value。
各Map实现类的性能分析
HashMap通常比Hashtable要快。
TreeMap通常比HashMap、Hashtable要慢(尤其在插入、删除key-value对时更慢),因为底层采用红黑树来管理key-value对(红黑树的每个节点就是一个key-value对)
如果程序总是需要一个排好序的Map时,考虑使用TreeMap。
一般的应用场景多考虑会用HashMap,因为HashMap是为快速查询设计的(底层是采用数组来存储key-value对)。
LinkedHashMap比HashMap慢一点,因为需要维护链表来保持Map中key-value对的添加顺序。
EnumMap的性能最好,但它只能使用同一个枚举类的枚举值作为key。
HashSet 和 HashMap的性能选项
hash表里可以存储元素的位置被称为“桶”,通常情况,单个“桶”里存储一个元素,此时有最好的性能,hash算法可以根据hashCode值计算出“桶”的存储位置,然后从“桶”中取出元素,发生“hash冲突”的情况下,单个“桶”会存储多个元素,这些元素以链表形式存储,必须按顺序搜索。
HashSet、HashMap的hash表包含如下属性:
容量(capacity):hash表中通的数量。
初始化容量(initial capacity):创建hash表时桶的数量,HashMap和HashSet都
允许在构造器中指定初始化容量。
尺寸(size):当前hash表中记录的数量。
负载因子(load factor):负载因子等于“size/capacity”,负载因子为0,表示空的hash表。0.5为半满。轻负载的hash表具有冲突少、适宜插入与查询的特点(但是使用Iterator迭代元素时较慢)。
hash表中还有一个“负载极限”,是一个0~1的数组,负载极限决定hash表的最大填满程度,当hash表中的负载因子达到指定的负载极限时,hash表会自动成倍的增加容量,并将原有的对象重新分配,放入新的桶内,这称为rehashing。
HashSet、HashMap、Hashtable默认的负载极限为0.75,达到时会进行rehashing。
根据数据量的需求来设定合理地初始化容量。
操作集合的工具类:Collections
排序操作:
void shuffle(List list):对List集合元素进行随机排序(模拟洗牌动作)
void rotate(List list,int distance):当distance为正数时,将list集合的后distance个元素整体移动到前面;当distance为负数时,将list集合的前distance个元素整体移动到后面,该方法不会改变集合的长度。
查找、替换操作:
int frequency(Collection c,Object o):返回指定集合中指定元素的出现次数。
同步控制:
提供多个synchronizedXxx()方法,可以将指定集合包装成线程同步的集合,从而可以解决多线程并发访问集合时的线程安全问题。
var m = Collections.synchronizedMap(new HashMap());
设置不可变集合:
Collections提供了如下三类方法来返回一个不可变的集合:
1.emptyXxx():返回一个空的、不可变的集合对象,可以是List也可以是SortedSet、Set、Map、SortedMap
2.singletonXxx():返回一个只包含指定对象(只有一个或一项元素)的不可变的集合对象,此处的集合既可以是List,还可以是Map。
3.unmodifiableXxx():返回指定集合对象的不可变视图,此处即可以是List、Set、SortedSet还可以是Map、SortedMap。
java9新增功能直接利用各集合的of()方法可以创建包含N个元素的不可变集合。
var map = Map.of(“java”,100,“Hadoop”,97);