一、增量导入
自动的概念
1.1定时的自动导入
1.1.1配置文件

Spring-task.xml
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:task="http://www.springframework.org/schema/task"
xsi:schemaLocation="http://www.springframework.org/schema/task http://www.springframework.org/schema/task/spring-task-4.3.xsd
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.3.xsd">
<!-- 开启定时任务的注解开发 -->
<task:annotation-driven/>
</beans>
1.1.2注解

1.2 实现增量导入
每次都是15 全部导入特别耗费性能(数据库的读取性能,solr的写入性能)
1.2.1 增量导入的原理

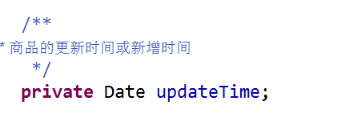
1.2.2 数据库给t_goods 添加一个字段

以后使用该字段记录商品的改变时间
修改完成后,重新生成domain 和mapper ,以及xml文件,导入
1.2.3 增量的实现
/**
* 起始时间
* 将起始时间设置为1970 ,怎意味着第一次导入是全部导入
* 以后这个起始时间总会让end时间来替换,它完成的就是增量导入
*/
private Date start = new Date(0);//1970 0 0 的时间
/**
* 从数据里面导入到solr 里面,要求:
* 第一次需要全部导入
* 后面都是增量的导入
* cron="" 使用cron 表达来决定该方法什么时候执行(通用性高,java,linux ,windows)
* initialDelay:项目初始化多少时间后执行
* fixedDelay:固定多少时间执行一次
*/
@Scheduled(initialDelay=10*1000,fixedDelay=15*1000)
public void import2Solr() {
System.out.println("开始执行定时任务");
// 第一步查询数据库的商品(分页导入)
// start+15min = t2 的时间,就是定时任务行后的时间
Date end = new Date(System.currentTimeMillis());
// 只需要判断,在start 时间和end 时间内的新增的数据,和修改的数量
GoodsExample goodsExample = new GoodsExample();
Criteria createCriteria = goodsExample.createCriteria();
createCriteria.andUpdateTimeBetween(start, end);
// 1 计算总页数
long total = goodsMapper.countByExample(goodsExample);//总条数
System.out.println("本次需要导入"+total+"条");
long totalPage = total % pageSize == 0?total / pageSize: (total / pageSize +1);
for (int i = 1; i <= totalPage; i++) {
PageHelper.startPage(i,pageSize); // 不涉及增量导入
List<Goods> goods = goodsMapper.selectByExample(goodsExample); // 全部查询时不行的,因为数据量太大,导致可以导入失败,我们可以把数据库的数据分批导入(数据库的分页查询)
List<SolrInputDocument> docs = goods2Docs(goods);
try {
solrServer.add(docs);
solrServer.commit();
System.out.println("第"+i+"导入完成");
} catch (SolrServerException e) {
e.printStackTrace();
System.out.println("第"+i+"导入完成");
} catch (IOException e) {
e.printStackTrace();
System.out.println("第"+i+"导入完成");
}
}
// start 和end 的时刻内新增的数据和修改的数据导入完成,等待下一轮导入
start = end ; // 做一个时间的推移
}
二、搜索
2.1 分页
/**
* 分页搜索
*/
@Override
public List<Goods> query(String keyword, int page, int size) {
Assert.notNull(keyword, "搜索时关键字不能为null");
String q = "goods_name:"+keyword; // goods_name:*
SolrQuery solrQuery = new SolrQuery(q); // 关键字查询
//1 分页查询 limt start,rows
solrQuery.setStart((page-1)*size);
solrQuery.setRows(size);
List<Goods> goodsList = new ArrayList<Goods>() ;
try {
QueryResponse query = solrServer.query(solrQuery);
SolrDocumentList results = query.getResults();
for (SolrDocument solrDocument : results) {
Goods goods = doc2Goods(solrDocument);
goodsList.add(goods);
}
} catch (SolrServerException e) {
e.printStackTrace();
}
return goodsList;
}
/**
* 将solr的文档对象转换为goods 对象
* @param solrDocument
* @return
*/
private Goods doc2Goods(SolrDocument solrDocument) {
Goods goods = new Goods();
Object id = solrDocument.getFieldValue("id");// 通过字段的名称得到字段的值
goods.setId(Integer.valueOf(id.toString()));
Object goodsName = solrDocument.getFieldValue("goods_name");
goods.setGoodsName(goodsName.toString());
Object goodsImg = solrDocument.getFieldValue("goods_img");
goods.setGoodsImg(goodsImg.toString());
Object goodsPrice= solrDocument.getFieldValue("goods_price");
// BigDecimal
goods.setGoodsPrice(new BigDecimal(goodsPrice.toString()));
Object goodsCommentNun = solrDocument.getFieldValue("goods_comment_num");
goods.setGoodsCommentNum(Integer.valueOf(goodsCommentNun.toString()));
return goods;
}
2.2 排序
2.2.1 修改接口

2.2.2 实现类

2.3 高亮
2.3.1 概念
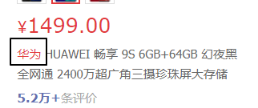
在网页上使用颜色,字体大小来突出显示
<font color=’red’>华为</font>
2.3.2 高亮的实现
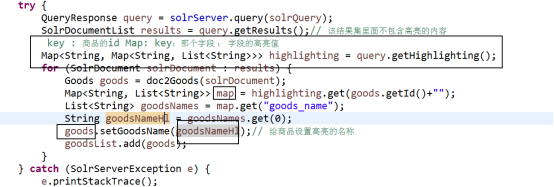
1 设置高亮
// 3 高亮设置
solrQuery.setHighlight(true);
solrQuery.setHighlightSimplePre("<font color='red'>");
solrQuery.setHighlightSimplePost("</font>");
solrQuery.addHighlightField("goods_name");
2 处理高亮的内容
2.4 过滤查询
2.4.1 概念
从查询的结果里面取出一些特定的值
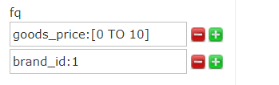
价格区间 999-1500
那种特定属性的值 我买的内存是4GB
2.4.2 区间查询
// 过滤查询
if(priceScope!=null&&priceScope.contains("-")) {
String[] split = priceScope.split("-");
float minPrice = Float.valueOf(split[0]);
float maxPrice = Float.valueOf(split[1]);
solrQuery.addFilterQuery("goods_price:["+minPrice+" TO "+ maxPrice+"]");
//1000-2000 goods_price[1000 TO 2000]
}
2.4.3 匹配

三、Solr集群的搭建
3.1 集群原理

3.2 规划
机器编号 ip 端口
1 192.168.231.143 8080
2 192.168.231.143 8081
3 192.168.231.143 8082
4 192.168.231.143 8083
3.3 搭建过程
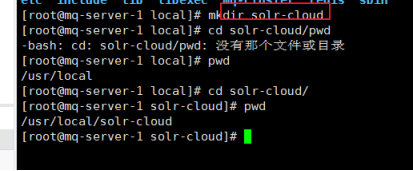
3.3.1 新建文件夹
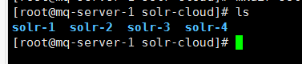
3.3.2 复制4份solr 进来


3.3.3 准备4个solr-home
A: 准备文件夹
新建一个solr-cloud-home的文件夹
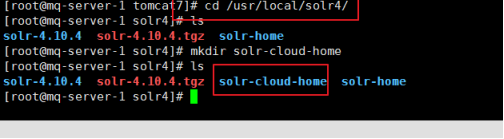
新建4 个solr home

B:给solr-home复制配置文件
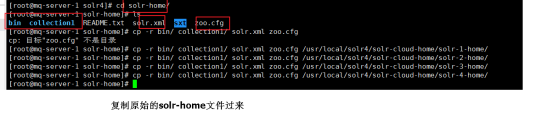
3.3.4 给每个solr 配置solr-home
vi /usr/local/solr-cloud/solr-[1:4]/apache-tomcat-7.0.92/webapps/solr/WEB-INF/web.xml
Solr1:

Solr2:

Solr3:

Solr4:

3.3.5 修改tomcat的端口
只修改8080 还不行,因为还有占用别的端口
server.xml 只有见到端口+10
Solr1: 不改变
Solr2: 端口统统+10
Solr3:端口统统+20
Solr4:端口统统+30
3.3.6 使用zk 做配置文件中心
上传配置文件


A: 启动zk 集群
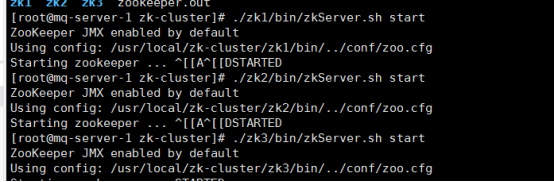
B:上传到zk 集群里面


./zkcli.sh -zkhost 192.168.231.143:2181,192.168.231.143:2182,192.168.231.143:2183 -cmd upconfig -confdir /usr/local/solr4/solr-home/collection1/conf -confname myconf

上传成功后的zk数据

3.3.7 solr启动下载配置文件
在solr 启动时,加上一个参数
zkHost=””,若solr 里面发现有这个地址,则去下载该zkHost 里面下载配置文件
JAVA_OPTS=”-D名称=值” 这样tomcat或java启动时,就可以把该参数传递进去
在tomcat 里面有个catalina.sh: 启动tomcat的文件
./startup.sh = catalina.sh run
我们需要修改catalina.sh 文件,添加JAVA_OPTS=”-D”
搜索该项: /JAVA_OPTS 使用n 代表往下搜索

修改为:

Solr1-4 都需要修改
复制solr1 里面catalina.sh 到(2,3,4 里面)

检查

3.3.8修改solr.xml 配置
solr-cloud-home里面
Solr-1-home:
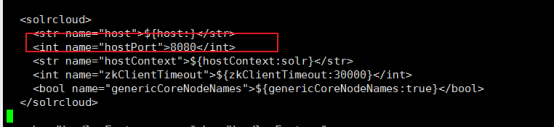
Solr-2-home:
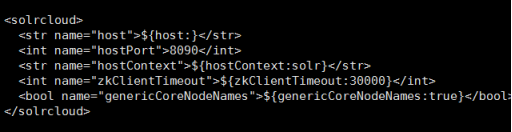
Solr-3-home:
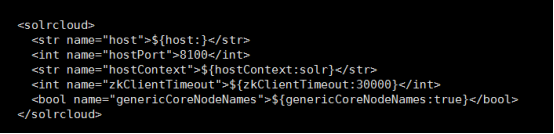
Solr-4-home:
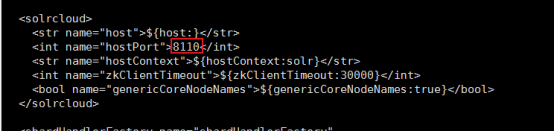
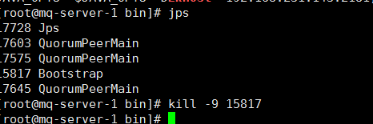
3.3.9 启动4 台solr
停止单机版的solr

3.3.10 在页面创建solr-core
执行:
http://ip:port/solr/admin/collections?action=CREATE&name=collection2&numShards=2&replicationFactor=2

3.3.11 删除不用的solr-core
http://ip:port/solr/admin/collections?action=DELETE&name=collection
http://192.168.231.143:8080/solr/admin/collections?action=DELETE&name=collection1

四、solr集群的使用
4.1 使用solr集群

String zkHost = "192.168.231.143:2181,192.168.231.143:2182,192.168.231.143:2183";
CloudSolrServer cloudSolrServer = new CloudSolrServer(zkHost );
cloudSolrServer.setDefaultCollection("sxt");
4.2 原理分析

路由规则
SolrCloud中对于文档分布在哪个shard上,提供了两种路由算法:compositeId和implicit
在创建Collection时,需要通过router.name指定路由策略,默认为compositeId路由。
compositeId
该路由为一致性哈希路由,shards的哈希范围从80000000~7fffffff。初始创建collection是必须指定numShards个数,compositeId路由算法根据numShards的个数,计算出每个shard的哈希范围,因此路由策略不可以扩展shard。
implicit
该路由方式指定索引具体落在路由到哪个Shard,这与compositeId路由方式索引可均匀分布在每个shard上不同。同时只有在implicit路由策略下才可创建shard。
doc.addField(“route”, “shard_X”);
一般是使用compositeId算法来实现
4.3 使用solr-cloud 来完成对商品的搜索
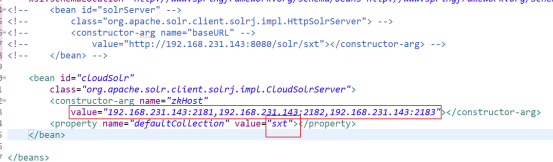


我们发现我们复制的solr 里面已经有ik分词器了,我们只要想办法改scheam.xml(zk) 就可以
我们只需要将改好的solr-home/sxt/conf文件夹上传一次就OK了
./zkcli.sh -zkhost 192.168.231.143:2181,192.168.231.143:2182,192.168.231.143:2183 -cmd upconfig -confdir /usr/local/solr4/solr-home/sxt/conf -confname myconf

上传成功后,重启solr 集群